논문 리뷰 : Live Music Models
Abstract & Intro
제안
-
새로운 음악 생성 모델: 저자들은 실시간으로 끊김 없이 음악을 생성하고, 사용자 제어에 동기화될 수 있는 Live Music Models라는 새로운 범주의 생성 모델을 제안한다.
Magenta RealTime:
- 오픈웨이트(open-weights) 모델.
- 텍스트나 오디오 프롬프트로 음향적 스타일을 제어할 수 있음.
- 자동 음악 품질 지표에서 다른 오픈웨이트 음악 생성 모델보다 우수하면서도 파라미터 수가 더 적음.
- 최초로 실시간 라이브 음악 생성 기능을 제공.
Lyria RealTime:
API 기반 모델로, 확장된 제어 기능과 넓은 프롬프트 커버리지 제공.연구 배경과 필요성 (Introduction)
- 음악의 두 가지 양식:
1. 정적(Static) 음악: 녹음된 완성된 곡, 즉 “music as a noun”.
2. 실시간(Real-time) 음악: 공연에서 실시간으로 함께 경험하는 “music as a verb” - 현황:
그러나 기존의 AI 음악 생성 모델은 대부분 오프라인, 턴 기반(offline, turn-based) 방식에 치중해 왔음.
라이브 음악 모델의 기술적 도전
- 기존 오프라인 생성:
사용자가 제어 정보를 입력하고, L초의 지연 후 T초 길이의 오디오를 받음. - 라이브 환경:
사용자가 지속적으로 제어 입력을 주면, 동일한 T초 동안 끊기지 않는 오디오 스트림을 받고, 제어 입력이 실제 오디오에 반영되기까지 D초의 지연만 허용.
-> 고품질 오디오 생성과 엄격한 동기화를 동시에 만족시켜야 하므로 어려운 문제.
Live Music Models의 정의와 기준
- 단순히 RTF(Real Time Factor) ≥ 1× (T초 오디오를 L ≤ T의 지연으로 생성)만으로는 부족.
- 라이브 음악 모델이라 부르기 위한 3가지 조건:
- 실시간 생성: RTF ≥ 1×.
- Causal Streaming: 오디오 출력이 과거 오디오와 사용자 입력만을 바탕으로 연속 생성.
- diffusion, Bidirectional Transformer 기반 LM(bert) 같은 모델이 non-causal
- Responsive Control: 낮은 지연 D로 실시간 상호작용이 가능.
2. Method
Magenta RT:
-
Codec Language Model 기반
-
사용자로부터 제공받은 음향 스타일 조건(acoustic style conditioning)을 바탕으로 실시간으로 고품질 스테레오 오디오를 생성하는 모델
-
이를 위해 파이프라인 방식을 채택:
Overall Architecture of Magenta RT
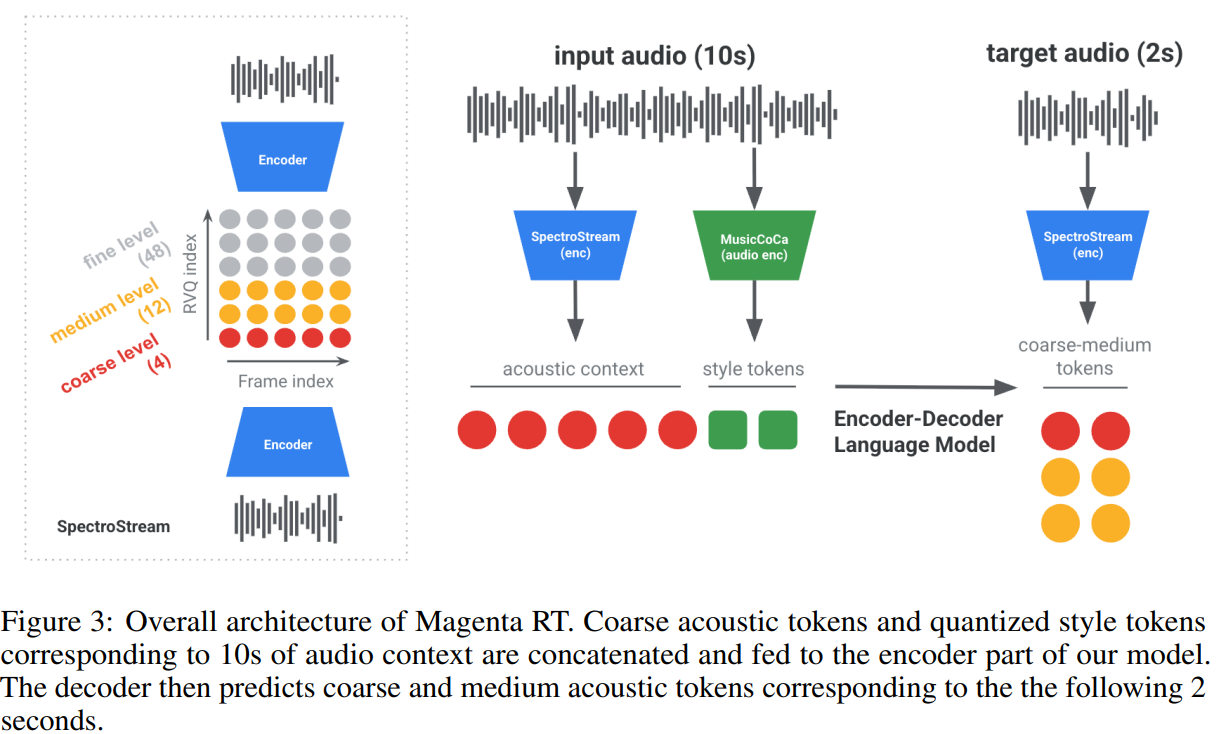
- SpectroStream 오디오 코덱으로 오디오를 토큰화,
- MusicCoCa에서 스타일 임베딩 추출,
- Encoder–Decoder Transformer가 이 토큰과 임베딩을 받아 오디오 토큰을 모델링.
