
(1) Amazon EC2란 무엇인가
EC2(Elastic Compute Cloud)는 AWS에서 제공하는 가상 서버 서비스로, 사용자가 원하는 컴퓨팅 자원을 유연하게 생성, 구성 및 관리할 수 있도록 해준다. 이 서비스는 가상 머신을 기반으로 하며, 사용자는 필요한 만큼 컴퓨팅 파워를 제공받고, 사용한 만큼만 비용을 지불하는 방식으로 운영된다.
(2) Amazon S3란 무엇인가
AWS S3(Simple Storage Service)는 데이터를 확장성, 고가용성, 안정성을 가지고 저장할 수 있는 클라우드 스토리지 서비스이다. 키-값(key-value) 저장소로 데이터를 관리하며, 객체의 고유한 키로 식별한다. 정적 웹 사이트 호스팅을 지원하며, 정적 리소스(HMTL, CSS, JS 등)를 저장해 간단한 웹 사이트를 만들 수 있다.
- 버킷(Bucket)
- 데이터를 저장하는 최상위 컨테이너로 리전 내에서 고유한 이름으로 식별되고 데이터는 버킷 안에 객체(Object) 형식으로 저장된다.
- 객체(Object)
- S3에 저장되는 실제 데이터(파일)로 예를 들어 my-bucket/my-folder/myfile.txt에서 my-bucket은 버킷, my-folder/myfile.txt는 키(key)를 의미한다.
- 폴더
- S3는 폴더 구조를 직접적으로 제공하지 않지만, 키(key)를 통해 폴더처럼 데이터를 관리한다. 예를 들어, 키가 my-folder/myfile.txt라면 my-folder는 폴더처럼 보이는 논리적인 경로이다.
- ACL(Access Control List)
- 버킷과 객체의 접근 권한을 설정하는 방식 중 하나로 특정 사용자나 그룹에 읽기/쓰기 권한을 부여할 수 있다.
(2-1) Amazon S3의 활용 분야
- 백업 및 복구(Backup & Restore)
- 뛰어난 내구성과 확장성을 제공하며, 버전 관리 기능을 통한 데이터 보호 기능 제공과 하이브리드(Hybrid) 구성을 통해 기업 내 데이터 백업 및 복원 기능을 제공할 수 있다.
- 데이터 아카이빙(Data Archiving)
- 고객이 규제 대상 산업(금융 및 의료 등)을 위한 규정 준수, 아카이브 요구사항 또는 아카이브 데이터에 드물지만 빠르게 액세스해야 하는 조직을 위한 활성, 아카이브 요구사항을 충족할 수 있도록 다양한 스토리지 클래스를 제공한다.
- 빅데이터 분석을 위한 데이터 레이크(Data Lake)
- 제약 또는 재무 데이터, 사진과 비디오와 같은 멀티미디어 파일과 같이 어떤 파일을 저장하든 관계없이 Amazon S3를 빅데이터 분석용 데이터 레이크(Data Lake)로 사용할 수 있다.
- 하이브리드 클라우드 스토리지(Hybrid Cloud Storage)
- AWS Storage Gateway와 연계하여 On-Premise 환경에서 클라우드 스토리지를 활용할 수 있으며, 데이터 백업 및 재해복구를 원활하게 수행할 수 있다.
- 재해복구(Disaster Recovery, DR)
- S3의 내구성 및 안정성이 뛰어난 글로벌 인프라를 활용하여 탁월한 데이터 보호 및 타 리전(Region)으로 교차 리전 복제(CCR) 서비스를 제공한다.
(2-2) Amazon S3 스토리지 클래스
Amazon S3는 여러 사용 사례에 맞춰 설계된 다양한 스토리지 클래스를 통해 용도에 맞게 사용자가 선택할 수 있는 옵션을 제공한다.
- Amazon S3 Standard - 무제한 저장 가능한 스토리지
- 자주 액세스하는 데이터를 위한 스토리지 클래스
- 내구성, 가용성 및 성능이 뛰어난 객체 스토리지 서비스 제공
- 99.99% 가용성과 99.999999999% 내구성 제공 설계를 지원
- Amazon S3 Standard - IA(Infrequent Access)
- 액세스 빈도가 낮지만, 필요할 때 빠르게 액세스해야 하는 데이터를 위한 스토리지 클래스
- S3 Standard와 같은 내구성 및 성능과 99.9% 가용성을 지원
- Amazon S3 One Zone - IA(Infrequent Access)
- 액세스 빈도가 낮지만, 빠른 액세스가 필요한 데이터를 저장하는 스토리지 클래스
- 단일 AZ에 데이터를 저장함으로써 S3 Standard-IA 대비 20%
- Amazon Glacier - 데이터 백업용 스토리지
- 데이터 보관을 위한 안전하고 안정적이며 비용이 매우 저렴한 스토리지 서비스
- S3와 같은 내구성과 성능 및 가용성 보유
(3) Amazon Glacier란 무엇인가
Amazon Glacier는 데이터 아카이빙 및 장기 백업을 위한 안전하고 안정적이며 비용이 매우 저렴한 클라우드 스토리지 서비스이다. 99.999999999%의 안정성을 제공하도록 설계되어 있으며, 가장 엄격한 데이터 보관에 대한 규제 요구사항(SEC Rule 17a-4, PCI-DSS, HIPAA/HITECH, FedRAMP, EU GDPR 및 FISMA)도 충족할 수 있는 종합적인 보안 및 규정 준수 기능을 제공한다.
S3의 개별 스토리지 영역인 'Bucket'과 'Vault'라는 개별 스토리지 영역을 생성하여 데이터를 보관하며, Console을 통한 업로드로 지원하며 별도의 API를 이용하여 데이터에 대한 저장 기능을 제공한다. 일반적으로 S3에 저장되는 데이터는 라이프사이클 옵션을 활용하여 일정 기간 이상 지난 데이터에 대해 보다 저렴한 Glacier로 이동하여 저장하는 옵션을 사용할 수 있다.
(3-1) Amazon Glacier의 주요 특징
Amazon Glacier는 세 가지의 방법으로 데이터에 접근이 가능하다.
- API/SDK를 이용한 Direct 연결
- S3 라이프 사이클과의 통합
- 3rd Party Tool과 AWS Storage Gateway 연동
API나 SDK를 활용한 프로그램 개발을 통해 깊게 저장된 데이터를 위한 Glacier에 직접 접속한다.
S3의 라이프 사이클과 통합을 통해 오래된 데이터에 대해 Glacier로 자동 이관한다.
기존 Backup 인프라와 3rd Party Tool과의 연계 및 AWS Storage Gateway 통합을 통해 거부감 없는 방식으로 데이터 백업 및 보관 기능을 제공한다.
(4) AWS AMI란 무엇인가
AWS AMI(Amazon Machine Image)는 EC2 인스턴스 생성에 필요한 모든 소프트웨어 정보를 담고 있는 템플릿 이미지이다. 아래 사진과 같이 EC2 인스턴스 생성을 위해 인스턴스 시작 버튼을 클릭하면 본인이 원하는 OS와 Application 종류에 따라 AMI 이미지를 선택하고 생성하면 설치된다.
