- 대규모 언어모델
방대한 양의 텍스트 데이터를 학습하여 다양한 종류의 텍스트를 생성할 수 있는 능력을 갖춘 모델
ex) 시, 코드, 대본, 음악 작품, 이메일, 편지 등과 같은 다양한 종류의 텍스트를 생성
텍스트를 번역하거나, 요약하거나, 질문에 답하는 등의 작업에도 사용
- 자연어 처리: 텍스트 분류, 텍스트 요약, 질문 응답, 언어 번역 등
- 창의적 콘텐츠 생성: 뉴스 기사, 소설, 시, 코드 등 다양한 종류의 텍스트를 생성
- 챗봇: 챗봇을 통해 자연스러운 대화를 가능하게 하는 데 기여
LLM 학습 과정
데이터 수집 - 데이터 전처리 - 모델 아키텍처 선택 - 학습 알고리즘 선택 - 훈련
- 검증 및 평가 - 모델 활용, 최적화 - 모니터링 - 유지보수
** 아키텍처
- 아키텍처 구성요소
입력 레이어, 은닉 레이어, 출력 레이어, 활성화 함수, 손실 함수, 최적화 알고리즘
- 아키텍처 모델 예시
Transformer : NLP 주로 사용
변형 모델: BERT, GPT, T5
** 학습 알고리즘
1. 역전파 : 모델의 가중치를 조정하여 손실을 최소화하는 것
2. 최적화 알고리즘 : Adam, SGD(확률적 경사 하강법) ...
** 훈련
사전 학습(Pre-Training): 모델이 특정 테스크에 대해 훈련되기 전에, 일반적인 데이터를 통해 기본적인 지식이나 패턴을 학습하도록 하는 것
하이퍼파라미터 조정 : 학습률(Learning Rate), 배치 크기(Batch Size), 에포크(Epoch) 등
** 검증 및 평가
정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수 등 다양한 지표를 사용하여 모델의 성능을 측정
모델 활용, 최적화
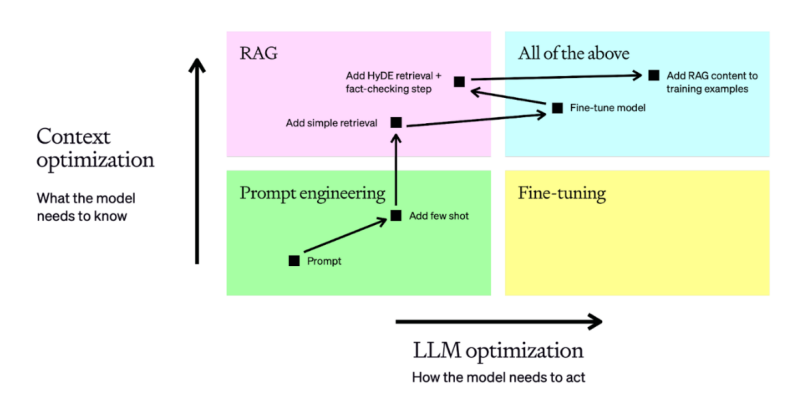
Context Optimization과 LLM Optimization
모델이 무엇을 알아야하는지 모델이 주어진 문제에 대해
최적화 하는 과정 어떻게 행동해야 하는지 최적화 하는 과정
프롬프트,rag 파인튜닝
- 프롬프트
모델이 사전 학습된 상태에서 특정 작업을 수행하거나, 특정 형식으로 응답을 생성할 때 사용
=> 모델의 출력을 원하는 형식으로 유도하거나, 특정 질문에 대한 답변을 얻기 위해 사용
** 더 나은 결과를 위한 6가지 전략
1) 명확하고 구체적인 언어 사용
ex) 빠르게(x), 5분내에
2) 단계별 지침 제공
3) 필요한 컨텍스트 제공
ex)지난 주의 프로젝트 파일을 검토하세요(x)
프로젝트 개요 : ~
검토 목적 : ~
4) 예시 제공
5) 부가 정보 제공
보고서 작성 가이드라인 :
내용 : ~
6) 피드백 및 조정
ex) 피드백 요청 : 제출 전 확인 요청을 하세요
- rag
모델이 복잡한 질문에 대해 정확하고 정보에 기반한 답변을 생성해야 할 때 사용됩니다. 특히, 모델이 사전 학습 단계에서 다루지 않은 특정 정보를 필요로 할 때 유용
=> 모델의 응답을 강화하기 위해 외부 데이터베이스나 문서에서 관련 정보를 검색하고, 이를 기반으로 더 정확한 답변을 생성
- 파인튜닝
모델이 기본적인 언어 이해를 완료한 후, 특정 도메인이나 작업에 대해 더 나은 성능을 발휘하도록 추가 학습이 필요할 때 사용
=> 모델을 특정 도메인(예: 의료, 법률, 고객 서비스)이나 작업(예: 감정 분석, 문서 요약)에서 최적화하여 성능을 향상
==============================================================
API
max_tokens : 최대 글자 길이
temperature : 응답의 창의성 조절(높을수록 창의성 up)
top p : 단어를 선택하는 데 사용되는 확률 임계값 제어
=> 높으면 더 큰 단어풀에서 선택되므로 더 다양하고 예측 불가능
