SPEECH-TO-MUSIC RETRIEVAL USING EMOTION SIMILARITY 논문 리뷰
목표
: 감정 레이블을 통해 음성과 음악 간의 차이를 연결하는 cross domain retrieval system을 통해
"음성에서 보이는 감정에 맞는 음악을 추천"**
1. intro
cross domain retrieval system의 일반적인 접근:
"Mulitmodal representation learning"
->서로 다른 모달리티의 데이터를 공동임베딩 공간으로 변환
(unsuper vised, pairwise-based, rank-based, supervised methods등의 방법들이 있음)
문제:
음성-음악의 유기적 데이터셋이 존재하지 않음.
(음성과 음악은 자연스럽게 함께 발생하지 않기 때문)
해결책:
음성과 음악, 각각의 데이터셋에서 각 레이블 들간의 관계를 이용한 supervised learning
- 음성의 레이블(감정)과 음악의 레이블(감정) 사이 관계를 정답으로 두고 배우도록 시킴
- 기본적인 리트리버(retrieval) 테스크는 Unsupervised Learning,Self-supervised Learning
-> 문제: 그러나 각 도메인 사이 감정 어휘의 불일치가 존재!
-> 해결책: 감정기반맵핑(emotion-based mapping):
음성데이터셋의 감정 태그를 음악 데이터셋의 감정태그 중 가장 유사한 감정 태그로 변환
앞선 논문에서 제시된 방법(3)
- valence-arousal(긍/부정-정도) 공간에서의 유클리드 거리
- 단어 임베딩 공간에서 코사인 거리
- 수동 매핑
부족한 점) 결국 매핑이 이산적으로 이뤄져 연속적인 감정 분포 정보를 놓칠 수 있다.
-> 논문에선 감정 유사성 정규화 항(emotion similarity regularization term) 이용해 연속적인 감정 유사성 정보도 활용함
2.SPEECH-TO-MUSIC RETRIEVAL
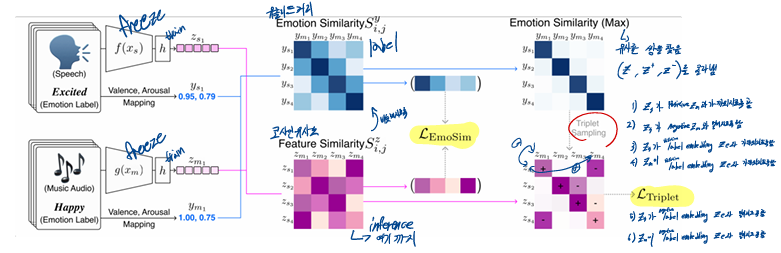
2.1 Encoder for feature extraction (모델 구조)
-
두 부분으로 이뤄짐
- pretrained encoder : 데이터 특징을 추출
- projection MLPs(투영 다층 퍼셉트론) : 각 특징을 공동 임베딩 공간으로 변환
(추후 코드를 통해 더 자세히 확인)
-
pretrained encoder
- speech encoder : Wav2vec 2.0
- music encoder : Music Tagging Transformer
이때 음소 수준의 특징을 발화 수준으로 요약하기 위해 평균 풀링을 사용 - DistilBERT : speech 대신 텍스트 사용 시
- VAD Lexicon: label을 valence-arousal로 나타내기 위해
VAD Lexicon
VAD Lexicon은 감정 레이블을 Valence(밸런스), Arousal(각성), Dominance(지배력) 세 가지 차원으로 표현하는 사전
encoder는 freeze, MLPs만 학습
2.2 Cross domain retrieval (전체 구조)
triplet loss를 사용한 deep metric learning
- ,
: 각각 음성 피쳐와 음악 피쳐: 음성 데이터, 음성 감정 레이블
: 음악 데이터, 음악 감정 레이블
: pretrained encoder(음성, 음악)
: projection MLPs(음성, 음악)
