수포자, 문과, 비상경계 과오 청산(2)
머신러닝
머신러닝(Machine Learning)은 컴퓨터가 명시적으로 프로그래밍되지 않고도 데이터에서 패턴을 학습하고 예측을 수행할 수 있도록 하는 기술이다. 이를 통해 자동화된 의사결정을 가능하게 하며, 다양한 분야에서 활용되고 있다. 예를 들어, 온라인 쇼핑몰의 추천 시스템, 금융 사기 탐지, 의료 영상 분석 등에서 머신러닝이 광범위하게 사용된다.
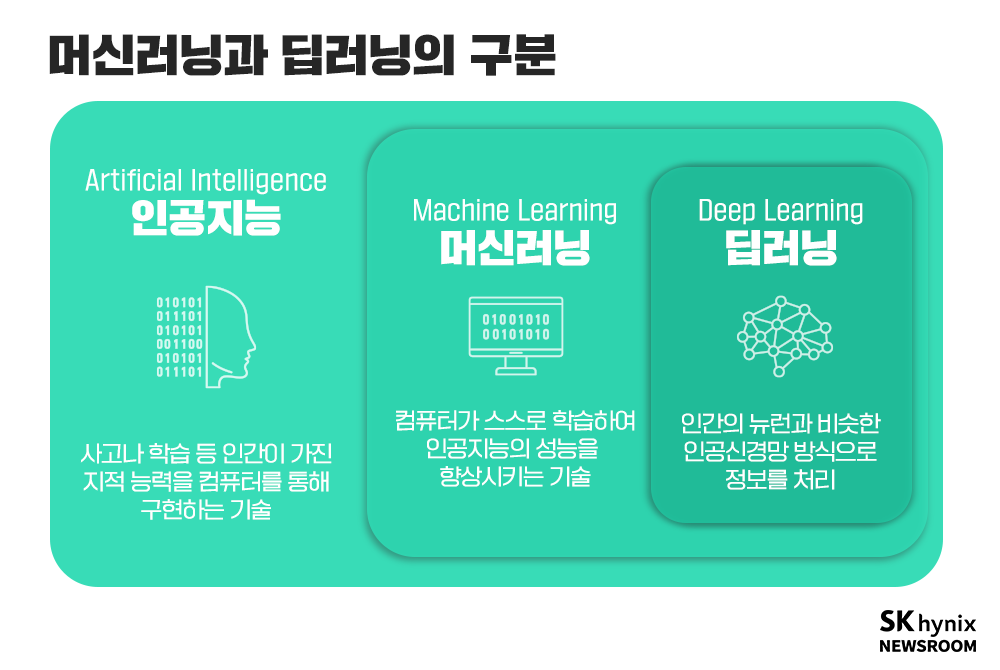
머신러닝과 AI, 딥러닝의 차이
이 세 가지는 AI 기술과 관련된 하위 개념들이며, 인간처럼 데이터를 학습하고 사고하는 기계를 만들어 보다 효율적인 의사결정과 작업 수행을 목표로 하는 공통점이 있다.
하지만 이들은 명확하게 구분되는 특성 또한 가지고 있다.
일반 사람들은 대충 AI 하나로 퉁치곤 하지만... 이들은 모두 명백히 구분되는 개념들이다.
| 구분 | 인공지능 (AI) | 머신러닝 (ML) | 딥러닝 (DL) |
|---|---|---|---|
| 정의 | 컴퓨터가 인간의 지능을 모방하도록 만드는 기술 | 데이터를 학습하여 패턴을 찾아내고 이를 기반으로 의사결정을 내리는 알고리즘 | 인공신경망(ANN)을 기반으로 데이터를 계층적으로 학습하여 스스로 판단하는 머신러닝의 하위 분야 |
| 범위 | 가장 넓은 개념 | AI의 하위 개념 | ML의 하위 개념 |
| 학습 방식 | 규칙 기반, 머신러닝 및 딥러닝 포함 | 사람이 데이터 특징(Feature)을 추출하고 알고리즘에 입력 | 특징 추출 없이 심층 신경망(Deep Neural Network)을 통해 데이터에서 직접 학습 |
| 사람 개입 | 규칙 설계 또는 알고리즘 설계에 따라 다름 | 모델 설계 및 특징 추출에 사람의 개입 필요 | 최소한의 사람 개입으로 스스로 학습 가능 |
| 적용 사례 | 자율주행, 음성인식, 챗봇 등 | 추천 시스템, 금융 사기 탐지, 이미지 분류 등 | 자율주행차, 의료 영상 분석, 자연어 처리(NLP) 등 |
| 연산 요구 | 상대적으로 적음 | 중간 수준 | 고성능 GPU와 대규모 데이터 필요 |
- 즉, AI는 가장 포괄적인 개념으로, 인간 지능 모방 기술 전체를 포함한다.
