3-8~9 웹스크래핑(크롤링)
네이버 영화 랭킹 크롤링 하기
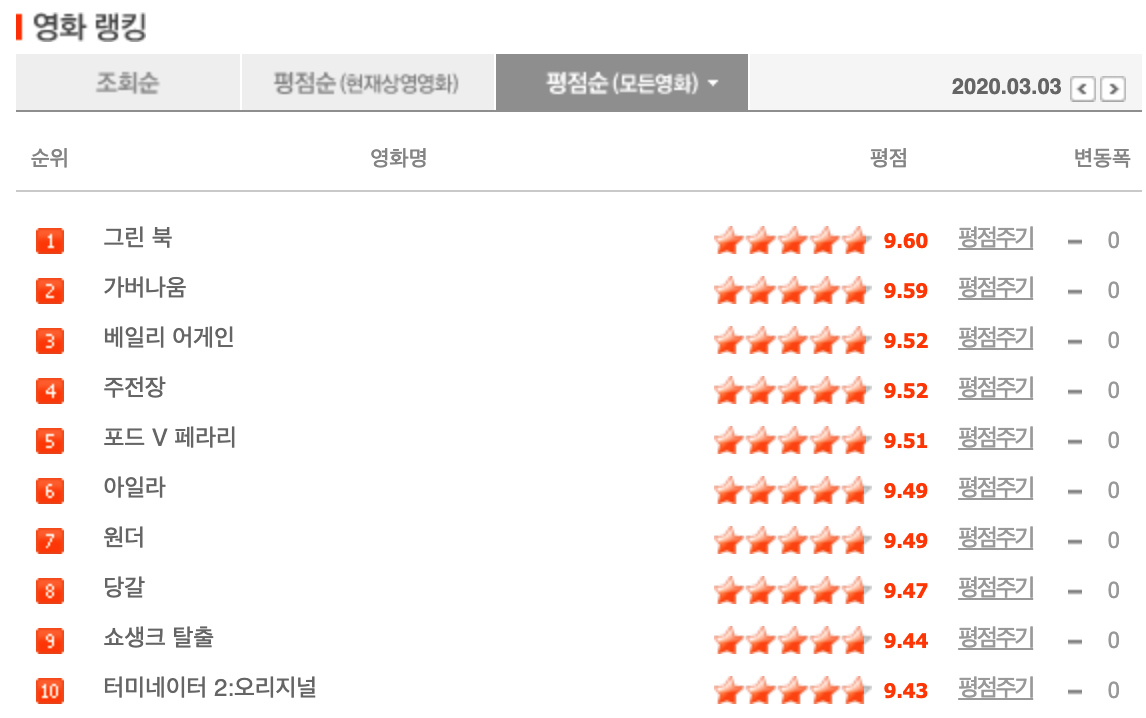 오늘은 해당 페이지를 활용해 크롤링을 연습해볼 것이다.
오늘은 해당 페이지를 활용해 크롤링을 연습해볼 것이다.
- 크롤링이란?
크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위
import requests 👉🏻 전체 내용 요청
from bs4 import BeautifulSoup 👉🏻 필요한 내용만 출력
개별값 크롤링
이중 <포드 V 페라리>를 출력해볼 것이다.
선생님은 <그린북>을 예시로 들었는데 나는 <그린북> 알러지가 있으므로...^^ <그린북>측은 2019 오스카 작품상을 조속히 반납하길 바랍니다.
<포드 V 페라리>를 선택하고 개발자도구-Elements-포드 V 페라리 코드-Copy Selector를 클릭한다.
#old_content > table > tbody > tr:nth-child(6) > td.title > div > a이중 <포드 V 페라리>를 특정하는 코드는 :nth-child(6)이다.
(바꿔 말하면 :nth-child(6) 전까지는 랭킹 전체의 정보를 담는 코드라는 사실을 알 수 있다.)
title = soup.select_one('#old_content > table > tbody > tr:nth-child(6) > td.title > div > a')
print(title)
👇🏻
<a href="/movie/bi/mi/basic.naver?code=181710" title="포드 V 페라리">포드 V 페라리</a>
select_one을 사용해 위에서 추출한 경로를 출력하자 개발자도구에서 긁어온 코드가 그대로 출력되었다.
print(title.text)
print(title['href'])
👇🏻
포드 V 페라리
/movie/bi/mi/basic.naver?code=181710title에서 제목과 소스만 출력하는 응용도 가능하다.