=> 낮으면 단어 풀이 더 작아지므로 결과물이 더 보수적이고 예측 가능
n : 여러 응답 생성
stop : 특정 단어에서 응답 멈추기
ex)
from openai import OpenAI
client = OpenAI(api_key = '' )
completion = client.chat.completions.create(
model = 'gpt-4o-mini-2024-07-18',
messages = [
{'role': 'system','content': '당신은 AI 모델 개발자이다.'},
{"role":'user','content':'LLM에 대해 설명해줘.'}
]
)print(completion.choices[0].message.content)
==============================================================
GPT-4o("o"는 "omni"를 의미)와 GPT-4o mini
기본적으로 텍스트, 오디오 및 비디오 입력의 조합을 처리하도록 설계된 멀티모달 모델
텍스트, 오디오 및 이미지 형식으로 출력을 생성
- GPT-4o mini는 GPT-4o의 가벼운 버전
GPT-4o mini 모델 이미지 처리
- 형식
- Base64
이진 데이터를 텍스트 형식으로 변환
-> 텍스트 형태로 쉽게 전송할 수 있어 네트워크 전송 중에 파일이 손상되거나 변조되는 위험을 줄일 수 있음
** MIME 타입
-
텍스트
text/plain: 일반 텍스트 파일
text/html: HTML 파일 -
이미지
image/jpeg: JPEG 이미지 파일
image/png: PNG 이미지 파일
image/gif: GIF 이미지 파일 -
오디오
audio/mpeg: MP3 오디오 파일
audio/wav: WAV 오디오 파일 -
비디오
video/mp4: MP4 비디오 파일
video/webm: WebM 비디오 파일 -
응용 프로그램
application/json: JSON 데이터 파일
application/pdf: PDF 문서 파일
application/zip: ZIP 압축 파일
ex)
def encode_image(image_path):
with open(image_path, 'rb') as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
base64_image = encode_image(IMAGE_PATH)
response = client.chat.completions.create(
model = MODEL,
messages = [
{"role": "system", "content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"}, # <-- This is the system message that provides context to the model
{"role": "user", "content": [
{'type':'text','text':"What's the area of the triangle?"},
# data:image/png;base64는 이미지 데이터를 표현하는 방법으로, 이 문자열은 이미지가 PNG 형식이며, 뒤에 Base64로 인코딩된 데이터가 따라온다는
{'type':'image_url','image_url':{'url':f"data:image/png;base64,{base64_image}"}
}
]}
],
temperature = 0.0
)- URL 링크
해당 url을 통해 이미지를 다운로드하고 분석 수행
-> 별도로 파일 준비 안해도됨
오디오,비디오 처리
Moviepy라이브러리 사용
cv2(opencv)를 사용하여 비디오 파일을 읽고, 일정 간격으로 프레임 추출