- triplet loss
triplet loss
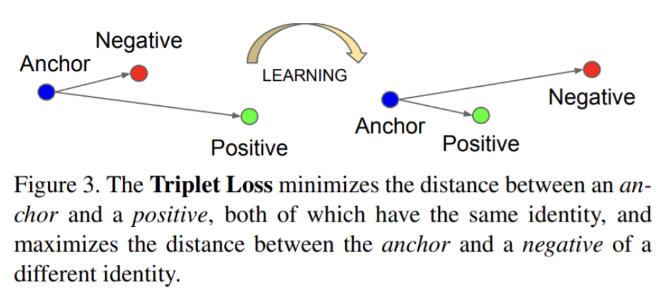
- 동일한 의미를 가지는 와는 가깝게, 다른 의미를 가지는 와는 멀게
- 가 주어졌을 때
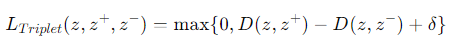
- δ는 사이 거리 (margin)
-
논문은 를 anchor로 와 를 두고 loss를 정의
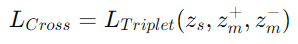
-> 이때 triplet sampling을 사용음성과 음악 사이 유클리드 거리
코사인 유사도
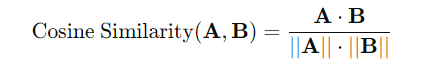
유클리드 거리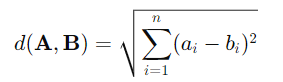
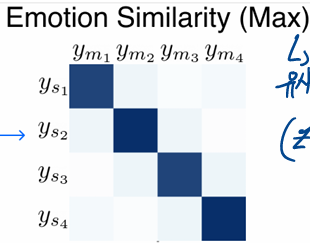
triplet sampling
-> 음성과 음악의 valence-arousal 들 사이 유클리드 거리를 계산
-> max화 함
-> 거기서 각 앵커마다의 긍정 부정샘플을 찾아옴
2.
-
문제)
triplet loss는 모달리티 내(음성,음악 각각의)데이터 분포나 이웃된 구조를 고려하지 않음.
즉, 각 데이터 항목들과 감정 태그 간의 관계가 고려되지 않음 -
해결)
구조 보존 제약(Structure-preserving constraints)을 사용
: 감정-음성과 감정-음악 간의 삼중항 손실을 최적화
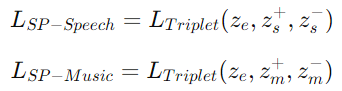
: 감정 태그의 임베딩
GloVe 사전 학습된 단어 임베딩 과 projection MLP 사용
: 감정에 해당되는 음성/음악 데이터(데이터-레이블 형태로 이미 지정됨)
: 감정과 다른 음성/음악 데이터(와 감정적으로 가장 먼 )
-
- 최종 Loss
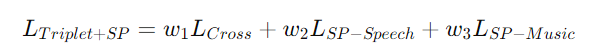
- 최종 Loss
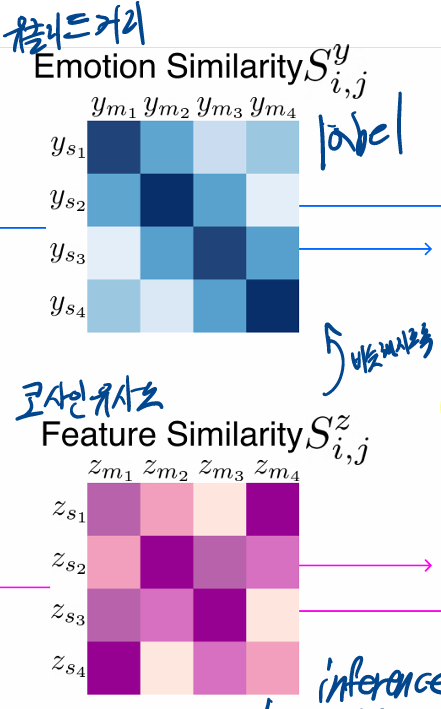
2.3 Emosim(emotion similarity regulation)
깊은 불균형 회귀 작업(deep imbalanced regression task) 에 쓰이는 순위 유사성 정규화(RankSim)을 채택
수정된 버전인 emotion similarity regulation(Emosim)를 제안
순위를 계산하는 대신, 우리는 두 유사성 점수 간의 차이를 직접 계산
-
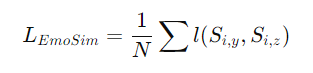
- : 감정 공간에서의 i번째 음성/음악 항목의 이웃 간 유사성
- : 특징 공간에서의 i번째 음성/음악 항목의 이웃 간 유사성
- : 평균제곱오차(MSE)
- : 미니배치 크기
-
목표: 이 과 같아지도록 학습
-
최종
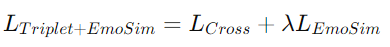
- : 이산적인 감정 매핑(Triplet)과 연속적인 감정 분포 매핑(Valence-Arousal 차원에서 유클리드 거리 계산을 통한 유사도)사이의 균형을 조절
-> 0.5로 설정 - 는 포함?X
- : 이산적인 감정 매핑(Triplet)과 연속적인 감정 분포 매핑(Valence-Arousal 차원에서 유클리드 거리 계산을 통한 유사도)사이의 균형을 조절
-
훈련 시
고유한 유사성 점수 사용 & 드문 레이블의 상대적 표현 강화
-> 한번 나왔던(이미학습된) 감정 쌍에 해당하는 데이터 쌍은 버림(?)