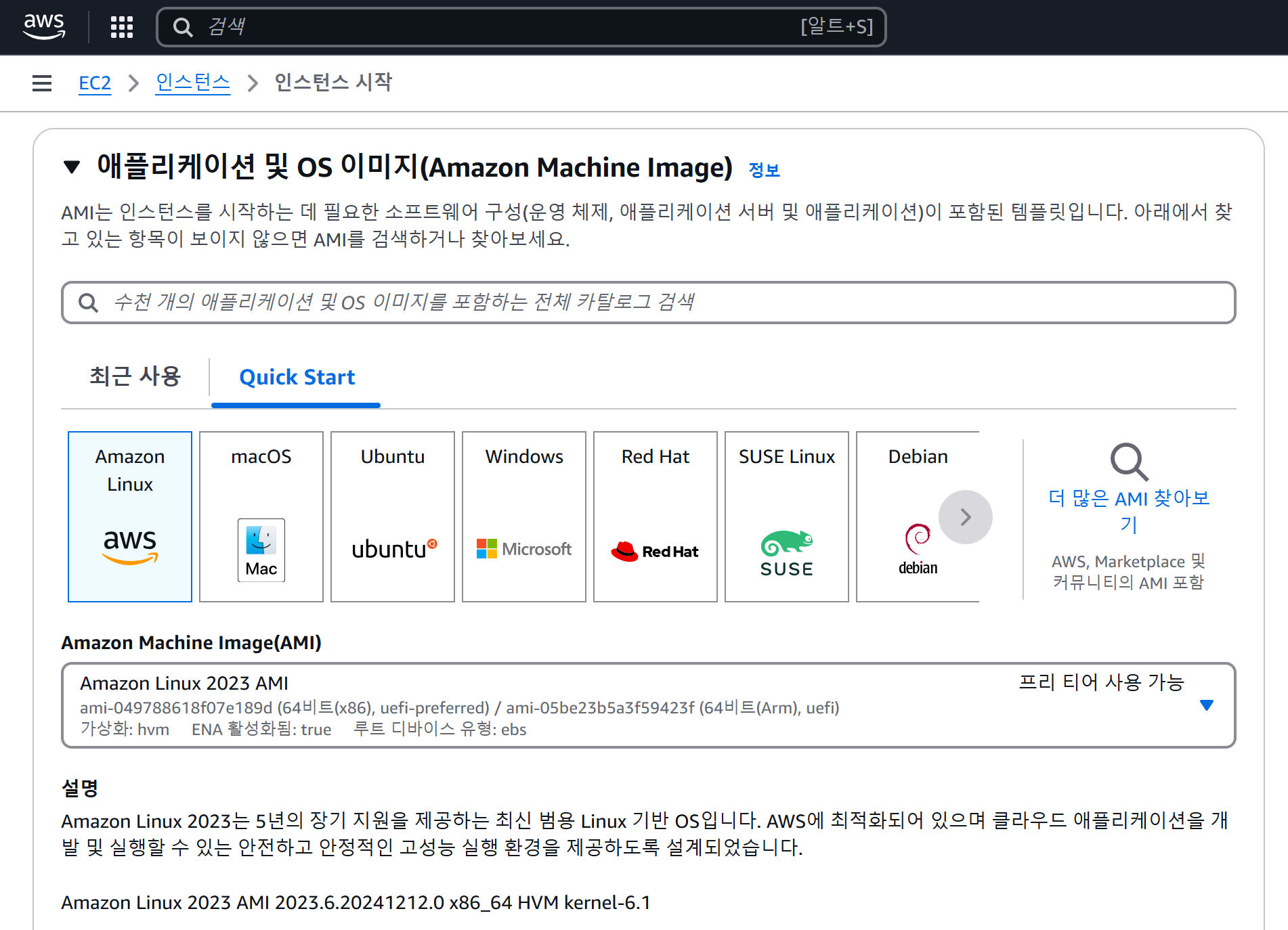 이러한 AMI는 이용자들도 언제든지 생성 가능하며, 이후 동일한 환경을 갖는 인스턴스를 손쉽게 생성할 수 있다. Auto Scaling 등 자동화할 때, EC2 인스턴스를 다른 리전(Region)으로 이전해야 할 때, 상용 솔루션이 설치되어 있는 소프트웨어를 사용하는 경우 AWS Marketplace를 이용하기 위해 AMI를 사용하게 된다.
이러한 AMI는 이용자들도 언제든지 생성 가능하며, 이후 동일한 환경을 갖는 인스턴스를 손쉽게 생성할 수 있다. Auto Scaling 등 자동화할 때, EC2 인스턴스를 다른 리전(Region)으로 이전해야 할 때, 상용 솔루션이 설치되어 있는 소프트웨어를 사용하는 경우 AWS Marketplace를 이용하기 위해 AMI를 사용하게 된다.
(4-1) Amazon Marketplace란 무엇인가
앞서 언급된 Amazon Web Services MarketPlace는 AWS에서 실행되는 소프트웨어를 판매 또는 구매할 수 있는 온라인 스토어이다.
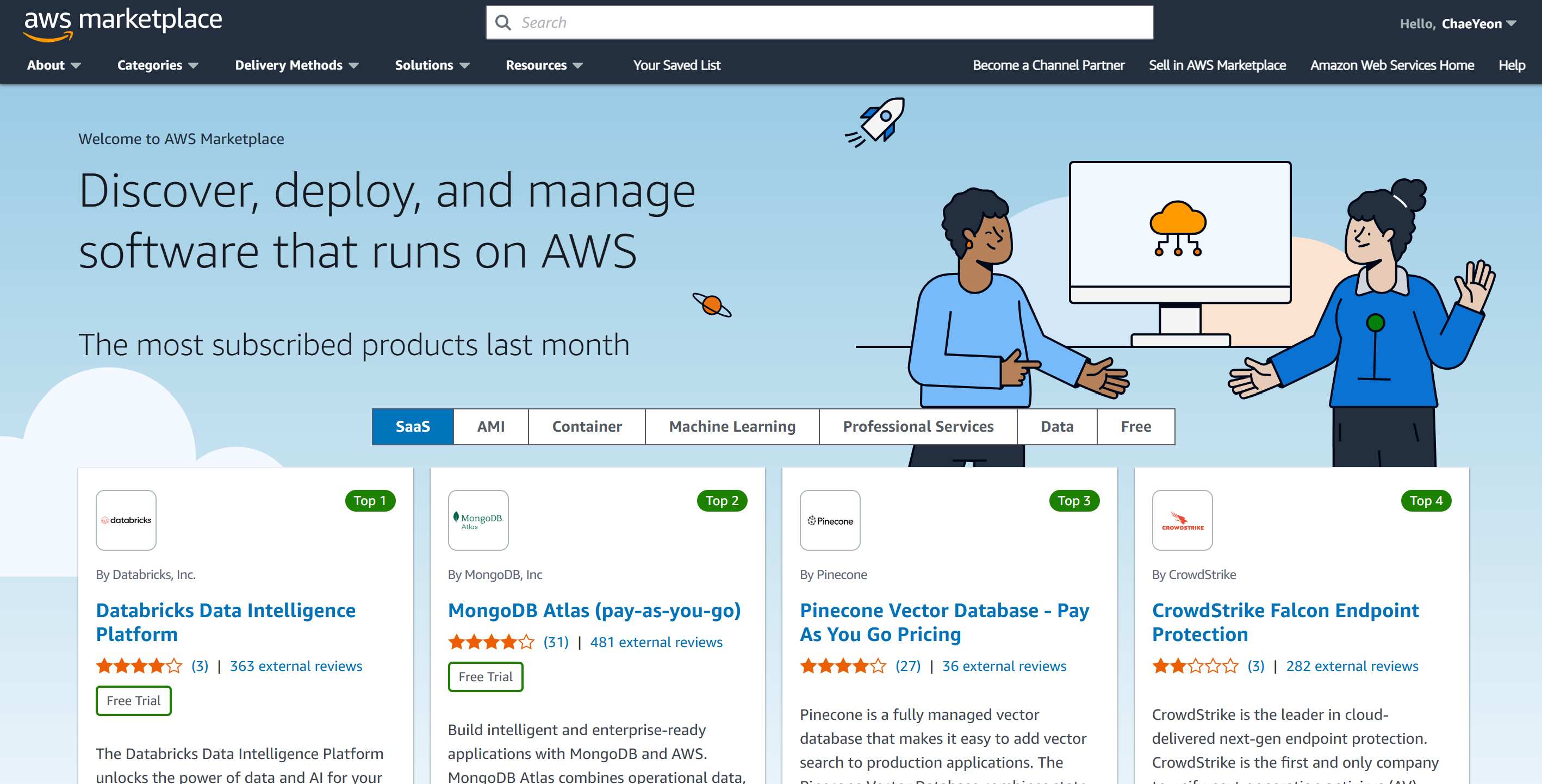 또한 OS(Operating System), Security, Network, Storage, BI(Business Intelligence), Database, Media 등 다양한 분야에 걸친 솔루션들과 Application을 검색, 구매, 배포 및 관리할 수 있는 원-스톱(One-Stop) 쇼핑을 지원한다.