2.1 Audio Tokenization via SpectroStream
SpectroStream은 고품질 오디오를 언어 토큰처럼 이산화해 실시간으로 처리할 수 있게 해주며, Magenta RT는 이를 통해 라이브 음악 생성의 핵심 기반을 구축
1. Codec Language Modeling
-
오디오를 언어와 유사한 토큰 시퀀스로 변환해 모델이 예측하도록 만드는 기법.
-
코덱(codec):
-
Encoder (Enc):
원본 스테레오 오디오 → 압축된 토큰 시퀀스 로 변환- : 오디오 길이(초),
- : 샘플링 레이트,
- : 토큰 프레임 레이트,
- : RVQ depth,
- : 토큰 vocabulary.
- : 오디오 길이(초),
-
Decoder (Dec ≊ Enc⁻¹):
토큰 → 원래 오디오로 복원, 지각적 손실을 최소화.
-
-
SpectroStream
- 48 kHz 풀밴드 스테레오를 처리하는 신경망 오디오 코덱.
- Residual Vector Quantization (RVQ) [27] 기반.
기본 사양:
- 전체 bandwidth(대역폭): 16 kbps(25x64x10),
- 토큰 프레임 레이트
- : 25 Hz,
- RVQ depth : 64,
- 코드북 크기 : 1024().
실시간 스트리밍을 위해 대역폭 축소:
- 첫 16개 RVQ level(coarse & medium)만 생성,
- 목표: 4 kbps, 초당 약 400 토큰 처리.
2.2 Style embeddings via MusicCoCa
목적
- 오디오·텍스트 공동 임베딩을 만들어 음악의 전반적 스타일을 제어하는 컨트롤 신호로 사용.
- 다양한 텍스트 설명으로 주석된 음악 데이터를 학습하여, 텍스트가 담고 있는 장르·무드·악기 구성 등 고수준 음악적 특성을 “style”로 정의
모델 구조
-
기반 모델
MuLan [28] + CoCa [29] 아이디어를 결합한 Contrastive Captioner(CoCa) 구조.CoCa architecture
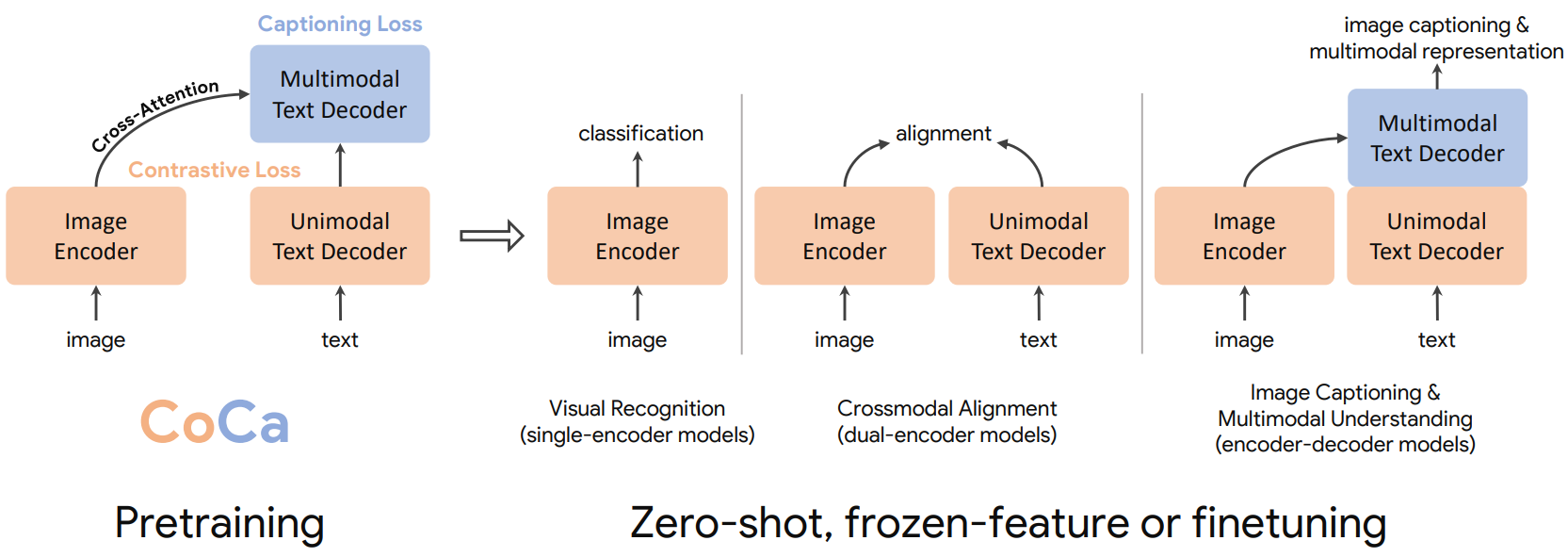
Music CoCa architecture
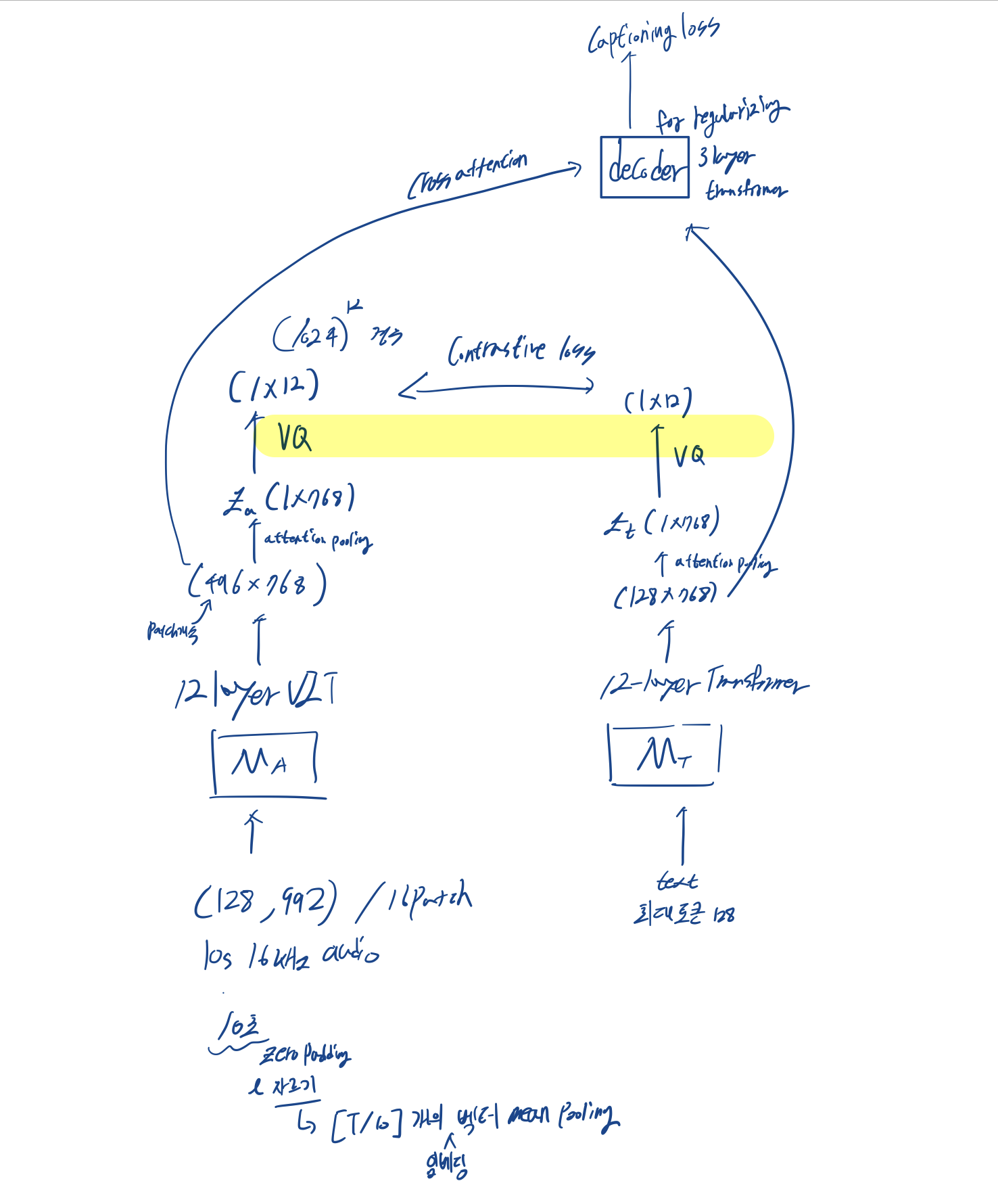
- 두 개의 임베딩 타워
- 오디오 타워(MA):
- 12-layer Vision Transformer(ViT) [30].