- ML은 AI의 한 갈래로, 데이터를 학습하여 패턴을 찾아내는 기술이다.
- DL은 ML의 하위 분야로, 심층 신경망을 활용해 데이터에서 스스로 학습한다.
머신러닝 프로젝트의 주요 단계
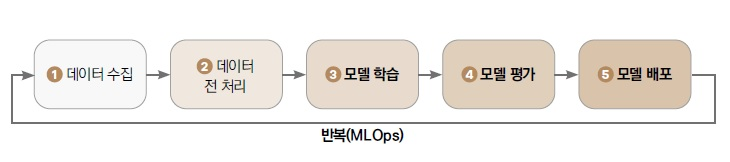
1. 데이터 수집
머신러닝 모델의 성능은 학습하는 데이터의 품질에 크게 영향을 받는다. 따라서 데이터를 적절히 수집하는 것이 가장 중요한 첫 단계이다. 데이터는 여러 경로를 통해 확보할 수 있다.
-
공개 데이터셋: Kaggle, UCI Machine Learning Repository, Google Dataset Search, Data.gov(또는 우리나라의 공공 데이터 포탈), AWS Open Data Registry 등 다양한 곳에서 제공하는 공개 데이터셋을 활용할 수 있다. 자체적으로 데이터를 수집하는 것은 많은 시간과 비용이 소모되므로, 개인 개발이나 사이드 프로젝트 등에서는 이러한 공개 데이터셋만을 활용해 개발하는 것도 고려해볼 만 하다.
-
자체 수집 데이터: 센서, 웹 스크래핑, API, 데이터베이스 등을 이용해 직접 데이터를 수집할 수 있다. 개발하려는 모델마다 필요한 데이터가 다르기 때문에, 대형 프로젝트, 혹은 특정 분야에 깊이있는 개발이 필요한 경우 자체적으로 데이터를 수집하는 경우가 많다. 실제로 요새 AI 개발의 경우 "자체 수집하고 개발한 데이터셋을 기반으로 학습을 시켰는데, 저희가 사용한 데이터셋은 극비입니다." 하는 경우가 많다 보니, 고비용에도 불구하고 이런 맞춤화된 데이터에 대한 수요는 점점 증가할 것 같다.
-
데이터 확장 기법: 데이터가 충분하지 않다면 증강(Augmentation) 기법을 사용하여 데이터의 크기를 증가시킬 수 있다. 주로 이미지나 텍스트 데이터에서 사용되며, 특정 도메인에 따라 적합성을 고려해야 한다.
2. 데이터 전처리
데이터는 종종 불완전하고 정리가 필요하다. 데이터 전처리는 모델의 성능을 높이기 위해 중요한 과정이다.
-
결측값 처리: 데이터셋에는 누락된 값이 포함될 수 있으며, 이를 처리하지 않으면 모델의 성능이 저하될 수 있다. 대표적인 방법으로는 평균, 중앙값, 최빈값으로 대체하는 방법과, 결측값이 포함된 데이터를 제거하는 방법이 있다. 그러나 이러한 처리 방법들은 데이터 손실을 초래할 수 있으므로 신중히 사용해야 한다.
-
데이터 스케일링(Min-Max Scaling) - 정규화와 표준화
: 데이터 스케일링은 일반적으로 데이터를 일정한 범위로 조정하는 모든 과정을 포함한다. 데이터 스케일링에는 여러 가지 방법이 있지만, 가장 대표적인 두 가지는 정규화와 표준화이다.-
정규화 (Normalization) : 정규화는 데이터를 일정한 범위로 조정하여 모델 학습 시 특정 특성(feature)이 다른 특성보다 지나치게 큰 영향을 미치는 것을 방지하는 데 사용된다. 주로 [0, 1] 범위로 조정한다.
- 공식:
: 여기서 X는 원래 데이터, Xmin은 데이터의 최소값, Xmax는 데이터의 최대값이다.