전체값 크롤링
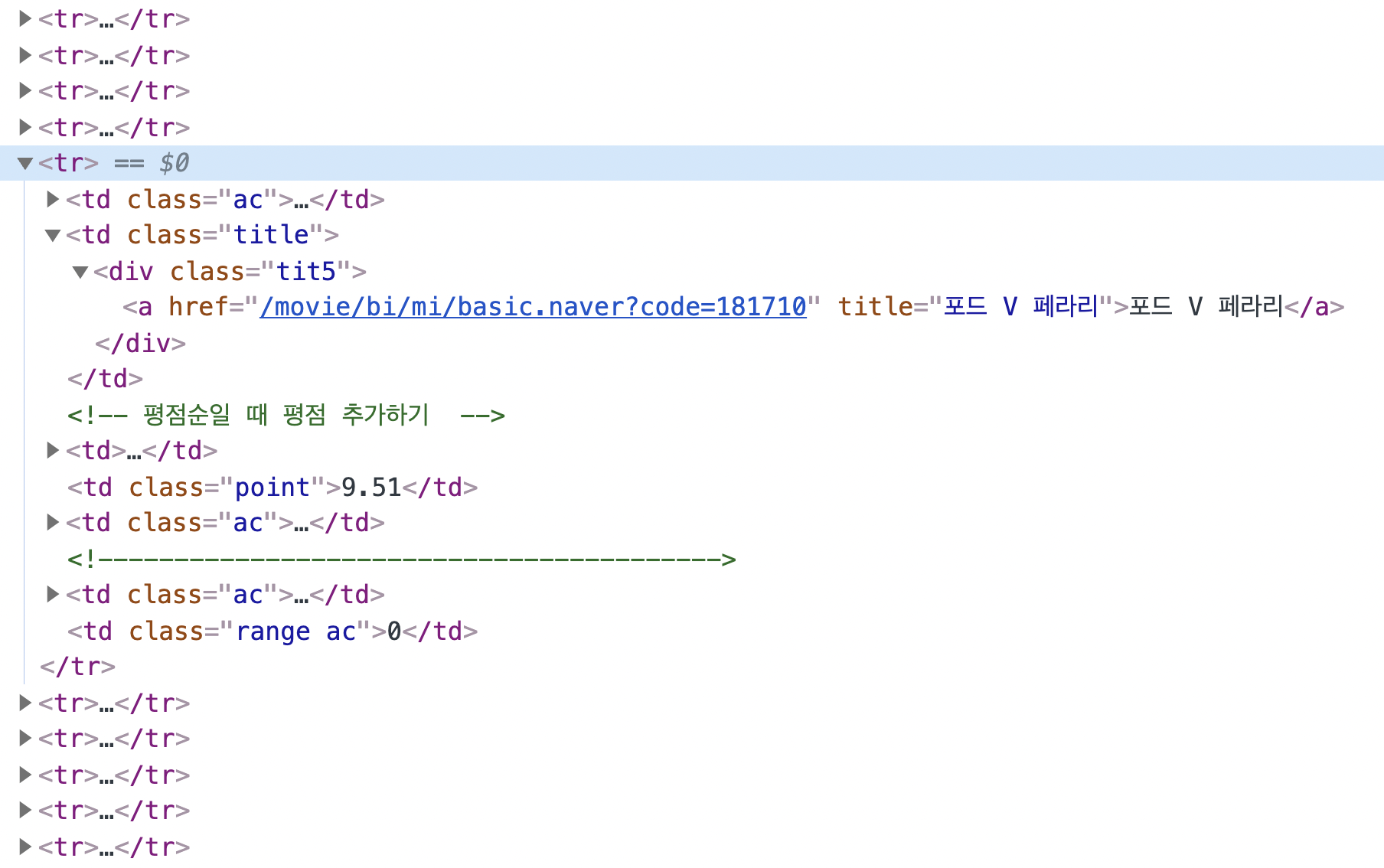 <포드 V 페라리>에 해당되는 코드값이 리스트 안에 포함되는 것을 확인할 수 있다. 이를 토대로 이번에는 랭킹의 전체 값을 출력해볼 것이다.
<포드 V 페라리>에 해당되는 코드값이 리스트 안에 포함되는 것을 확인할 수 있다. 이를 토대로 이번에는 랭킹의 전체 값을 출력해볼 것이다.
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
print(tr)
이전 과정에서 쓴 select_one은 한 개의 값을 출력하는 태그이므로 여기선 select 태그를 쓴다. select는 리스트를 출력하기 때문에 반복문(for)도 같이 써야 한다.
