수포자, 문과, 비상경계 과오 청산(3)
머신러닝에서의 회귀 분석 - 선형 회귀, 로지스틱 회귀
회귀 분석이란?
회귀 분석(Regression Analysis)이란 데이터를 기반으로 변수들 간의 관계를 찾아내고 이를 이용해 미래 값을 예측하는 통계 기법이다. 쉽게 말해, 과거 데이터를 보고 "어떤 패턴이 있나?"를 분석하여 "다음엔 어떻게 될까?"를 예측하는 것이다.
예를 들어, 아이스크림 가게 주인이 있다면, 기온과 아이스크림 판매량 사이의 관계를 분석할 수 있다. 즉, 기온이 올라갈수록 아이스크림이 더 많이 팔리는 패턴이 존재한다면, 기온을 독립 변수(입력값)로 설정하고 아이스크림 판매량을 종속 변수(출력값)로 설정하여 향후 판매량을 예측할 수 있다.
실생활에서의 회귀 분석 활용 사례
-
선형 회귀 적용 사례:
- 부동산 시장에서 면적과 아파트 가격 간의 관계를 분석하여 향후 특정 면적의 아파트 가격을 예측하는 데 사용될 수 있다.
- 예측 대상(아파트 가격)이 연속적인 숫자로 나타나므로 선형 회귀가 적합하다.
-
로지스틱 회귀 적용 사례:
- 대출 신청자의 신용 점수, 연 소득, 부채 비율 등을 분석하여 대출 승인 여부를 예측할 때 사용된다.
- 예측 대상(승인 또는 거절)이 두 가지 범주로 나뉘므로 로지스틱 회귀가 적절하다.
회귀 분석의 종류: 선형 회귀 vs 로지스틱 회귀
선형 회귀란?
선형 회귀(Linear Regression)는 데이터 간의 관계를 직선(y = ax + b)으로 표현하는 기법이다. 즉, 독립 변수(x)가 변화할 때 종속 변수(y)가 일정한 비율로 변한다고 가정하는 모델이다. 선형 회귀는 단순 선형 회귀와 다중 선형 회귀로 나뉜다:
- 단순 선형 회귀 (Simple Linear Regression): 하나의 독립 변수와 하나의 종속 변수 간의 선형 관계를 분석한다.
- 다중 선형 회귀 (Multiple Linear Regression): 여러 개의 독립 변수와 하나의 종속 변수 간의 선형 관계를 분석한다.
선형 방정식을 이용한 예측
선형 회귀 모델의 기본 수식은 다음과 같다.
이때, 각 변수들은 아래의 의미를 지닌다.
- : 예측하고자 하는 값(종속 변수)
- : 입력 변수(독립 변수)
- : 각 독립 변수의 가중치(회귀 계수)
- : 절편(바이어스)
비용 함수와 최소제곱법
모델이 예측한 값과 실제 값의 차이를 최소화하기 위해 평균제곱오차(Mean Squared Error, MSE)를 비용 함수로 사용한다.
여기서
- : 실제 값
- : 예측 값
- : 데이터 샘플 개수
경사 하강법(Gradient Descent)을 이용해 비용 함수가 최소가 되는 최적의 회귀 계수를 찾는다.
MSE 외의 비용 함수
- 평균절대오차(MAE, Mean Absolute Error): 이상치에 덜 민감하지만, 최적화 과정에서 미분 불가능한 점이 있어 경사 하강법 적용 시 주의가 필요하다.
- Huber Loss: MSE와 MAE의 장점을 결합하여 이상치에 대한 민감도를 조정한다.
다중 회귀 모델로의 확장
다중 독립 변수 처리
단순 선형 회귀는 하나의 독립 변수만을 다루지만, 다중 회귀(Multiple Regression)는 여러 개의 독립 변수를 활용하여 예측한다.
예를 들어, 아파트 가격을 예측할 때 면적, 층수, 위치 등의 여러 요인을 고려할 수 있다.
다중공선성 문제 해결
다중공선성(Multicollinearity)이란 독립 변수들 사이의 강한 상관관계로 인해 회귀 모델이 불안정해지는 문제를 의미한다. 다중공선성이 존재하면 회귀 계수의 신뢰성이 떨어지고, 예측 모델의 성능이 저하될 수 있다.
다중공선성을 해결하는 방법
- VIF(Variance Inflation Factor) 분석: VIF 값이 높은 변수는 다른 변수와 강한 상관관계를 가지므로 제거하거나 수정할 필요가 있다.
- 주성분 분석(PCA): 여러 변수들을 결합하여 대표적인 몇 개의 변수로 차원을 축소하는 기법이다.
- 릿지(Ridge) 및 라쏘(Lasso) 회귀 적용: L2 정규화(Ridge)와 L1 정규화(Lasso)를 사용하여 회귀 계수를 조정하고, 다중공선성을 완화할 수 있다.
로지스틱 회귀란?
로지스틱 회귀(Logistic Regression)는 종속 변수가 연속적인 값이 아니라 이진(0 또는 1) 혹은 다중 클래스 값(예: 강수량 예측에서 '비 옴', '비 안 옴', '이슬비')을 가질 때 사용된다. 로지스틱 회귀는 선형 모델 기반의 분류 기법으로, 이진 분류 외에도 다중 클래스 분류(Multinomial Logistic Regression)로 확장 가능하다.
시그모이드 함수의 원리
이 함수는 입력값을 0과 1 사이의 확률로 변환해준다. 일정 임계값(예: 0.5) 이상이면 1, 미만이면 0으로 분류한다.
로지스틱 회귀의 손실 함수
- 이진 교차 엔트로피(Binary Cross Entropy): 분류 문제에서 가장 널리 사용되는 손실 함수로, 확률값과 실제 라벨 간 차이를 최소화한다.