- 방법: Min-Max Scaling을 사용하여 각 데이터 포인트를 최소값과 최대값을 기준으로 조정한다.
- 적용 사례: 정규화는 특히 k-최근접 이웃 알고리즘 (k-NN)이나 서포트 벡터 머신 (SVM)과 같은 거리 기반 알고리즘에서 아주 유용하다. 거리 기반 알고리즘은 특성(feature) 간의 거리를 계산하여 데이터를 분석한다.
예를 들어, k-NN 알고리즘은 새로운 데이터 포인트의 분류나 회귀 값을 예측할 때, 가장 가까운 k개의 이웃 데이터 포인트와의 거리를 기준으로 해당 값을 결정한다. 이 때, 데이터셋 내의 특성들이 서로 다른 범위(스케일)를 가지면, 거리 계산에 큰 영향을 미쳐 특정 특성의 중요성이 과도하게 반영될 수 있다.
이를 방지하기 위해 정규화를 사용하면 모든 특성들이 동일한 범위([0, 1] 또는 [-1, 1]) 내에 위치하게 되어, 거리 계산 시 각 특성의 중요도가 공정하게 반영된다. 이렇게 함으로써 모델이 모든 특성을 균형 있게 고려하여 보다 정확한 예측을 수행할 수 있다.
 이를테면 이런 거다. 100점은 대체로 모든 시험에서 좋은 점수다. 아마 필자의 의도는 100점 "만점"을 받으라고 하는 거였겠지. 시도는 좋았다. 토익의 "만점"이 990점이란 걸 몰랐던 게 문제였지만...
이를테면 이런 거다. 100점은 대체로 모든 시험에서 좋은 점수다. 아마 필자의 의도는 100점 "만점"을 받으라고 하는 거였겠지. 시도는 좋았다. 토익의 "만점"이 990점이란 걸 몰랐던 게 문제였지만...- Min-Max 정규화는 최소값과 최대값에 민감하다는 단점이 있다. 이상치(outlier : 극단적으로 높거나 낮은 값)가 존재할 경우 스케일링 결과에 큰 영향을 미칠 수 있으므로, 이상치 처리가 필요하다. 예를 들어, [1, 2, 3, 100]처럼 이상치가 있는 데이터는 Min-Max Scaling 후 [0, 0.01, 0.02, 1]로 변환되어 대부분의 데이터가 매우 작은 값으로 압축될 수 있다.
- 공식:
-
표준화(Standardization) : 표준화는 데이터를 평균 0, 표준편차 1로 변환하여 모든 특성이 동일한 스케일에서 작동하도록 한다. 이는 특성 간의 분포를 균일하게 만들어 모델 학습을 돕는다.
- 공식:
: 여기서 (X)는 원래 데이터, µ는 데이터의 평균, (\sigma)는 데이터의 표준편차이다.
- 방법: Z-score Scaling을 사용하여 각 데이터 포인트를 평균과 표준편차를 기준으로 조정한다.
- 적용 사례: 표준화는 회귀 분석이나 신경망과 같은 알고리즘에서 특히 유용하다. 이러한 알고리즘은 데이터가 정규 분포를 따른다고 가정하는 경우가 많기 때문에, 표준화를 통해 데이터의 평균을 0, 표준편차를 1로 조정하여 정규 분포에 가깝게 만든다. 이렇게 하면 모델의 학습이 더욱 효과적이고 빠르게 이루어질 수 있다. 또한, 표준화를 통해 데이터의 스케일이 균일해지면, 모델이 각 특성을 공정하게 반영하여 더욱 정확한 예측을 수행할 수 있다.
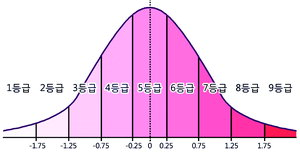
국민평균이 5등급이라고 주장하는 근거가 종종 되는수능 등급의 정규분포 그래프이다. 수능 등급은 각 과목의 성적을 표준화하여 학생들의 성적을 상대적으로 비교하는 방식이다. 각 과목의 원점수를 평균과 표준편차를 이용해 표준 점수로 변환한 후, 이를 기준으로 등급을 매긴다. 그래서 어떤 과목은 1점 차이로 등급이 갈리고(불수능), 어떤 과목은 더 큰 차이가 나도 같은 등급이기도 한 거다(물수능).- Z-score Scaling은 데이터가 정규 분포를 따르지 않을 경우 효과가 제한적일 수 있다. 따라서 데이터 분포를 먼저 확인하고 정규화 여부를 결정해야 한다. 또한, 딥러닝 모델에서는 Z-score Scaling 대신 Batch Normalization 같은 기법이 사용되기도 한다.