<tr>
<td class="ac"><img alt="01" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r01.gif" width="14"/></td>
<td class="title">
<div class="tit5">
<a href="/movie/bi/mi/basic.naver?code=171539" title="그린 북">그린 북</a>
</div>
</td>
<!-- 평점순일 때 평점 추가하기 -->
<td><div class="point_type_2"><div class="mask" style="width:96.00000381469727%"><img alt="" height="14" src="https://ssl.pstatic.net/imgmovie/2007/img/common/point_type_2_bg_on.gif" width="79"/></div></div></td>
<td class="point">9.60</td>
<td class="ac"><a class="txt_link" href="/movie/point/af/list.naver?st=mcode&sword=171539">평점주기</a></td>
<!----------------------------------------->
<td class="ac"><img alt="na" class="arrow" height="10" src="https://ssl.pstatic.net/imgmovie/2007/img/common/icon_na_1.gif" width="7"/></td>
<td class="range ac">0</td>
</tr>
.
.
.그럼 모든 정보가 출력된다. 하지만 이렇게 출력되면 정보가 너무 방대하므로 tr안에서 특정한 정보만을 출력해보기로 하자. Copy selector를 통해 긁어왔던 코드 중 td.title > div > a 부분을 사용하면 된다.
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
print(a_tag)
👇🏻
None
<a href="/movie/bi/mi/basic.naver?code=171539" title="그린 북">그린 북</a>
<a href="/movie/bi/mi/basic.naver?code=174830" title="가버나움">가버나움</a>
<a href="/movie/bi/mi/basic.naver?code=144906" title="베일리 어게인">베일리 어게인</a>
<a href="/movie/bi/mi/basic.naver?code=179518" title="주전장">주전장</a>
<a href="/movie/bi/mi/basic.naver?code=181710" title="포드 V 페라리">포드 V 페라리</a>
<a href="/movie/bi/mi/basic.naver?code=169240" title="아일라">아일라</a>
<a href="/movie/bi/mi/basic.naver?code=151196" title="원더">원더</a>
<a href="/movie/bi/mi/basic.naver?code=157243" title="당갈">당갈</a>
<a href="/movie/bi/mi/basic.naver?code=17421" title="쇼생크 탈출">쇼생크 탈출</a>
<a href="/movie/bi/mi/basic.naver?code=10200" title="터미네이터 2:오리지널">터미네이터 2:오리지널</a>
None
.
.
.다시 여기서 제목만 출력하려면 a.tag에 .text를 붙이면 된다. 그러나 중간중간 .text로 출력할 수 없는 None(구분선)이 있기 때문에 이 경우엔 .text를 사용하면 오류가 난다.
Traceback (most recent call last):
File "/Users/cinephile/Desktop/sparta/pythonprac/film.py", line 13, in <module>
print(a_tag.text)
AttributeError: 'NoneType' object has no attribute 'text' (a_tag.text를 사용했을시 뜨는 오류)