또한 OS(Operating System), Security, Network, Storage, BI(Business Intelligence), Database, Media 등 다양한 분야에 걸친 솔루션들과 Application을 검색, 구매, 배포 및 관리할 수 있는 원-스톱(One-Stop) 쇼핑을 지원한다.
(5) 무한대로 저장 가능한 Amazon S3로 파일 업로드 및 삭제하기
- 서비스 → 스토리지 → S3 접속
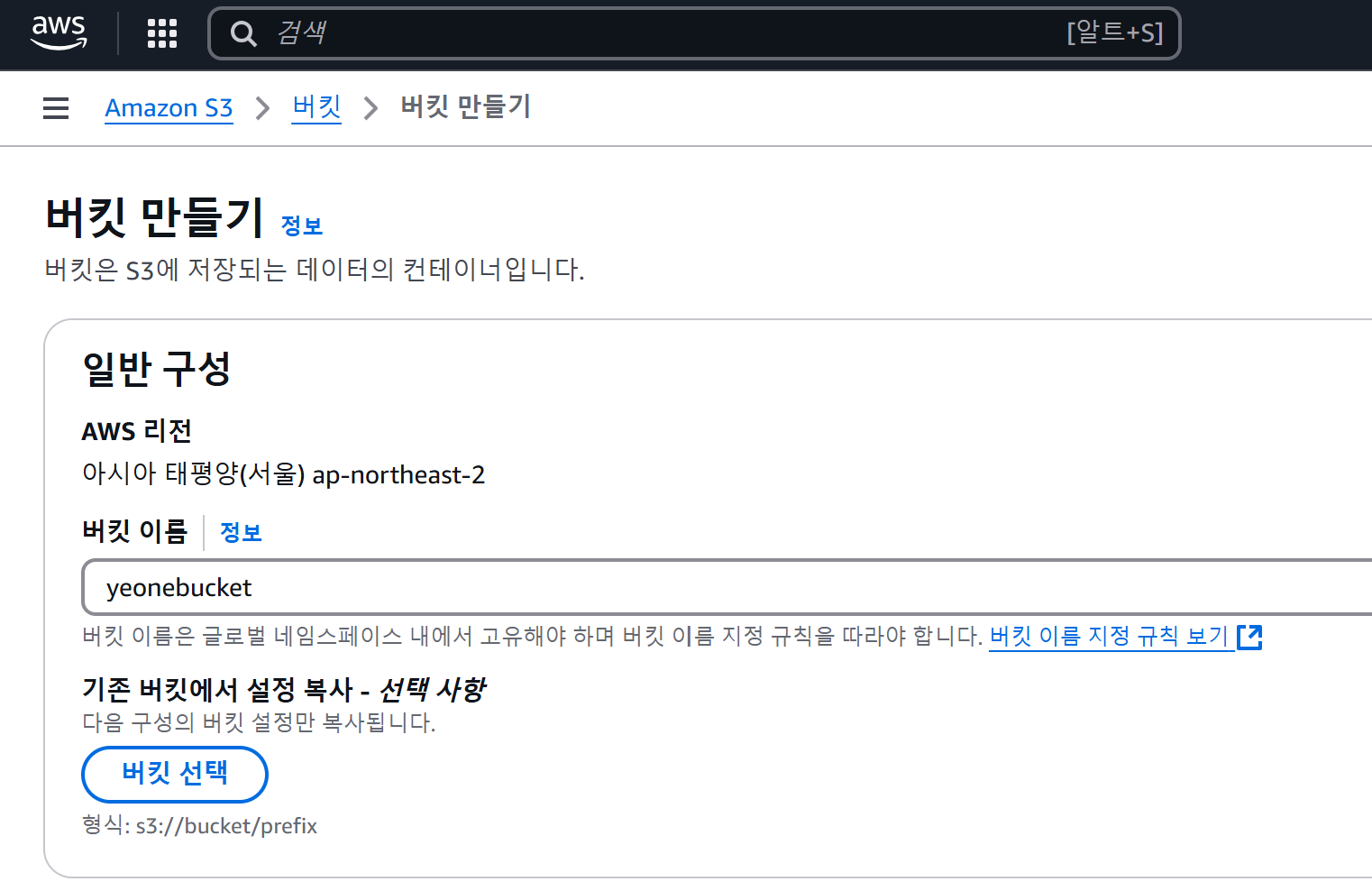
- 처음 접속하면 S3 서비스 사용을 위한 전역적으로 고유한 컨테이너인 '버킷(Bucket)'을 생성해야 한다. 버킷은 리전(Region) 단위로 생성되며, 리전 내에 고유한 별칭을 사용해야 한다. 버킷 생성의 버킷 만들기 버튼을 클릭한다.
- AWS 리전은 아시아 태평양(서울)인지 확인하고, 버킷 이름에는 본인이 원하는 이름을 입력해 버킷을 만든다.
- 범용 버킷에 내가 만든 버킷이 생성되었는지 확인하고 버킷 이름을 클릭하여 하위페이지로 이동한다.