- 입력: 16 kHz 오디오 10초 구간 → log-mel spectrogram (128채널, 길이 992).
- 오디오 길이가 T초라면 10초 단위로 0-padding 후 ⌈T/10⌉ 청크의 임베딩을 평균(mean pooling)해 변동 길이를 처리.
- eg) 17초 -> 10초 하나, 7초+3 zero padding -> embedding 2개 mean pooling
- 16×16 patch로 나눠 처리.
- 텍스트 타워(MT):
- 12-layer Transformer.
- 최대 128 토큰의 텍스트 시퀀스를 처리.
- 공동 임베딩 공간
- 두 타워 모두 768차원 임베딩으로 매핑.
- Attention pooling으로 한 개의 768d 벡터 추출.
- 이후 12개의 이산 토큰으로 양자화(codebook 크기 |Vₘ|=1024).
- 오디오 타워(MA):
- 이후, LM 인코더로 전달
- 이렇게 얻은 토큰화된 오디오·텍스트 임베딩이 Magenta RT의 스타일 컨디셔닝 신호로 사용됨.
- 두 개의 임베딩 타워
- 추가 구성
- 텍스트 디코더: 얕은 3-layer Transformer.
- 실제 캡션 생성을 위한 것이 아니라 모델을 정규화(regularization) 하기 위해 사용.
WHY
- loss weigt 낮게하면 되는거 아닌가?
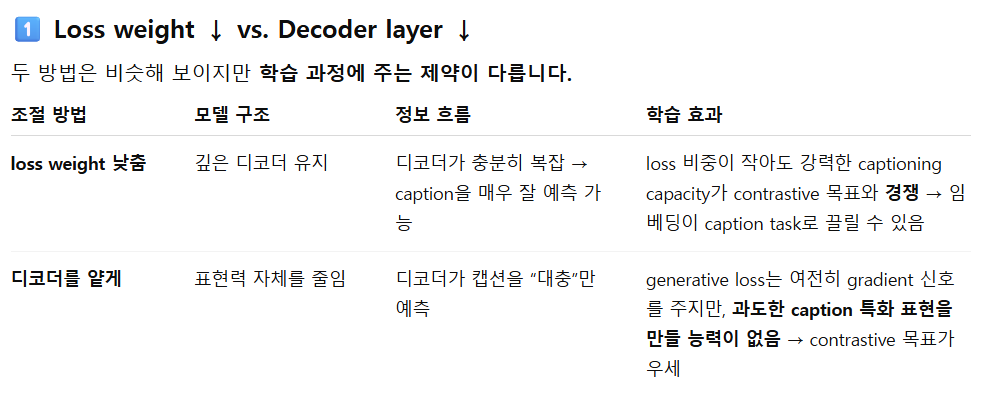
- 즉, loss weight만 낮추면 디코더는 여전히 caption을 잘할 capacity가 있어서 임베딩을 caption쪽으로 과적합시킬 수 있지만,
얕은 디코더는 애초에 표현력이 제한되어 ‘규제 신호’ 역할만 하게 된다
- 즉, loss weight만 낮추면 디코더는 여전히 caption을 잘할 capacity가 있어서 임베딩을 caption쪽으로 과적합시킬 수 있지만,
- 깊은 디코더와 얕은 디코더가 실제 학습때 무엇이 다른가
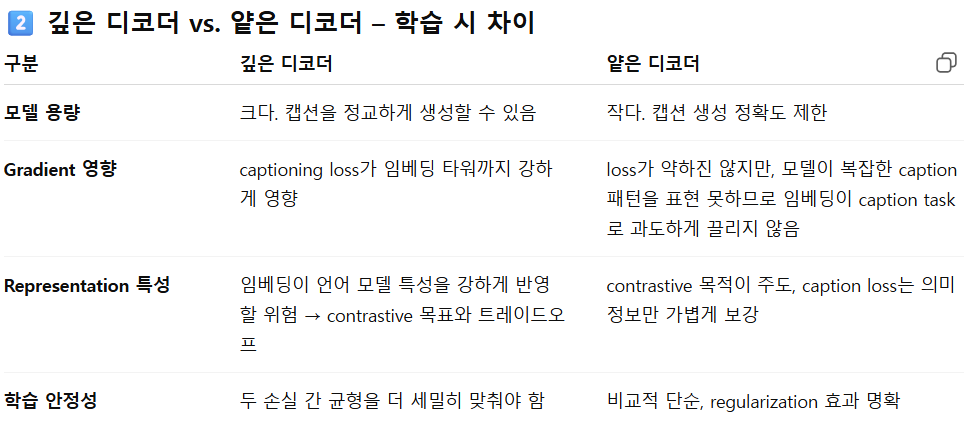
- 얕은 디코더 → 디코더가 복잡한 문장 생성을 잘 못하니
captioning loss를 줄이려면 임베딩 타워가 더 풍부한 의미 표현을 제공해야 함,
하지만 디코더 한계 때문에 “caption 전용 편향”이 강해지지는 않음.