-> 드물게 등장하는 감정 레이블은 더 강화
훈련 과정 정리)
- 음성, 음악 데이터를 pretrained encoder에 넣어 피쳐 추출
- 두 피쳐를 각 MLP에 통과시켜 같은 임베딩 공간에 넣음(how?)
- 이 두 피쳐 사이 코사인 유사도를 구함
+)원래같으면 이 코사인 유사도를 짝지어진 데이터에 맞도록 하는 방향으로 학습했을텐데 얘네는 일단 짝지어진 하나의 데이터셋이 아니라 서로 다른 감정 태그를 갖고 있음. - 각 데이터의 감정 태그(label)을 valance-Arousal로 수치화 함
- 이걸 이용해 두 감정태그 사이 유클리드 거리를 구함
- 그렇게 나온 두 데이터 사이 관계를 정답으로 두고 앞서 피쳐간 코사인 유사도를 맞춰감
- triplet loss를 이용해 음성과 음악 간의 감정적 유사성을 반영하는 임베딩 공간을 추가적으로 학습
이때는 좀더 명확한 답이 존재(긍정=답, 부정=오답)
inference 시)
input: 새로운 오디오
output: 기존의 music
입력된 오디오와 가지고 있는 음악 사이 코사인 유사도를 출력해 가장 가까운 걸 추천함
3. 실험 설계(Experimental Design)
음성 및 음악 데이터셋, 평가 지표, 훈련 세부 사항
3.1. 음성 데이터셋(Speech Datasets)
다양한 유형의 음성 데이터셋을 사용
- IEMOCAP:
- 데이터 구성: 약 12시간 분량의 음성 데이터를 포함하며, 10명의 화자가 5세션에 걸쳐 녹음했습니다. 각 세션마다 다중 감정 상태의 대화 데이터를 포함합니다.
- 감정 클래스: 6개의 감정 클래스로 구분(예: 행복, 슬픔, 화남 등).
- 훈련/테스트 분할: 첫 4개의 세션을 훈련에 사용하고, 마지막 5번째 세션을 테스트에 사용했습니다. 훈련 데이터의 10%는 검증 세트로 할당했습니다.
- 특징: 이 데이터셋은 연기된 감정(acted emotions)을 포함하여 감정 인식 작업에 널리 사용되는 표준 데이터셋입니다.
- RAVDESS:
- 데이터 구성: 24명의 배우(남성 12명, 여성 12명)가 2개의 문장을 8가지 감정(예: 기쁨, 화남, 슬픔 등)으로 연기한 데이터셋입니다.
- 훈련/테스트 분할: 첫 20명의 배우 데이터를 훈련에 사용하고, 20-22번째 배우 데이터를 검증, 22-24번째 배우 데이터를 테스트에 사용했습니다.
- 특징: 다중 모달 감정 데이터셋으로, 음성뿐만 아니라 노래 및 다양한 감정 상태에서의 음성을 포함합니다.
- Hi,KIA:
- 데이터 구성: 4가지 감정 상태(화남, 행복, 슬픔, 중립)로 레이블이 지정된 짧은 길이의 wake-up word 데이터셋입니다.
- 특징: 8명의 한국인 화자에게서 수집된 488개의 발화 데이터로 구성되어 있습니다.
- 훈련/테스트 분할: 8개의 공식적인 분할 중, 인간 검증 성능이 가장 높은 분할(F7)을 사용하여 훈련 및 평가를 진행했습니다.
3.2. 음악 데이터셋(Music Datasets)
음악 데이터셋으로는 AudioSet의 하위 집합을 사용했습니다. 이 하위 집합은 감정적 분위기(music mood)에 맞추어 레이블이 지정된 7가지 감정 상태의 음악 클립을 포함합니다.
- AudioSet의 하위 집합
- 사용된 감정 클래스: 행복(happy), 재미있는(funny), 슬픈(sad), 부드러운(tender), 흥분되는(exciting), 화난(angry), 무서운(scary).