- 폴더 만들기 버튼을 클릭하고 폴더명을 입력해 저장한다.
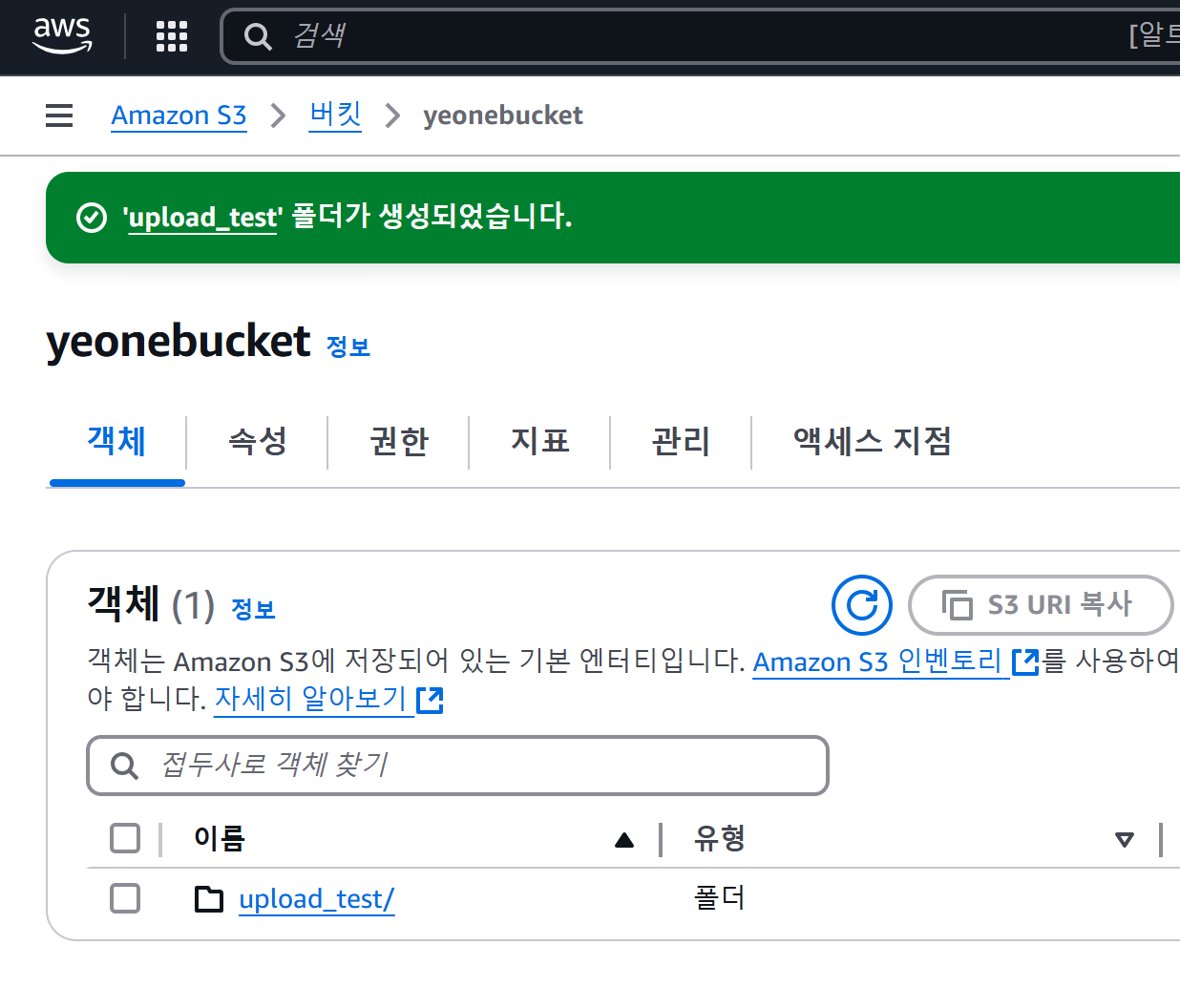
- 생성된 폴더명을 클릭 → 폴더 내부로 이동 후 업로드 버튼을 클릭 → 파일 추가 버튼을 눌러 파일을 추가하거나 Drag & Drop 하여 업로드할 파일을 추가 후 업로드
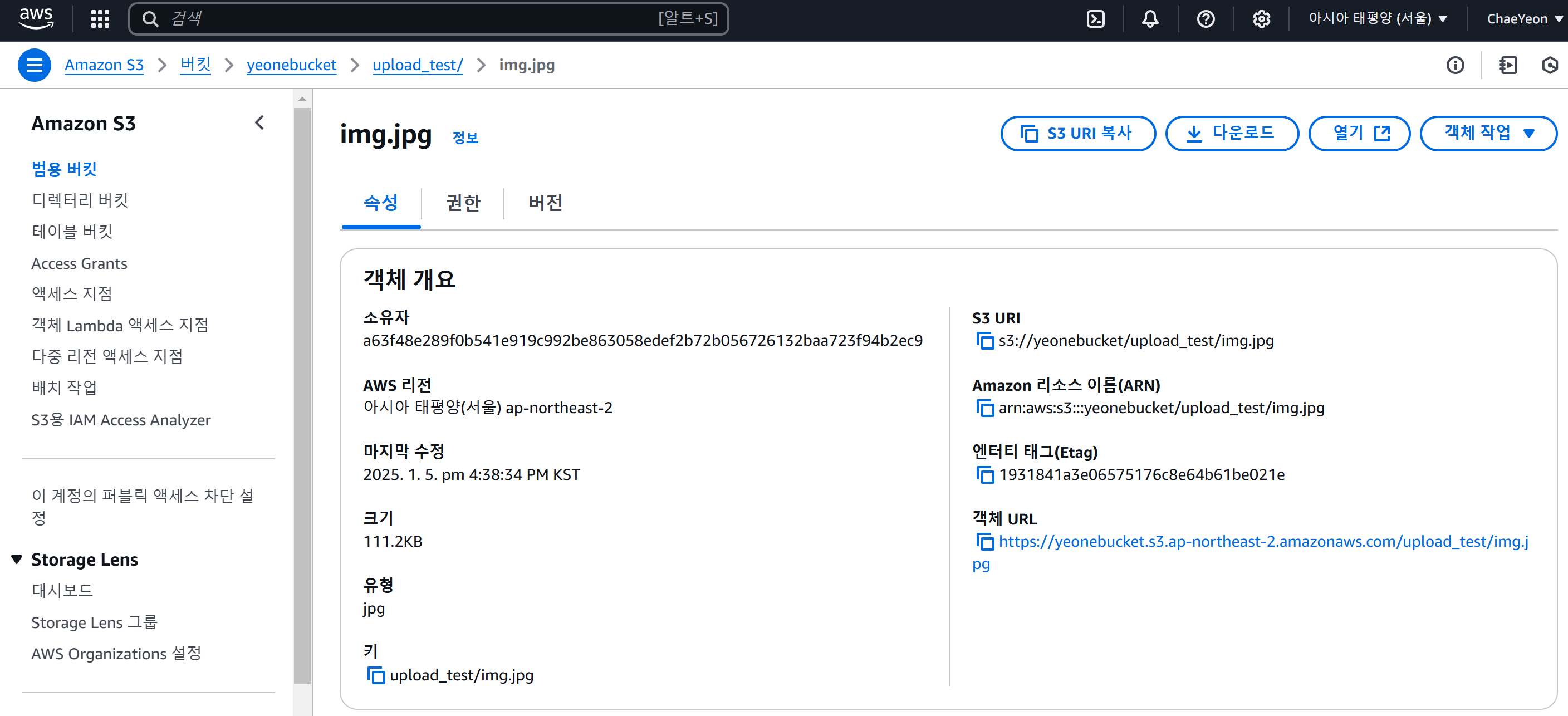
- 파일이 정상적으로 업로드되었다면 파일명을 클릭하여 속성 페이지로 이동한다.
- 업로드된 파일을 확인하기 위해 객체 URL 항목의 전체 접근 경로를 클릭한다.
- 현재는 접근 권한이 없기 때문에 다음과 같이 에러가 표시된다.

- 최근 AWS는 보안 강화를 위해 기본적으로 모든 S3 객체와 버킷을 비공개로 설정하고, 퍼블릭 액세스를 허용하기 위해 추가 단계를 요구한다. 이러한 절차는 사용자 데이터를 보호하고, 실수로 민감한 데이터가 외부에 노출되는 것을 방지하기 위해 설계되었다.