즉, loss는 그대로지만 표현 압박이 완만하게 걸려 regularization 효과만 주게 됨
- 얕은 디코더 → 디코더가 복잡한 문장 생성을 잘 못하니
- loss weigt 낮게하면 되는거 아닌가?
- 학습 세부 사항
- Loss: CoCa 방식 – Contrastive loss와 Generative loss를 동일 가중치로 합산.
- Optimizer: Adafactor
- Learning rate: 1 × 10⁻⁴
- Warmup: 1,000 step
- 총 학습 스텝: 16,000
- Batch size: 1024
2.3 Modeling Framework
-
Magenta RT
- discrete audio tokens을 이용한 오토리그레시브(autoregressive) 언어 모델
- 이전 오디오 토큰과 a shared audio-text embedding(MusicCoCa)을 condition으로 다음 오디오 토큰을 예측
- 기본 아이디어는 MusicLM(AudioLM 기반)과 유사
-
live streaming을 위한 two high level changes
- multi lm -> single LM
= coarse/fine 단계(hierarchical cascade LM)로 나누지 않고, 25 Hz 프레임에서 곧바로 스트리밍 가능한 오디오 토큰을 생성. - chunk based autoregeression을 도입
-> 무한 스트리밍(infinite streaming) 가능
- multi lm -> single LM
-
Train & Infer
훈련 시 과정
- 타깃 오디오 a를 두 갈래로 보냅니다.
- SpectroStream Enc(a) → RVQ based discrete audio token (모델이 “예측해야 할 답”)
- MusicCoCa Mₐ(a) → 768차원 스타일 임베딩 (조건 입력)
- Transformer LM
입력: 이전까지의 오디오 토큰 + 스타일 임베딩
목표: 다음 오디오 토큰의 확률 을 최대화.
loss: cross-entropy로 “실제 오디오 토큰 시퀀스”를 예측하도록 모델을 학습.
추론(생성) 시
- 텍스트·오디오 프롬프트로 얻은 스타일 임베딩 c만 제공.
- Transformer LM이 오디오 토큰 시퀀스를 autoregressive하게 오디오 토큰 샘플링.
-> - SpectroStream 디코더 가 그 토큰을 실제 48 kHz 오디오 파형 으로 복원.
->
2.3.1 Chunk-based autoregression with coarse context
목표
- RTF ≥ 1×(실시간 이상 속도)로 끊김 없는 무한 스트리밍 오디오를 생성해야 함.
문제
"Infer때 live streaming하기 위해선 계속해서 긴 sequence를 생성해야 함"
- 학습 때와의 불일치(훈련 땐 제한된 길이의 token sequence만 봄)
-> 성능저하 - 메모리, 연산량 폭증
기존 해결법
“최근 W개의 토큰”만 보는 윈도우 어텐션을 두고, 위치를 절대값이 아니라 상대적 거리로 인코딩
제안1: Chunk-based autoregression
- C = 2초 길이의 오디오 토큰 묶음을 한 단위(chunk)로 다룸.
- H = 5개 이전 청크(총 10초)의 히스토리만 참고(마코프 가정).
제안 2: Coarse context 사용
- 목표 토큰: 전체 RVQ depth = 16(고해상도)로 예측해야 고음질 유지.
- 컨텍스트 히스토리:
첫 4개 RVQ 토큰(저해상도)만 사용해 이전 chunk 정보를 요약.
수식
- 청크 정의
오디오 a의 i번째 chunk(i~i+1 =2초)를 나타내는 16-depth RVQ 토큰 시퀀스.- Coarse context
10초 전부터 i까지 구간(5개 청크)에서 첫 4개 RVQ 토큰만 모은 것.- 모델링 목표
최근 5개 coarse 청크 + 현재 chunk의 스타일 임베딩 을 조건으로
i번째 chunk(전체 16-depth 토큰)을 예측.- condition token
최근 10초 단위로 얻은 MusicCoCa 임베딩 12 토큰
는 모두 같은 condition token =
장점:
- 오류 누적 감소
: 지나치게 긴 히스토리 없이 최근 10초만 고려
-> 더 오래된 오류는 다음 chunk 생성에 영향을 주지 않음.
(sliding attention에선 작은 토큰 오류가 계속 전달될 수 있음)- stateless inference
: 생성 캐시(cache)를 유지할 필요가 없음(각 chunk 독립적으로 유지) → 배포와 샘플링 단순화.