- 데이터 구성: AudioSet은 유튜브에서 수집된 10초 길이의 음악 클립을 포함하며, 13,295개의 음악 클립과 5,348개의 소음(color noise)을 포함한 총 18,643개의 클립을 훈련에 사용했습니다.
- 중립 감정 처리: 중립적인 감정 레이블이 존재하지 않기 때문에, 무작위로 생성된 소음을 중립 음성 쌍으로 간주했습니다.
- 테스트 세트: 405개의 클립(음악 345개, 소음 60개)으로 평가를 진행했습니다.
3.3. 평가 방법(Evaluation)
모델 성능 평가는 분류 정확도와 검색 모델 평가 지표를 사용했습니다:
- 분류 정확도:
모달리티별 분류 정확도는 음악 감정 인식과 음성 감정 인식 성능을 측정했습니다. 예를 들어, 음성 모달리티에서는 IEMOCAP 데이터에서 0.718의 정확도를 기록했습니다.- 검색 모델 평가 지표:
- Precision@5 (P@5)
: 쿼리된 음성과 감정적으로 유사한 상위 5개의 음악 중 관련 음악의 비율을 측정합니다.- Mean Reciprocal Rank (MRR)
: 첫 번째로 관련 있는 음악이 검색 결과에서 몇 번째로 위치했는지를 평가합니다.- nDCG@5 (Normalized Discounted Cumulative Gain)
: 감정적 유사성을 고려한 순위 기반 평가 지표로, 감정이 연속적 유사성을 가진다는 점을 반영합니다.
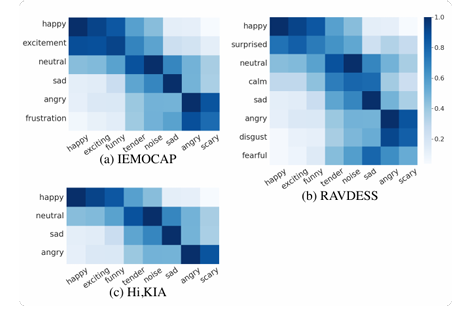
예를 들어, '부드러운(tender)'은 '슬픈(sad)'과 더 유사하고, '화난(angry)'과는 덜 유사하므로 이를 반영합니다.
평가 방식: 음성-음악 쌍 간의 예측 점수는 밸런스-각성(VA) 차원에서의 감정적 유사성을 기반으로 계산됩니다.
3.4. 훈련 세부 사항(Training Details)
- 음악 인코더 입력:
입력된 음악은 22,050 Hz로 샘플링된 10초 길이의 오디오 클립입니다.
이 오디오 클립은 128 멜 빈(mel bins)을 사용한 로그 스케일 멜 스펙트로그램으로 변환되며, 1024-point FFT, Hann 윈도우를 사용하고 512 hop size로 처리됩니다.- 음성 인코더 입력:
음성 인코더는 16,000 Hz 샘플링된 최대 16초 길이의 웨이브폼을 입력으로 받습니다.- 텍스트 인코더 입력:
텍스트 인코더는 최대 길이 64로 토크나이즈된 텍스트를 입력받습니다.- 최적화 기법:
AdamW 옵티마이저를 사용하며,- 배치 크기: 64.