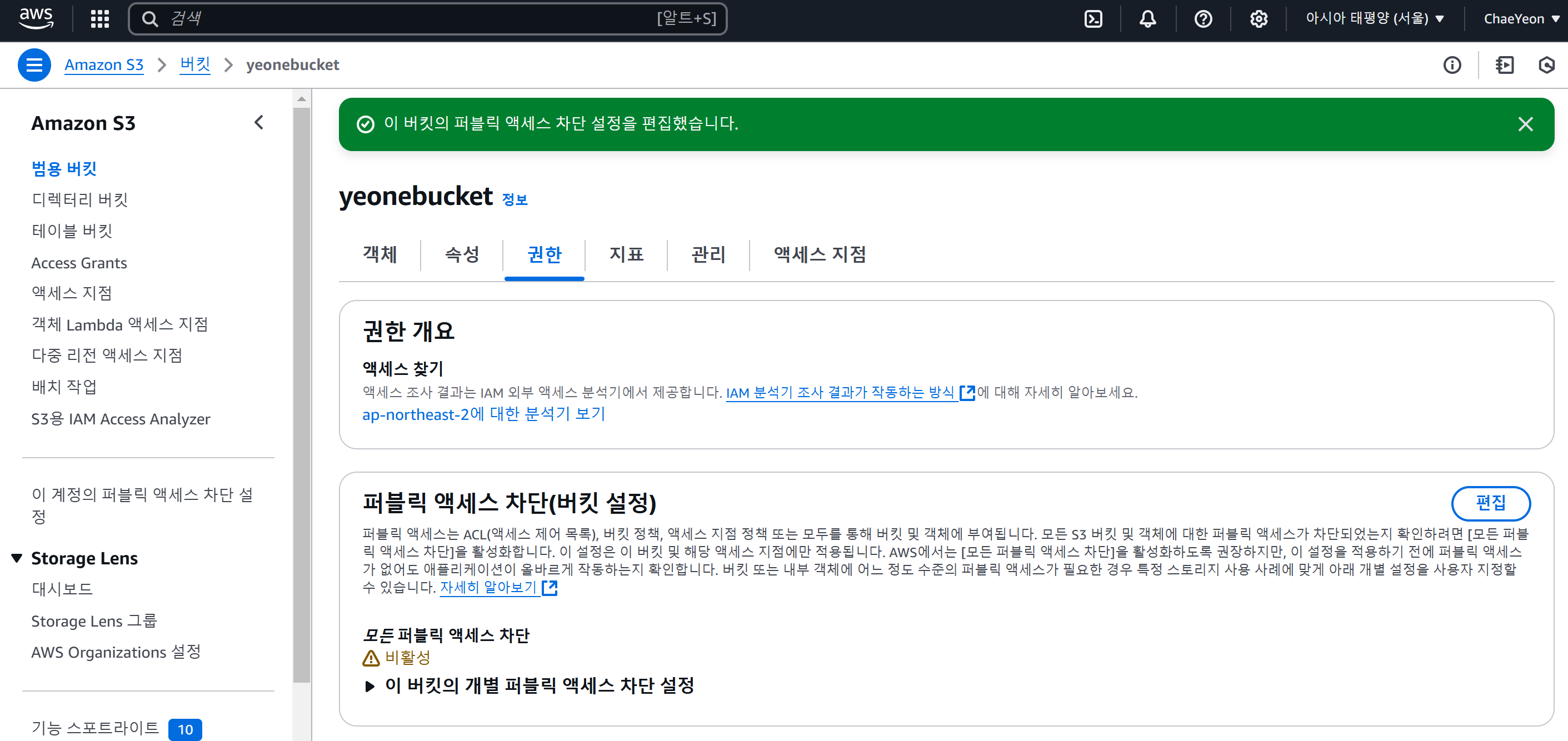
- S3 콘솔 → 버킷 → 권한
- 퍼블릭 액세스 차단 설정(버킷 설정) 섹션에서 편집 버튼을 클릭한다.
- 모든 퍼블릭 액세스 차단 옵션을 해제하고, 변경 사항을 저장한다.
- S3 콘솔 → 버킷 → 권한 → 버킷 정책 → 편집 → 버킷 정책 추가
- 아래의 JSON 정책을 입력하여 객체의 퍼블릭 읽기 권한을 부여한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::버킷이름/*"
}
]
}
- S3 콘솔 → 버킷 → 권한 → 퍼블릭 액세스(Public access) 섹션에서 ACL(액세스 제어 목록) 설정을 확인한다.
- 편집 버튼을 클릭하여 모든 사용자(퍼블릭 액세스) → 읽기(Read) 권한 체크박스를 활성화한다.
- 저장 후, 객체 URL을 다시 확인한다.

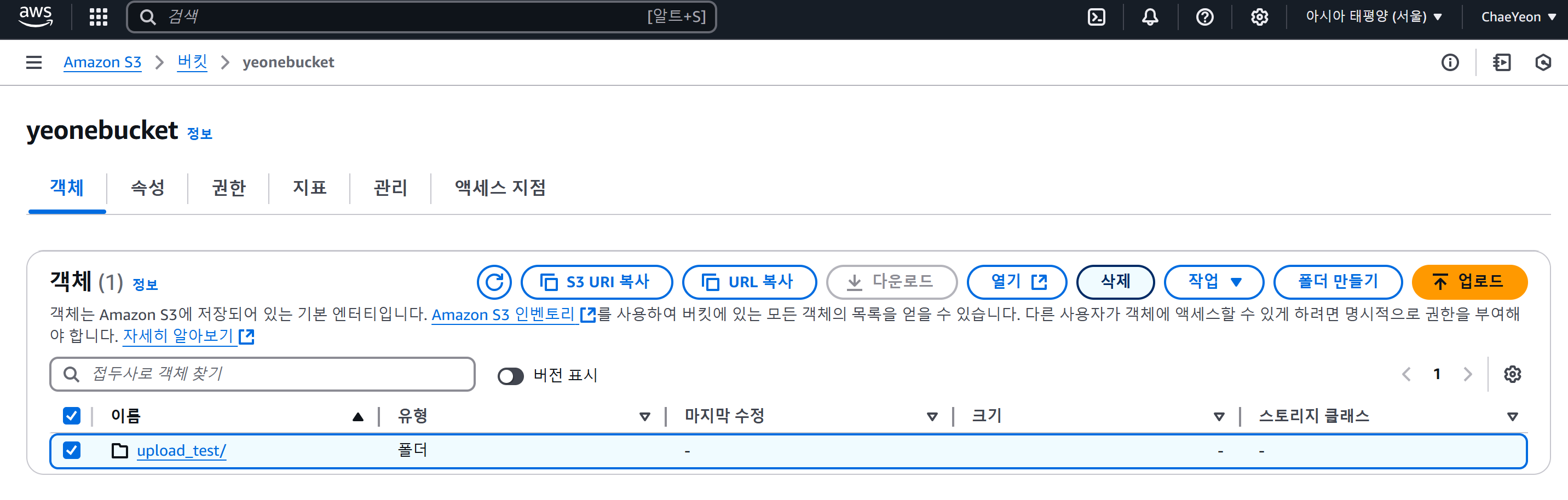
- 폴더 또는 파일 삭제를 원하는 경우 삭제할 대상을 체크해 삭제한다.
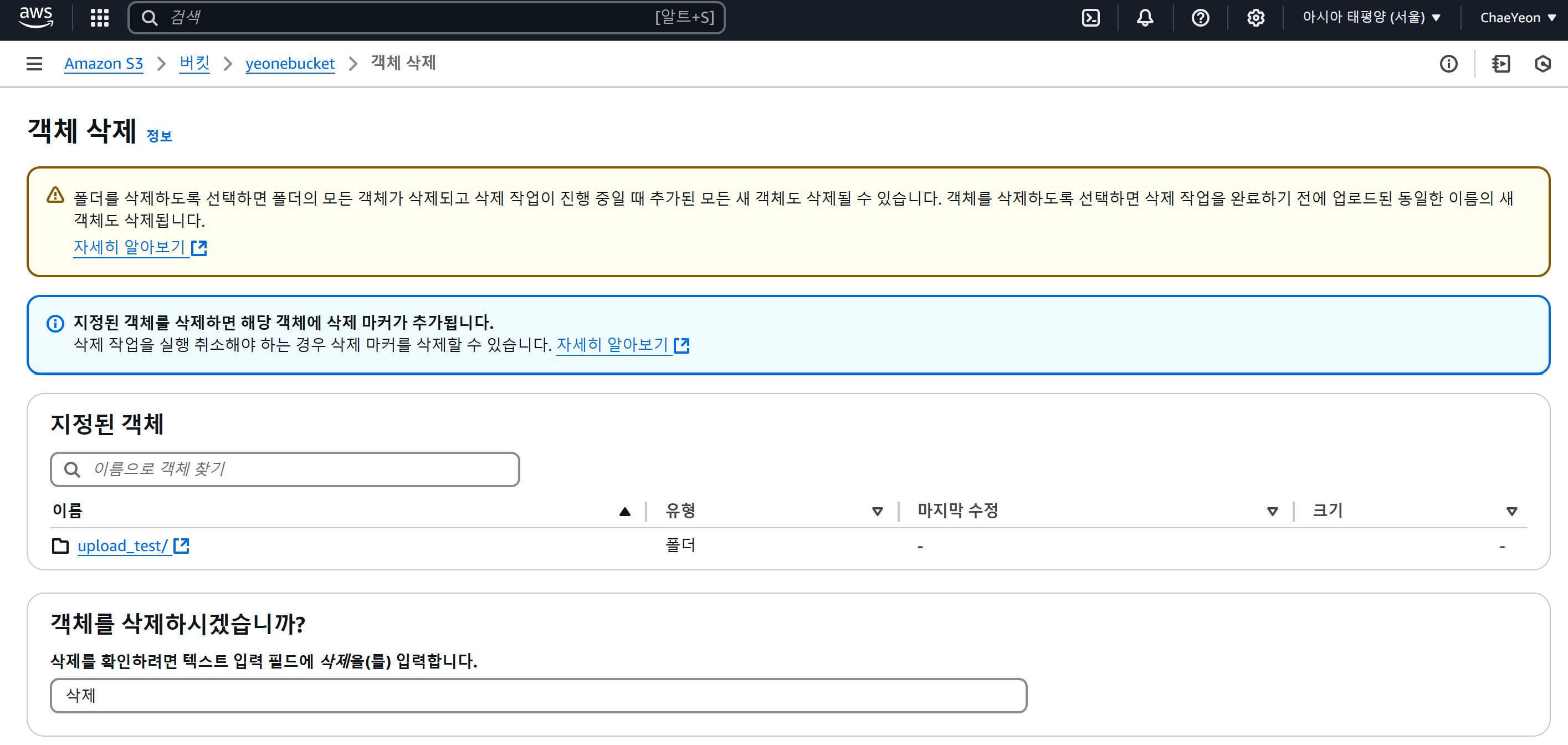
(5-1) PC의 파일을 Amazon S3로 백업하기
AWS 명령줄 인터페이스(CLI)를 사용하여 Amazon S3에 액세스할 수 있도록 구상하고, 로컬 PC 또는 서버에 배치 파일(Batch File)과 윈도우 예약 작업을 활용하여 설정된 일정에 자동으로 백업할 수 있도록 한다.