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
print(a_tag.text)
👇🏻
그린 북
가버나움
베일리 어게인
주전장
포드 V 페라리
.
.
.조건문 if a_tag is not None:을 추가하자 성공적으로 출력되었다.
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
title = a_tag.text
print(title) 더 깔끔한 코드 작성을 위해 print(a_tag.text)를 title = a_tag.text라는 변수로 분리했다. 출력시 결과는 위와 같다.
랭크, 제목, 별점순으로 크롤링하기
- 정답
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank, title, star)- 나의 코드
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = a_tag['alt']
title = a_tag.text
star = a_tag['point']
print(rank, title, star)- 해설
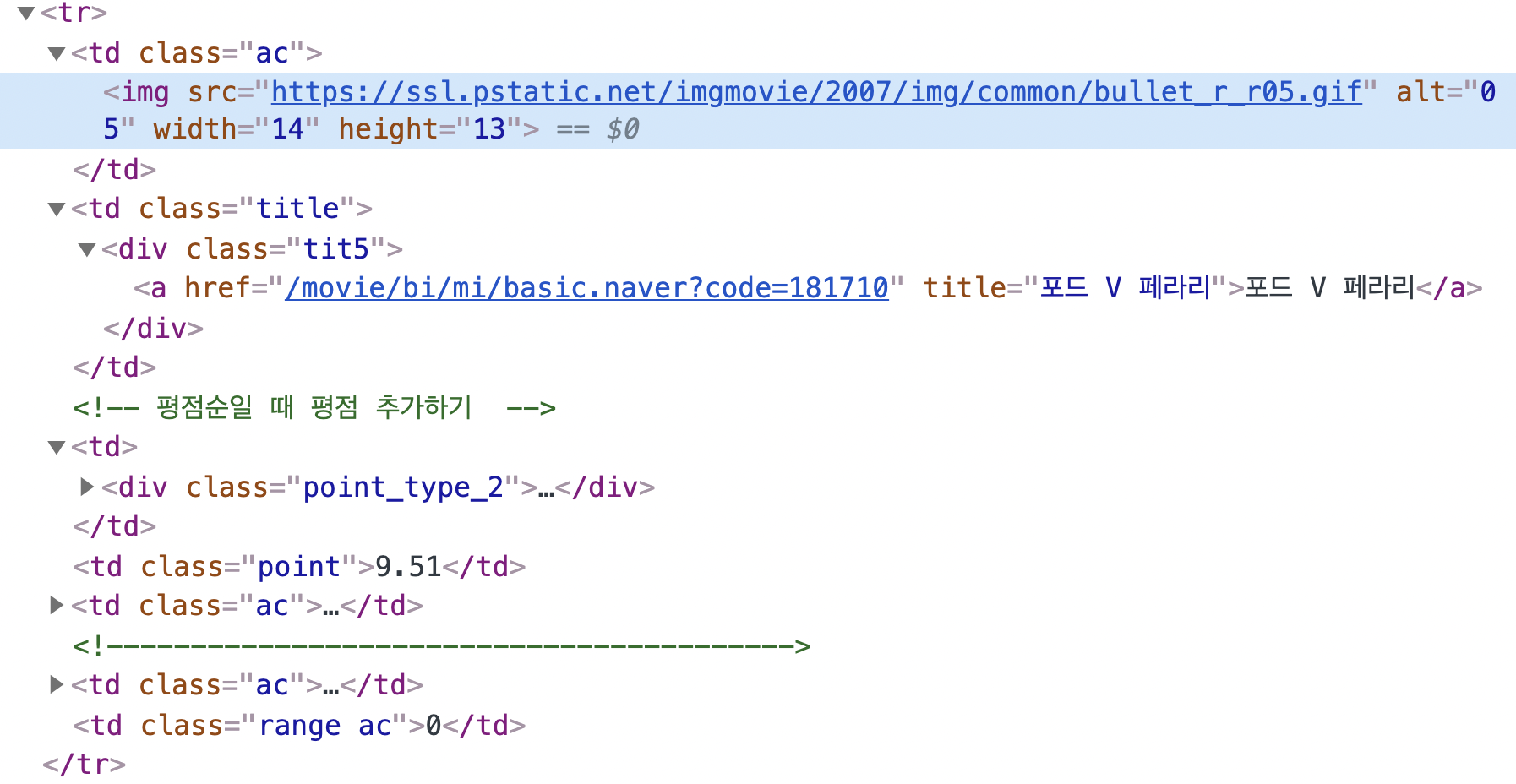
그전에 title을 a_tag에서 추출했기에 나는 rank와 star도 a_tag를 그대로 갖다 썼는데 이러면 안된다! 그 위에서 a_tag = tr.select_one('td.title > div > a')라고 변수를 썼기 때문에 a_tag는 title만을 지칭하기 때문이다. rank와 star의 값은 tr태그 안에 속하므로 a_tag 변수처럼 tr에 .select_one을 써야 한다.각각의 Copy selector
- 랭크 #old_content > table > tbody > tr:nth-child(6) > td:nth-child(1) > img
- 타이틀 #old_content > table > tbody > tr:nth-child(6) > td.title > div > a
- 별점 #old_content > table > tbody > tr:nth-child(6) > td.point
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text 중복되는 코드를 제외한 나머지 코드를 tr.select_one에 넣어준다.
⚠️ 우리의 목표는 rank와 star의 내용만을 추출하는 것이기 때문에 내용에 해당되는 'alt'와 .text(별점)도 입력한다.
01 그린 북 9.60
02 가버나움 9.59
03 베일리 어게인 9.52
04 주전장 9.52
05 포드 V 페라리 9.51
.
.
.그럼 원하는 정보만을 성공적으로 크롤링 할 수 있다😃
<img alt="01" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r01.gif" width="14"/> 그린 북 <td class="point">9.60</td>
<img alt="02" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r02.gif" width="14"/> 가버나움 <td class="point">9.59</td>
<img alt="03" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r03.gif" width="14"/> 베일리 어게인 <td class="point">9.52</td>
<img alt="04" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r04.gif" width="14"/> 주전장 <td class="point">9.52</td>
<img alt="05" height="13" src="https://ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r05.gif" width="14"/> 포드 V 페라리 <td class="point">9.51</td>
.
.
.참고로 ['alt']와 .text를 빼먹으면 이렇게 코드 전체가 출력된다.