- 공식:
-
-
차원 축소 (Dimensionality Reduction): 차원 축소 과정은 고차원 데이터를 낮은 차원으로 변환하여 중요한 정보만 유지하고 불필요한 노이즈를 제거하는 작업을 수행한다. 이를 통해 연산 효율성을 높이고 과적합을 방지할 수 있다.
대표적인 예로는 PCA, t-SNE, UMAP 이 있다.
- PCA : (Principal Component Analysis): 선형 변환 기법으로, 데이터의 분산을 최대한 설명하는 주성분을 찾아 데이터를 변환한다. 단점으로는 일부 정보 손실이 발생할 수 있으며, 비선형 구조를 다루지 못한다는 한계가 있다.
- t-SNE : (t-Distributed Stochastic Neighbor Embedding): 비선형 차원 축소 기법으로, 데이터의 고차원 구조를 저차원 공간에 보존하는 것에 집중한다. 클러스터 시각화에 유리하나, 전역 구조를 잘 보존하지 않고 실행 속도가 비교적 느리다.
- UMAP (Uniform Manifold Approximation and Projection): 데이터의 구조를 저차원 공간에 보존하는 또 다른 비선형 차원 축소 기법이다. 전역 및 지역 구조를 모두 보존하며, 더 빠르고 큰 데이터셋에 대해 확장성이 좋다.참고 : 머신러닝 모델 중 일부(예: 트리 기반 모델인 결정 트리, 랜덤 포레스트 등)는 스케일링이나 차원 축소에 크게 의존하지 않는다. 이는 알고리즘의 특성에 따라 스케일링 및 차원 축소 필요성이 다르다는 점을 보여준다.
3. 모델 학습
머신러닝 알고리즘을 선택하고 데이터를 학습시키는 단계이다.
-
훈련 데이터(Training Set): 모델을 학습시키는 데 사용하는 데이터이다.
-
검증 데이터(Validation Set): 모델의 성능을 평가하고 하이퍼파라미터를 조정하는 데 사용한다.
-
테스트 데이터(Test Set): 최종적으로 모델의 성능을 평가하는 데이터이다.
훈련:검증:테스트 비율은 6:2:2 또는 8:1:1로 나뉘는 경우가 많다. 상황에 따라 조정이 필요하다.
4. 모델 평가 및 개선
모델이 실제 환경에서 잘 동작하는지 확인하는 과정이 필요하다. 이를 위해 여러 평가 지표가 사용된다.
-
회귀 모델 평가 지표:
-
MSE(Mean Squared Error): 예측값과 실제값 간의 평균 제곱 오차를 계산한다.
-
RMSE(Root Mean Squared Error): MSE의 제곱근을 취해 값을 원래 스케일로 복원해 해석하기 쉽다.
-
R²(결정 계수): 모델이 데이터를 얼마나 잘 설명하는지 나타내는 지표다.
-
-
분류 모델 평가 지표:
-
정확도(Accuracy): 전체 예측 중에서 맞춘 비율을 나타낸다.
-
정밀도(Precision): 양성 예측 중 실제 양성의 비율을 나타낸다.
-
재현율(Recall): 실제 양성 중에서 맞춘 비율을 나타낸다.
-
F1-score: 정밀도와 재현율의 조화 평균이다.
-
ROC 곡선과 AUC(Area Under Curve): 모델의 분류 성능을 요약하는 중요한 지표이다.
-
-
모델의 성능이 만족스럽지 않다면 하이퍼파라미터 튜닝, 데이터 확장, 특성 선택(feature selection) 및 특성 생성(feature engineering) 등의 방법을 사용해 개선할 수 있다.
참고
- 데이터 탐색적 분석(EDA): 전처리와 학습 사이에 EDA를 통해 변수 간 상관관계 및 분포를 시각화하는 과정이 중요하다.
- 실시간 데이터 처리: 실시간 데이터를 다룰 경우 스트리밍 방식으로 데이터를 수집하고 전처리하는 방법론도 고려해야 한다.