- 이전과 동일한 방법으로 버킷 내에 백업 테스트를 위해 폴더를 생성한다.
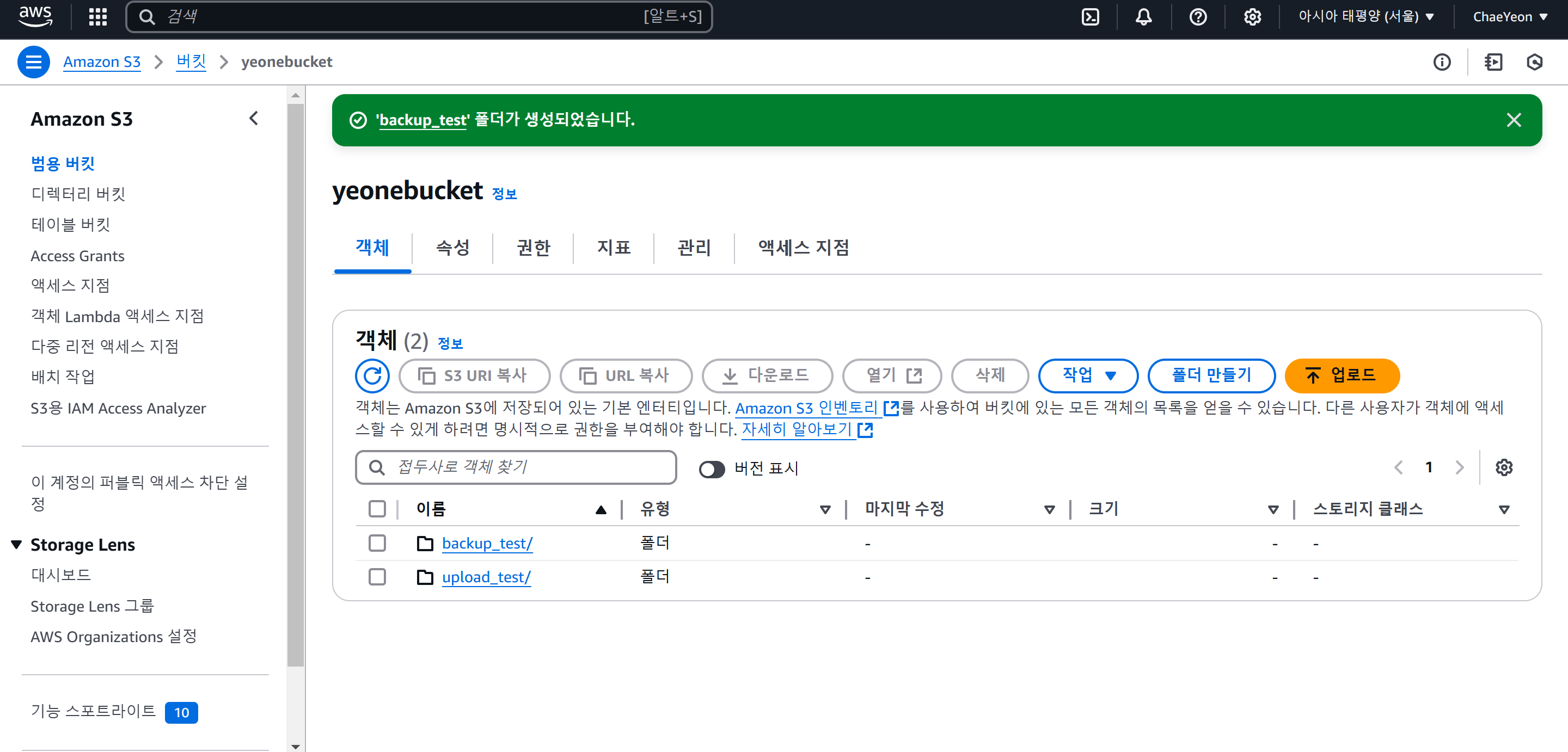
- AWS CLI 사용을 위해 IAM 계정 생성이 필요하다.