- 학습률:
- 마진 값(triplet): 0.4**
4. 결과(Results)
정량적 결과는 감정 분류가 잘 되었나이고, 정성적 결과는 같은 공간에 관계를 반영한 임베딩이 잘되었나를 본 것
4.1. 정량적 결과(Quantitative Results)
"모델이 얼마나 정확하게 감정을 인식하고, 그 감정과 맞는 음악을 얼마나 잘 찾아냈는지를 수치적으로 평가"
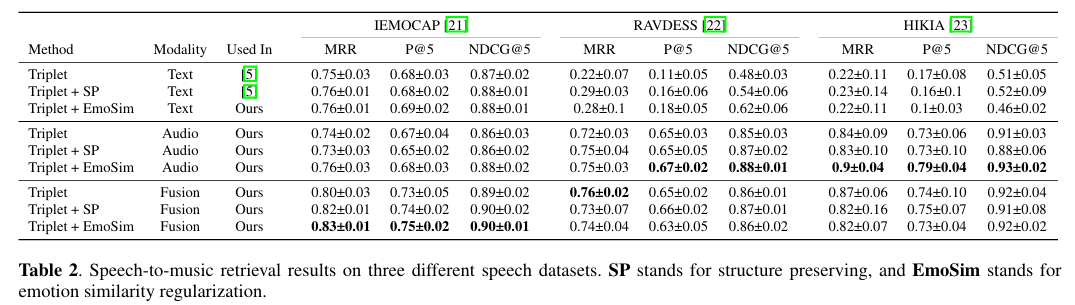
- 결론:
- 오디오 모달리티:
특히 음성 데이터와 그에 대응하는 텍스트(문자 정보)가 일치하는 음성 데이터셋(예: RAVDESS, Hi,KIA)에서 뛰어난 성능을 보이며,
텍스트 정보가 없는 IEMOCAP의 경우에도 높은 성능을 보여 오디오 특징만으로도 감정 인식에 충분한 정보를 제공할 수 있음을 보여줍니다. - 텍스트 모달리티:
언어적 단서가 많은 IEMOCAP에서 오디오와 비슷한 성능을 보여줬으며, 이는 언어적 정보의 감정 인식 중요성을 시사합니다. - 모달리티 융합(오디오&텍스트):
각각의 단일 모달리티보다 더 나은 성능을 보여주며, 상호작용이 잘 이루어진 융합 모델이 검색 성능을 높일 수 있음을 보여줍니다. - EmoSim 정규화:
모든 데이터셋과 모달리티에서 성능을 향상시키며, 특히 감정 유사성을 기반으로 더 나은 검색 결과를 제공합니다.
- 오디오 모달리티:
4.2. 정성적 결과(Qualitative Results)
"연속적인 감정 유사성이 잘 반영되어, 감정 간의 연관성이 임베딩 공간에서 잘 드러나는가."
UMAP (Uniform Manifold Approximation and Projection)을 사용해 학습된 임베딩 공간을 2D 공간으로 투영하여 시각화한 결과
UMAP
-> 음성 임베딩(별표)과 음악 임베딩(원형)이 감정에 따라 어떻게 클러스터링되는지
- 모든 모델이 감정 분류를 성공적으로 수행:
시각화된 결과에서 모든 모델이 감정적 의미(semantics)에 따라 데이터를 성공적으로 구분하는 것을 확인할 수 있습니다.
이는 음성과 음악이 감정적 유사성에 따라 임베딩 공간에서 잘 구분된다는 것을 시사합니다. - 감정의 연속적 분포 확인:
각 모델에서 감정의 연속적인 분포가 확인되었습니다. 예를 들어, 행복(happy), 흥분(excited), 부드러운(tender), 슬픔(sad) 감정들이 임베딩 공간에서 서로 가까운 위치에 분포합니다.
이는 감정들이 서로 연관성을 가지고 있음을 시각적으로 확인할 수 있는 부분입니다. - Triplet 모델의 한계:
기본 Triplet 모델에서 scary(무서운) 감정에 해당하는 음악 임베딩이 슬픔(sad)과 행복(happy) 클러스터 사이에 잘못 위치해 있었습니다.
이는 scary 감정이 임베딩 공간에서 적절한 위치에 배치되지 않았음을 보여줍니다.
Valence-Arousal 감정 공간에서 scary(무서운) 감정은 frustration(좌절)이나 angry(화남) 감정과 더 유사한데, Triplet 모델에서는 이를 제대로 반영하지 못했습니다. - Triplet + EmoSim 모델의 개선:
Triplet + EmoSim 모델에서는 이 문제가 완화되었습니다. scary(무서운) 음악 임베딩이 화남(angry) 및 좌절(frustration) 클러스터와 더 가까운 위치에 배치되었습니다.
->이는 EmoSim 정규화가 연속적인 감정 유사성을 학습하는 데 도움이 되었음을 의미.
(즉, 임베딩 공간에서 감정적 유사성을 더 잘 반영하는 구조를 학습하게 된 것)
#메모
해볼것
인코더 확장
감정맵핑에 임베딩을 사용해 코사인 유사도 적용
MSE 대신 다른 방법
=0.5인 이유
오디오+비디오 융합
triplet 대신 대조학습
Q. triplet +sp+emsiom은 왜 안했을까
SP(Structure-Preserving)와 EmoSim(Emotion Similarity Regularization)은 각각 임베딩 공간에서 감정적 유사성을 유지하고, 구조 보존 제약을 강화하는 정규화 방법입니다. 두 가지 모두 임베딩 공간에서 감정적으로 유사한 항목들이 더 가까워지도록 하는 목표를 가지고 있지만, 목표가 유사하다는 점에서 중복된 역할을 할 가능성
