시퀀스 데이터를 처리하기 위해 설계된 신경망의 한 유형
데이터의 순서를 고려하여 이전의 정보(상태)를 현재의 정보에 전달
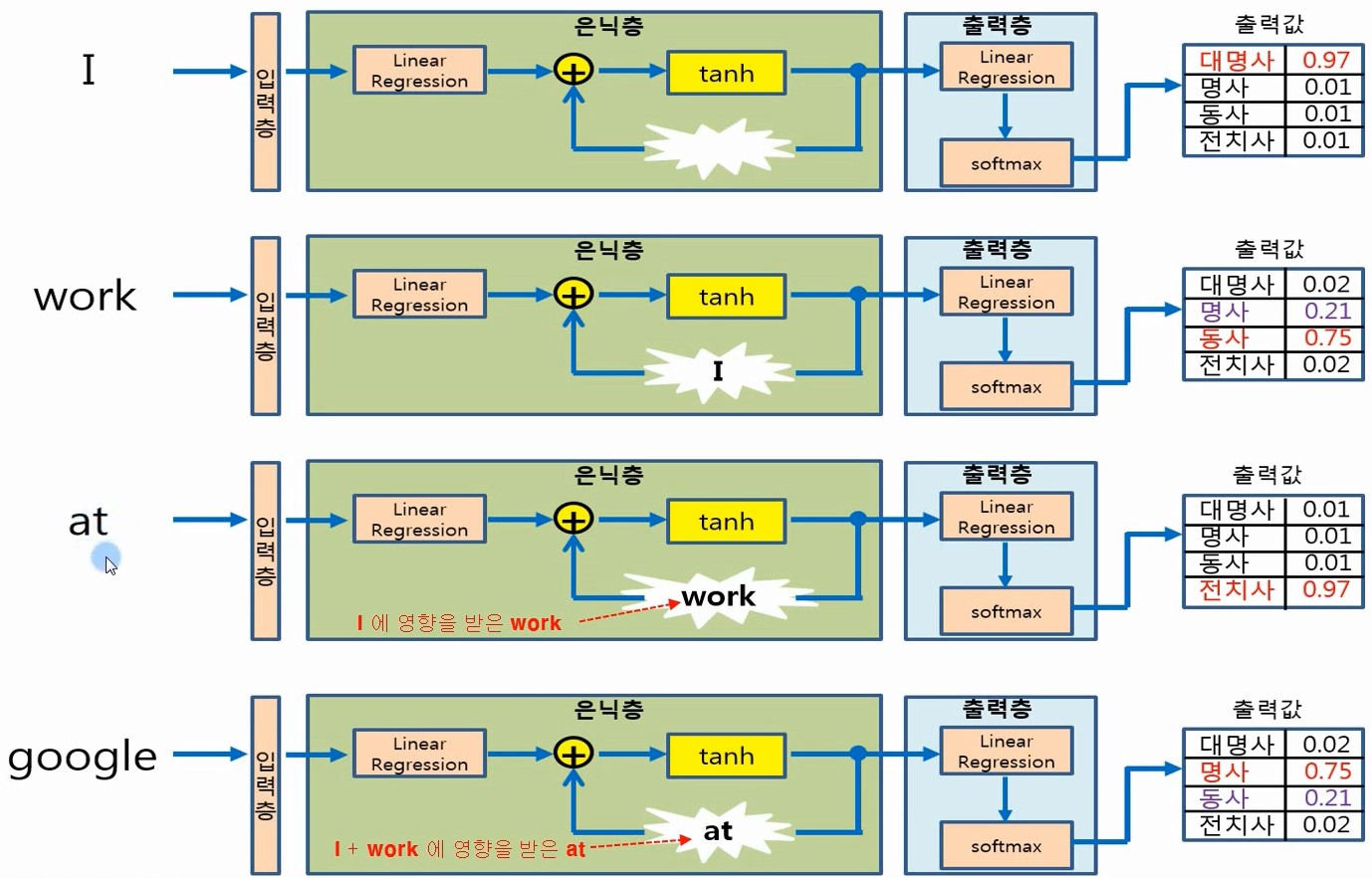
tanh는 일반적으로 전통적인 RNN에서 선호되며, 출력 범위와 0 중심화 특성 때문에 시퀀스 데이터를 처리하는 데 유리할 수 있음
-> tanh 함수의 출력이 -1과 1 사이이고 0을 중심으로 하기에,
신경망은 양의 방향과 음의 방향 모두에서 가중치를 조정할 수 있어 학습 과정이 더 균형 잡히고 효율적으로 진행
반면, ReLU는 그라디언트 소실 문제를 완화하고 계산 효율성이 뛰어나기 때문에, 깊은 RNN이나 변형된 RNN 구조(예: LSTM, GRU)에서 선호
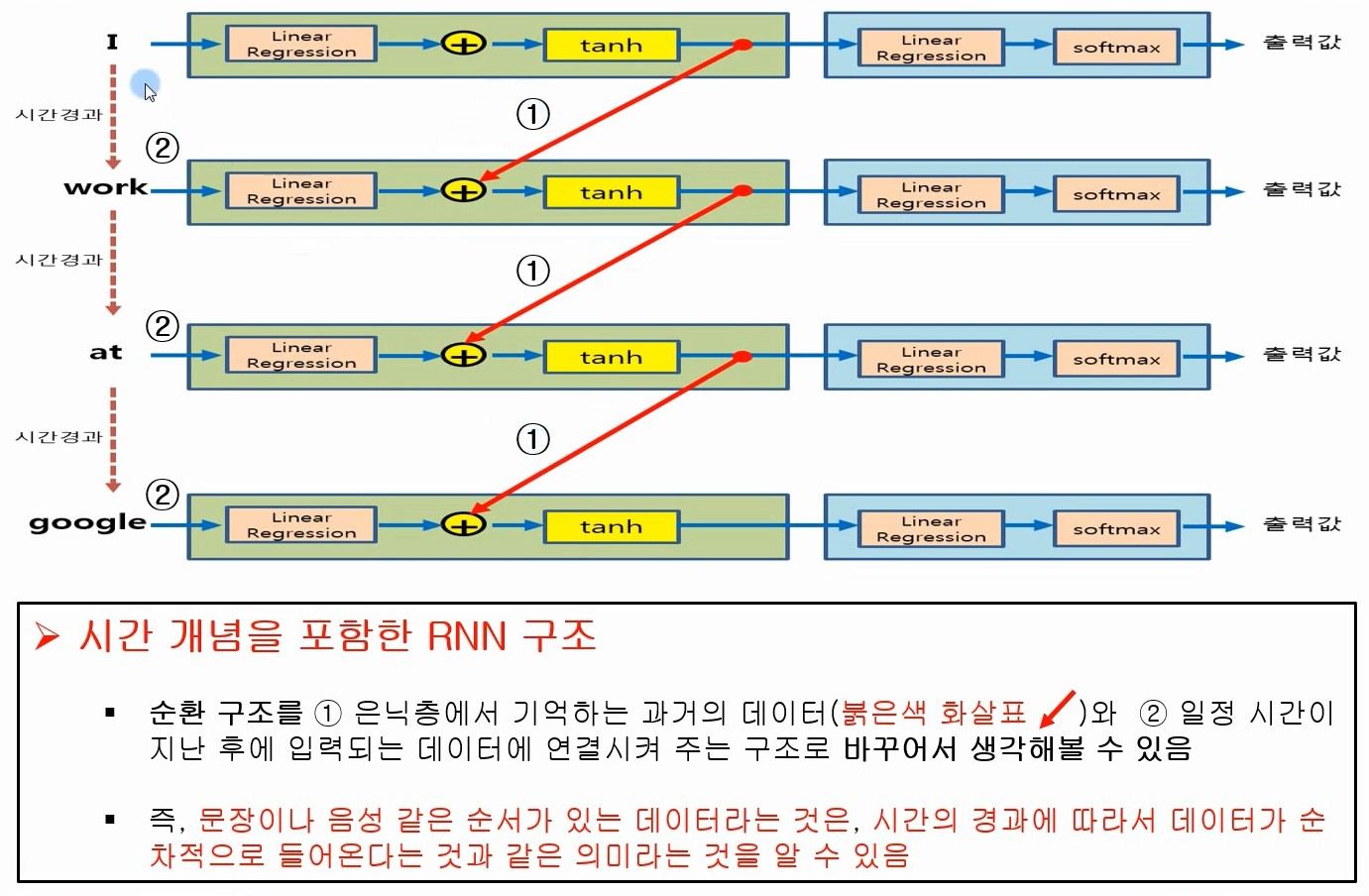
핵심 개념
시간 경과에 따른 메모리 : 지금까지 수행한 계산에 대한 정보를 캡처하는 숨겨진 상태를 유지
순차 처리 : 입력을 순차적으로 처리하여 현재 입력과 이전 입력의 숨겨진 상태에 유지된 정보를 기반으로 결정을 내림
공유 매개변수 : 시퀀스의 여러 위치에서 RNN은 계산을 위해 동일한 매개변수(가중치 및 편향)를 공유
응용
언어 모델링 및 텍스트 생성
음성인식
기계번역
시계열 예측
** SimpleRNN은 상대적으로 구조가 단순하여 기본적인 순차 데이터 처리에 효과적
긴 시퀀스에 대해서는 장기적인 의존성을 잘 학습하지 못할 수 있음
이러한 문제를 해결하기 위해 LSTM(장기 단기 기억)이나 GRU(게이티드 순환 유닛) 같은 더 복잡한 RNN 구조가 사용