- 서비스 → 보안, 자격 증명 및 규정 준수 → IAM
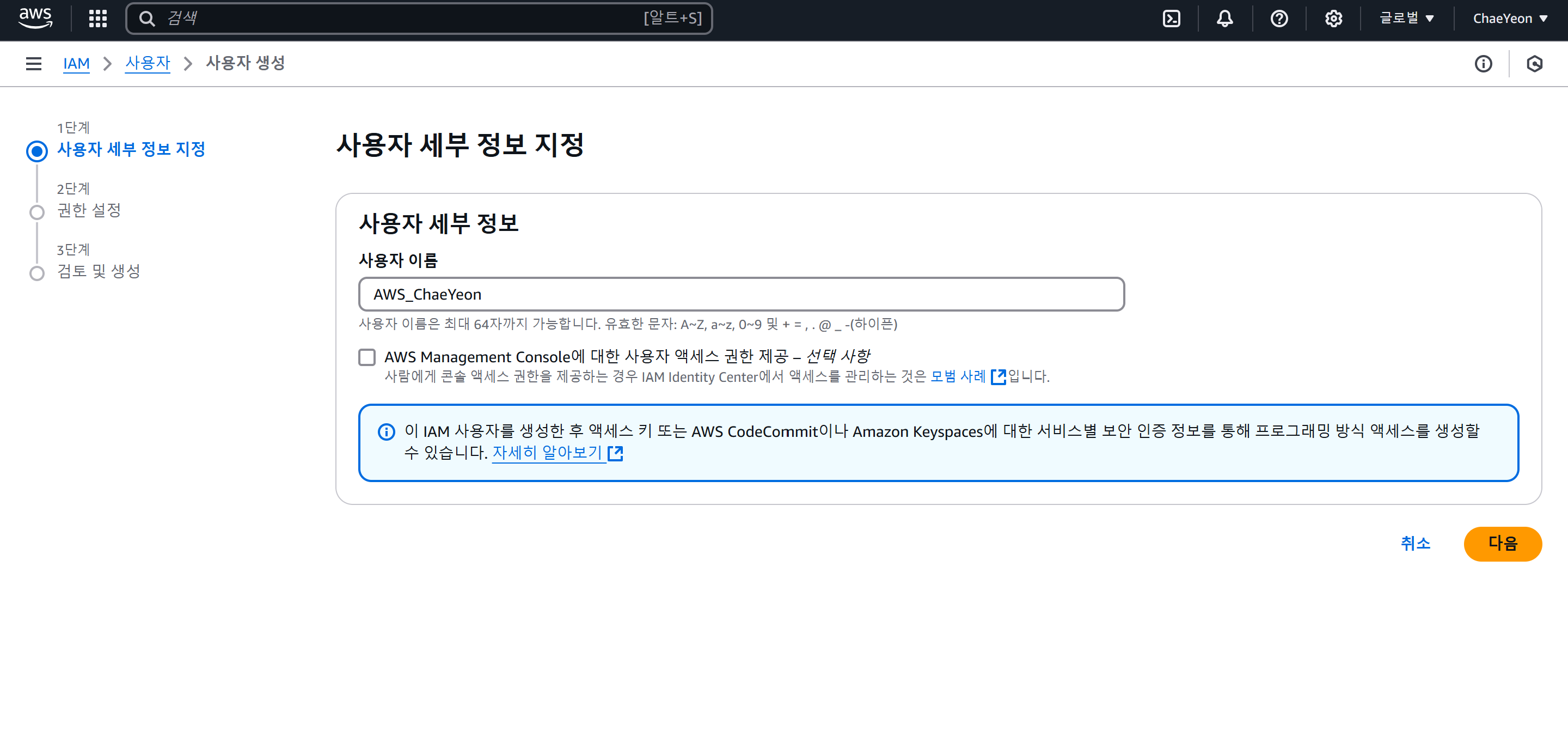
- 사용자 → 사용자 생성 → 사용자 이름 입력
- 권한 설정 → 직접 정책 연결 → "AdministratorAccess" 선택 → 사용자 생성
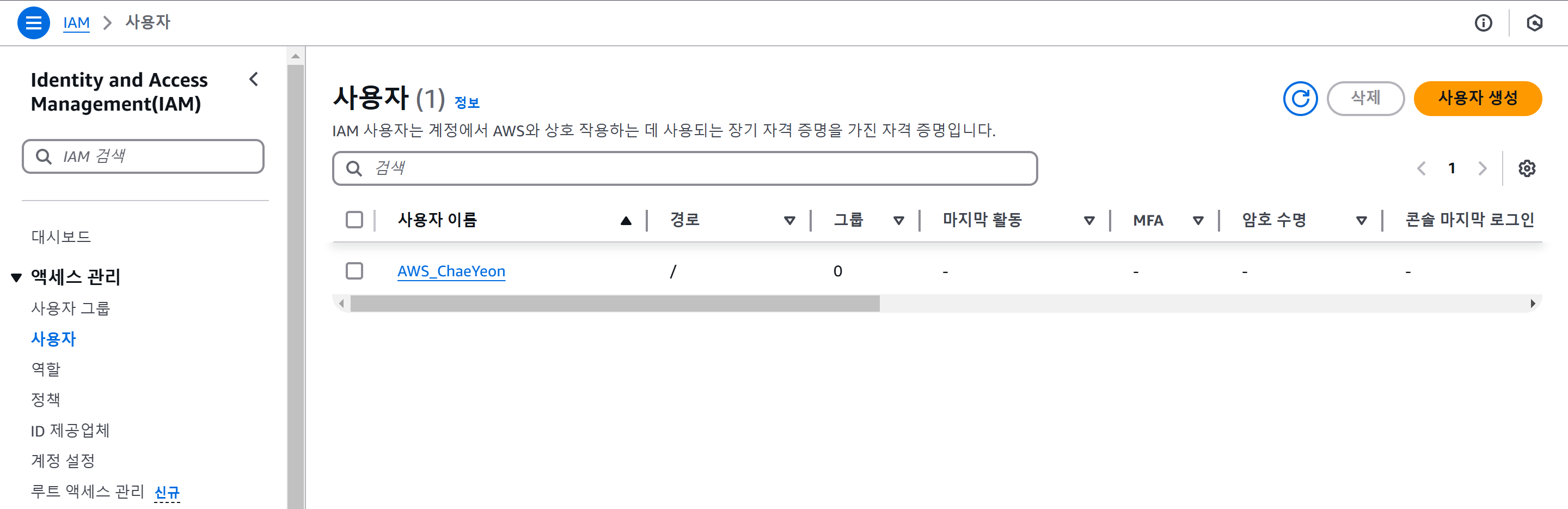
- IAM → 사용자 → 보안 자격 증명 → 액세스 키가 없다면 액세스 키를 생성한다.
- 프로그래밍 접근을 하기 위해 필요한 인증 정보 확인으로 .csv 파일을 다운로드하고 완료한다.
- AWS CLI 설치를 위해 https://docs.aws.amazon.com/ko_kr/cli/latest/userguide/getting-started-install.html 로 이동 후 운영체제에 맞게 다운로드한다.
- 이전에 다운로드 받은 CSV 파일을 열어 인증 정보를 확인한다.
- win+r을 누르고 cmd를 입력한다.
- Command 창에 aws configure를 입력한다.
- CSV 파일에 맞게 입력한다.
- 로컬 PC 또는 서버 내 백업할 폴더 정보를 확인 후 Command 창에 다음과 같이 입력한다.
aws s3 sync '백업할 로컬 파일 경로' s3://버킷명/폴더 경로- S3로 이동 후 파일이 정상적으로 동기화되었는지 확인한다.
- 파일 백업을 자동화하기 위해 배치 파일(.bat)을 만들고 aws s3 sync '백업할 로컬 파일 경로' s3://버킷명/폴더 경로를 로컬 PC에 저장한다.
- 작업 스케줄러를 실행한다.
- 작업 만들기 → "AWS File Backup"
- 보안 옵션 → "사용자가 로그온할 때만 실행, 가장 높은 수준의 권한으로 실행"을 선택
- 트리거 → 새로 만들기 → 설정에서 "매일, 오전 6:00:00, 사용" 선택
- 동작 → 새로 만들기 → 찾아보기 → 이전에 생성한 배치 파일을 선택 후 확인한다.
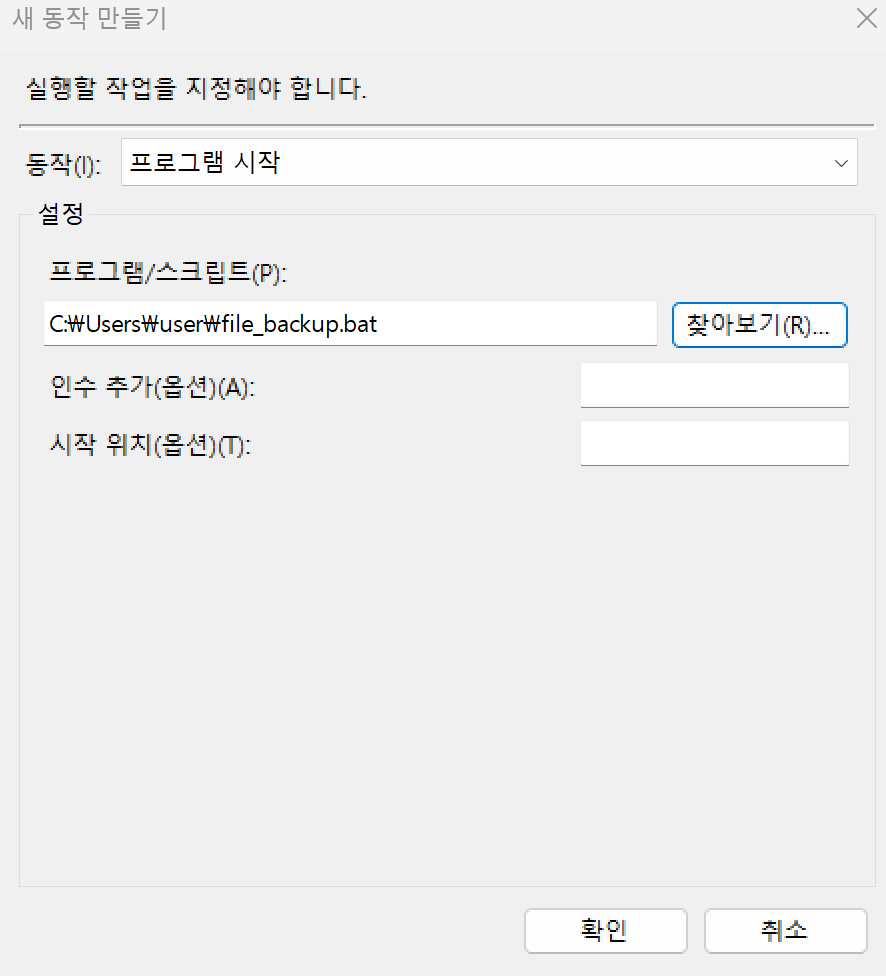
- 작업의 스케줄의 모든 설정을 확인 후 확인 버튼을 눌러, 작업 스케줄 등록을 확인 후 마우스 우클릭 → 실행 버튼을 눌러 정상 동작 여부 확인
- 작업 스케줄을 통해 정상적으로 Sync가 진행되었는지 AWS Console을 통해 확인한다. 이후 작업 스케줄의 옵션을 조정하여 원하는 형태로 파일 백업 및 동기화를 수행할 수 있다.