(sliding window 방식은 윈도우를 옮길 때마다 과거 토큰 캐시를 유지해야 함.)- 컨트롤 유연성
: 각 2초 chunk 생성 사이에 컨트롤(프롬프트·조건)을 쉽게 갱신 가능.
(sliding attention은 윈도우 전체 컨텍스트를 유지해야 하므로
컨트롤을 중간에 바꾸려면 더 복잡한 상태 관리가 필요.)- Coarse context로 충분한 스타일·구조 정보 유지하면서 계산량과 지연 감소.
2.4 Encoder-Decoder Language Model
전체 구조
- 모델 종류: Encoder–Decoder Transformer LM
- 학습 프레임워크: T5X [35,36]
- 공개 모델: T5 Base 및 T5 Large 설정으로 사전 학습된 모델 제공.
Encoder
- 역할: 과거 오디오 히스토리 + 스타일 컨트롤(스타일 임베딩)을 처리해
생성용 중간 표현(intermediate representation) 을 만든다.- 입력 토큰 (청크 i 기준):
- 토큰 수:
오디오 coarse context: = 4 × 2초 × 5 × 25Hz = 1000 토큰
스타일 토큰: 12개
총 1012 토큰 입력
공통 Vocabulary:
- : 특수 토큰
- : SpectroStream 오디오 토큰
- : MusicCoCa 스타일 토큰
- 인코더로 들어갈때: 공통 Vocabulary의 모든 토큰마다 하나의 학습 가능한 d차원 벡터를 갖고 토큰에 맞게 매칭
- decoder에서 생성할때: vocab안에서 각각의 확률값
Decoder
- 목표: RTF ≥ 1× (실시간 이상 속도로 라이브 생성)
- 기존 방법 한계:
- MusicLM: 다단계 hierarchical LM → 실시간 불가.
- MusicGen: delay pattern → RTF 1× 미만.
- Magenta RT의 해결책 ([23] 기반):
두 단계로 연결된 Transformer 모듈 사용:
- Temporal module
RVQ 토큰을 프레임 단위로 임베딩·집계 → 프레임 레벨 시계열 컨텍스트 생성.- Depth module
이 시계열 컨텍스트를 조건으로, 각 프레임의 RVQ 인덱스를 오토리그레시브하게 예측.- 성능:
T5 Large 구성에서 H100 GPU 기준 RTF = 1.8 달성
→ 실시간(≥1×)보다 빠르게 생성 가능.
encoder decoder code 잘 이해안됨

실험 setup 논문 참고
3.2 Results – 핵심 정리
3.2.1 Audio quality & Text prompt adherence (오디오 품질 및 텍스트 조건 충실도)
실험 설정
- 비교 대상: 기존 오프라인 text-to-music 모델 (예: Stable Audio Open 등)
- 조건: 텍스트 프롬프트를 고정하고, 연속적으로 청크를 생성하여 총 47초 길이의 오디오 생성.
평가 지표 (논문 [14]의 프로토콜 따름)
- FDopenl3 (Frechet Distance on OpenL3 embeddings) – 생성된 오디오의 자연스러움/현실성.
- KLpasst (Kullback–Leibler divergence) – 생성 오디오가 레퍼런스 오디오의 분포와 얼마나 일치하는지.
- CLAPscore – 텍스트 프롬프트와 생성 오디오 간의 텍스트 조건 일치도.
결과
- Magenta RT:
FDopenl3, KLpasst 모두 가장 낮음 → 생성된 오디오가 가장 자연스럽고 레퍼런스에 가깝다는 의미. - CLAPscore는 경쟁 모델(특히 Stable Audio Open)보다는 다소 낮음.
원인 추정: Stable Audio Open은 CLAP 임베딩을 학습 단계에서 직접 사용했지만,
Magenta RT는 MusicCoCa 임베딩을 사용.
3.2.2 Generating musical transitions (음악적 전환 생성)
실험 설정
- 목적: 사용자 입력(프롬프트)이 시간에 따라 변할 때 부드럽게 반응하는 능력 평가.
- 평가:
- 프롬프트 쌍 128개 선택.
- 시작과 끝 프롬프트의 MusicCoCa 텍스트 임베딩을
- 60초 동안 선형 보간(interpolation) (10초마다 1단계 → 총 6단계)으로 변화.
- 모델의 스타일 조건으로 이 보간된 임베딩을 입력.