(6) AMI를 이용한 서버 백업과 복원하기
- 서비스 → 컴퓨팅 → EC2 접속
- 인스턴스에서 백업할 인스턴스 선택 후 우클릭 → 이미지 → 이미지 생성
- 이미지 이름에 생성할 이미지 입력 → 이미지 생성
- 이미지 → AMI에서 AMI가 정상적으로 생성되었음을 확인한다.
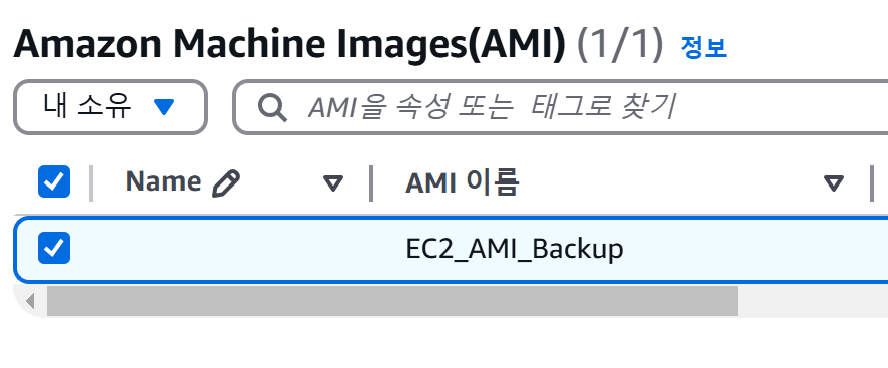
- 인스턴스에서 기존 인스턴스를 선택 후 종료 버튼을 눌러 기존 인스턴스를 삭제한다.
- 이미지 → AMI에서 AMI 이미지를 선택 후 우클릭 → 시작
- 인스턴스 유형은 "t3.micro"로 선택
- 키 페어는 이전에 만든 키 페어로 선택하고 인스턴스 시작
- 인스턴스 페이지로 이동 후 신규로 생성된 인스턴스의 퍼블릭 IP 확인 후 PuTTY를 통해 접속을 시도한다.
(7) AWS 클라우드에서 외부 액세스 권한 설정하기
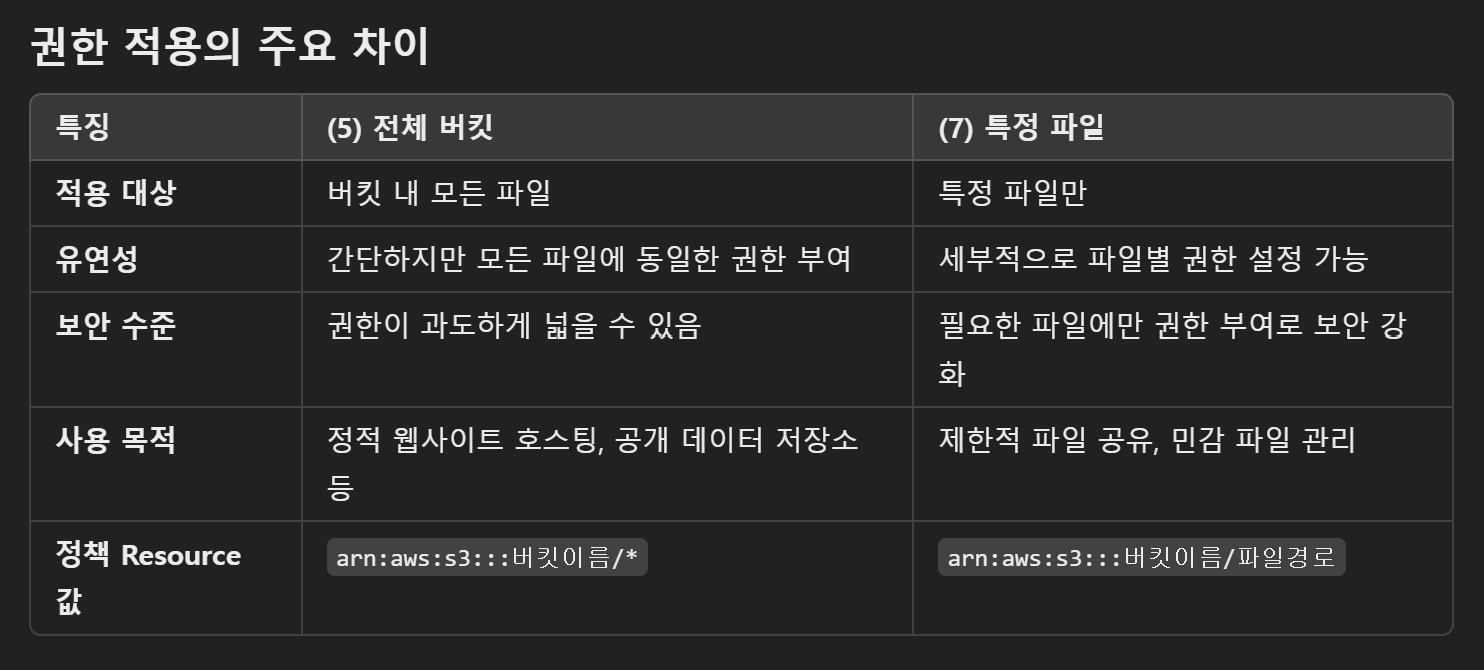
(5) 무한대로 저장 가능한 Amazon S3로 파일 업로드 및 삭제하기에서 사용된 액세스 권한은 버킷 내의 모든 객체(파일)에 동일한 권한을 부여하는 방식이다. 특정 파일이 아니라 버킷 전체에 퍼블릭 읽기 권한을 허용한다.
반면, (7) AWS 클라우드에서 외부 액세스 권한 설정하기는 특정 파일만 개별적으로 권한을 부여하는 방식으로 특정 파일에만 적용되므로 버킷 내 다른 파일에는 영향을 미치지 않는다.
- 서비스 → 스토리지 → S3 콘솔 → 액세스 권한을 설정할 파일이 포함된 버킷 → 객체 소유권(Object Ownership)이 버킷 소유자로 설정되어 있는지 확인한다. (필요 시 ACL(액세스 제어 목록)을 사용하도록 설정한다.) → 버킷 정책 → 편집 → 버킷 정책 추가
- 아래의 JSON 정책을 입력하여 객체의 퍼블릭 읽기 권한을 부여한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::버킷이름/파일경로"
}
]
}2주 차를 마치며...
교수님의 도움으로 어떻게 공부해야 할지 알게 되었고, 앞으로 자투리 시간을 이용해 실습을 제외한 이론 부분은 틈틈이 작성해야겠다고 생각했다.