- 출력 오디오 임베딩과 그 시점의 조건 임베딩 사이의 코사인 유사도 측정.
observation (Figure 2)
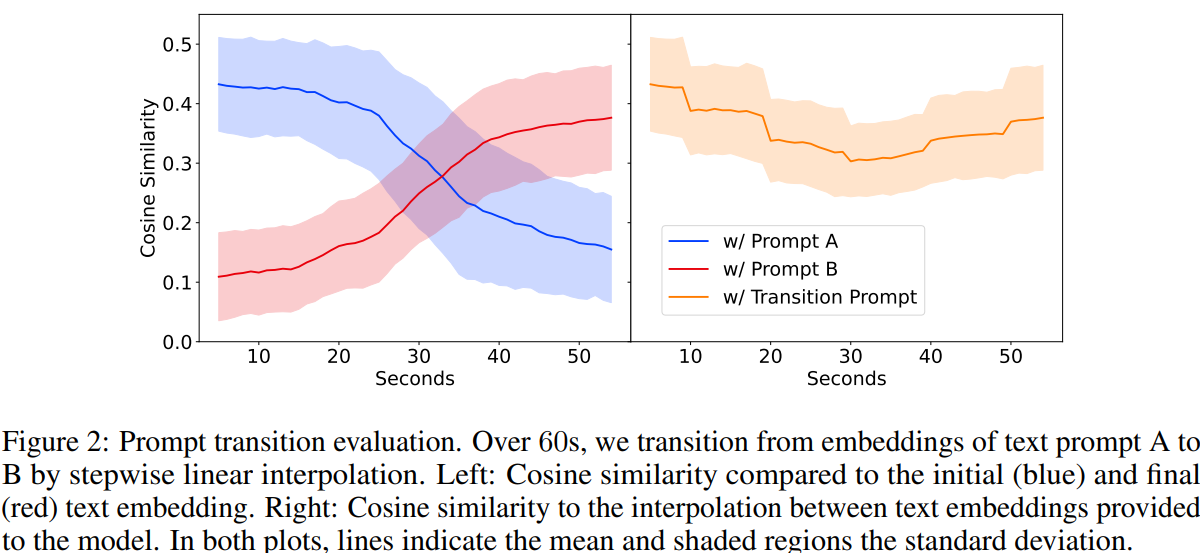
Magenta RT는 전환 과정에서 타깃 임베딩과 높은 유사도 유지.
- 시작 → 끝 프롬프트로 자연스럽게 음악 스타일이 변환.
- 전환 중간에 유사도가 약간 떨어지고, 마지막에도 시작 프롬프트의 요소가 남아 완벽히 바뀌진 않음.
- 하지만 이로 인해 음악이 끊김 없이 부드럽고 일관되게 진화하며,
- 프롬프트의 시간적 히스토리가 퍼포먼스에서 표현적 요소로 작용한다고 해석 가능.
4 Controllable Generation
4.1 Style Conditioning via Text and Audio (스타일 조건 제어)
핵심 아이디어
추론 시, MusicCoCa 임베딩 공간을 이용해 텍스트·오디오 프롬프트를 원하는 비율로 가중평균해 타깃 스타일 벡터 를 만든다.
i번째 텍스트/오디오 프롬프트의 MusicCoCa 임베딩
각 프롬프트에 부여한 가중치 (스타일 비율 제어)
장점
- 임베딩 산술(embedding arithmetic)
예: embed("techno") 0.5 + embed("flute") 0.5
→ embed("techno flute")와 비슷한 결과- 특정 개념들의 상대적 영향력을 비율로 조절 가능.
- 오디오 프롬프트 지원
- 텍스트로 표현하기 어려운 악기톤·연주 스타일을 직접 제시 가능.
- 학습 시에도 target audio로 style conditioning을 했으므로,
오디오 기반 prompting이 효과적.
- 텍스트+오디오 혼합 가능
- 여러 오디오 프롬프트를 섞어 스타일 간 부드러운 보간(interpolation) 가능.
- 텍스트·오디오 프롬프트를 혼합해 복합적 스타일 지정 가능.
결과적으로 장르, 스타일, 악기 편성, 분위기 등 고수준 특성을 직관적·연속적으로 제어할 수 있음.
4.2 Audio Injection (실시간 오디오 주입)
목적
실시간 공연 중 사용자가 입력하는 라이브 오디오로 모델의 생성 흐름을 계속 조정.(사용자의 연주를 가공해서 새로운 음악을 만드는 task)
메커니즘
-
사용자가 실시간으로 오디오 스트림 입력.
-
모델의 이전 출력 오디오와 사용자의 입력 오디오를 혼합(mix).
-
혼합된 오디오를 tokenize하여 다음 스텝의 컨텍스트로 사용.
➡️ 사용자 오디오는 직접 재생되지 않음(재창조됨).
모델이 이전 컨텍스트에 사용자 오디오가 포함된 것처럼 인식하고
그 뒤를 이어 음악을 생성.
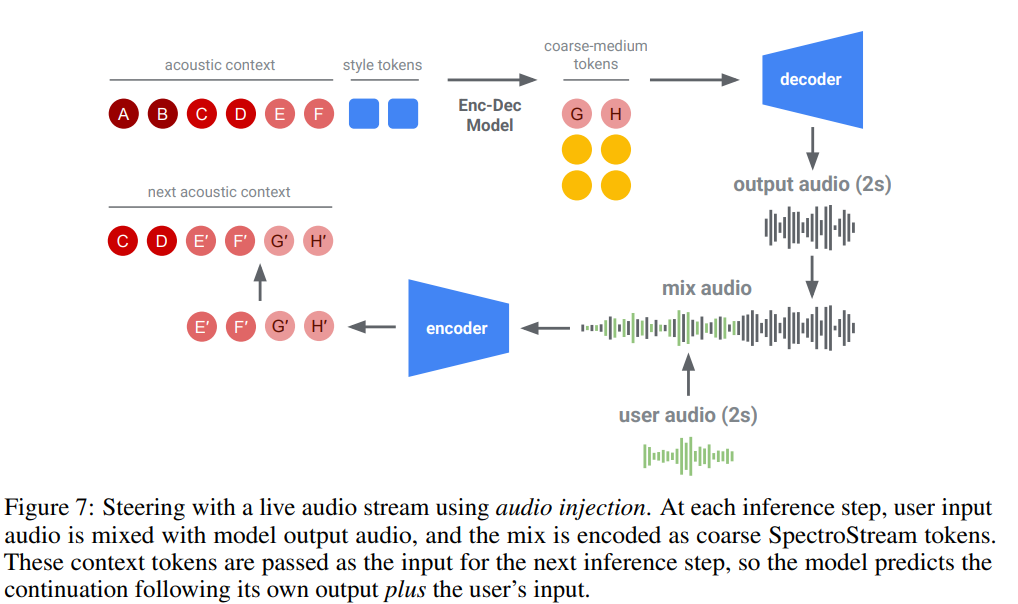
Limitations
1. 스타일 프롬프트 반영 지연
모델이 2초 청크 단위로 생성하기 때문에
사용자가 새로운 스타일 프롬프트(텍스트·오디오)를 바꿔도
→ 최소 2초 이상 지나야 그 변화가 실제 음악 출력에 반영됨.
지금 청크를 내보내는 시간(2초이하)+다음청크에 적용해서 내보내는데까지 걸리는시간(delay)
2. 맥시멈 오디오 컨텍스트 = 10초
모델이 한 번에 참고할 수 있는 이전 오디오 히스토리가 최대 10초.
10초보다 더 이전에 생성된 음악은 직접적으로 기억·참조 불가.
→ 10초 정도의 컨텍스트로 멜로디, 리듬, 코드 진행 같은 단기적 음악 패턴을 만들기는 충분.
하지만,
노래 전체 구조, 장기적 전개(verse–chorus–bridge) 와 같은
수십 초~수분 단위의 큰 곡 구조를 자동으로 유지·계획하는 것은 어려움.
→ 카운팅 후 실시간 jam 그리고 긴 호흡의 상호 연주 불가능
실시간 합주를 위한 아이디어
-
사용자 2초 먼저 시작
t=0~2s 동안 사용자 연주 수집/분석. -
모델이 “다음 2초”를 예측
t≈2s 시점에 곧바로 생성 시작.
RTF≥1이면 t≈(2 + T_gen) 전에 예측 오디오가 준비됨. -
동시 합주처럼 재생
예측된 오디오를 벽시계 타임스탬프로 스케줄해서
t=2s+Δ 시점에 정확히 송출(Δ는 충분히 작은 버퍼, 예: 150–300ms).
사람 소리는 즉시 모니터/PA로, 모델 소리는 예약된 시각에. -
피드백으로 보정
t=2~4s 구간의 실제 사용자 연주가 들어오면
→ 직전에 틀었던 모델 예측과 임베딩/온셋/템포 유사도 비교
→ 다음 예측에 리듬/하모니/다이내믹 가중치 조정 (CFG, 스타일 가중, 스윙, 그루브 등).
방법 1. magenta method: user input은 style token으로, 이전 출력에 대해 더 강하게 보기
방법 2. audio injection: user input을 model output과 섞어서 넣어줌(더 헷갈릴듯)
방법 3. 악기1->악기2 모델을 만들어 user input에 대해 바로 악기2 output 생성이 가능하도록
방법 3 옵션(3)
옵션 A: “드럼→베이스 컨트롤” 파이프라인 (추천, 저지연)
아이디어: 드럼에서 그루브 컨트롤 신호만 추출→ 그걸로 베이스 신스/샘플러를 구동
(= 생성 모델 대신 제약된 규칙+경량 모델로 반응성 확보)
옵션 B: “드럼→베이스” 시퀀스 투 시퀀스 (조건부 생성)
아이디어: 드럼 오디오(또는 드럼 온셋 시퀀스)를 인코더가 읽고, 베이스 이벤트 시퀀스를 디코더가 생성
옵션 C: 오디오-투-오디오 변환 (스타일 트랜스퍼형)
아이디어: 드럼 오디오 → 라텐트 컨트롤(리듬) → 베이스 오디오 합성(디퓨전/콘트롤넷 계열)