분류 모델 성능 평가 지표
- 정확도(Accuracy): 전체 샘플 중 정확하게 예측된 비율
- 정밀도(Precision): 모델이 '긍정' 클래스로 예측한 샘플 중 실제로 긍정인 비율
- 재현율(Recall): 실제 긍정 샘플 중 모델이 긍정으로 예측한 비율
- F1-score: 정밀도와 재현율의 조화 평균으로 불균형 데이터에서 유용
- ROC-AUC: 모델의 분류 성능을 평가하는 곡선으로, 1에 가까울수록 좋은 성능을 나타낸다. 특히 데이터가 불균형할 때 유용하다. 불균형 데이터에서는 Precision-Recall Curve도 유용하다.
비선형 관계 모델링
비선형 데이터를 모델링하려면 다항 회귀(Polynomial Regression)나 커널 트릭(Kernel Trick)을 사용할 수 있다. 이를 통해 복잡한 비선형 관계도 예측할 수 있다. 여기까지 다루면 내용이 너무 복잡해져서, 다른 포스팅에서 다뤄야 할 것 같다.
Python 실습
# 데이터 분석을 위한 라이브러리로, 데이터프레임을 사용하여 데이터 조작 및 분석을 간편하게 수행할 수 있게 해준다.
pip install pandas
- 선형 회귀 실습
- 부동산 시장에서 아파트의 면적과 가격 간의 관계를 분석하여, 면적을 입력으로 받아 아파트 가격을 예측하는 모델을 만들어보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 가상의 부동산 데이터 생성
np.random.seed(42) # 난수 생성을 위한 시드 설정
area = np.random.rand(100) * 200 # 0에서 200 사이의 면적 데이터 생성
price = 100 + 3000 * area + np.random.randn(100) * 10000 # 가격 데이터 생성 (100 + 3000 * 면적 + 노이즈)
# 데이터프레임 생성
df = pd.DataFrame({'Area': area, 'Price': price}) # 면적과 가격 데이터를 데이터프레임으로 생성
# 데이터 시각화
plt.scatter(df['Area'], df['Price'], color="blue", label="Actual Data") # 실제 데이터 시각화 (파란 점)
plt.xlabel("Area (sq ft)") # x축 라벨 설정
plt.ylabel("Price (USD)") # y축 라벨 설정
plt.title("Housing Prices") # 그래프 제목 설정
plt.legend() # 범례 표시
plt.show() # 그래프 출력
# 선형 회귀 모델 학습
X = df[['Area']] # 입력 변수 (면적) 추출
y = df['Price'] # 출력 변수 (가격) 추출
lin_reg = LinearRegression() # 선형 회귀 모델 객체 생성
lin_reg.fit(X, y) # 모델 학습 (면적을 입력으로 가격 예측)
y_pred = lin_reg.predict(X) # 예측 값 계산
# 선형 회귀 결과 시각화
plt.scatter(df['Area'], df['Price'], color="blue", label="Actual Data") # 실제 데이터 시각화 (파란 점)
plt.plot(df['Area'], y_pred, color="red", label="Predicted Line") # 예측된 직선 시각화 (빨간 선)
plt.xlabel("Area (sq ft)") # x축 라벨 설정
plt.ylabel("Price (USD)") # y축 라벨 설정
plt.title("Linear Regression for Housing Prices") # 그래프 제목 설정
plt.legend() # 범례 표시
plt.show() # 그래프 출력
# 선형 회귀 해석
print(f"회귀 계수: {lin_reg.coef_[0]}, 절편: {lin_reg.intercept_}") # 회귀 계수와 절편 출력
print(f"MSE: {mean_squared_error(y, y_pred)}") # 평균제곱오차 (MSE) 출력- 로지스틱 회귀 실습
- 대출 신청자의 신용 점수, 연 소득, 부채 비율 등을 분석하여 대출 승인 여부를 예측하는 모델을 만들어보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_curve, auc
from sklearn.model_selection import train_test_split
# 가상의 대출 데이터 생성
np.random.seed(42) # 난수 생성을 위한 시드 설정
credit_score = np.random.rand(100) * 800 # 0에서 800 사이의 신용 점수 데이터 생성
annual_income = np.random.rand(100) * 100000 # 0에서 10만 달러 사이의 연 소득 데이터 생성
debt_ratio = np.random.rand(100) # 0에서 1 사이의 부채 비율 데이터 생성
approved = (credit_score / 800 + annual_income / 100000 - debt_ratio > 1).astype(int) # 대출 승인 여부 결정 (1: 승인, 0: 거절)
# 데이터프레임 생성
df = pd.DataFrame({'CreditScore': credit_score, 'AnnualIncome': annual_income, 'DebtRatio': debt_ratio, 'Approved': approved}) # 데이터프레임 생성
# 데이터 분할
X = df[['CreditScore', 'AnnualIncome', 'DebtRatio']] # 입력 변수 추출 (신용 점수, 연 소득, 부채 비율)
y = df['Approved'] # 출력 변수 추출 (대출 승인 여부)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 학습 데이터와 테스트 데이터로 분할
# 로지스틱 회귀 모델 학습
log_reg = LogisticRegression() # 로지스틱 회귀 모델 객체 생성
log_reg.fit(X_train, y_train) # 모델 학습
# 예측 및 평가
y_prob = log_reg.predict_proba(X_test)[:, 1] # 각 샘플이 클래스 1일 확률 계산
y_pred = log_reg.predict(X_test) # 예측 클래스 계산
# 성능 평가 지표 출력
accuracy = accuracy_score(y_test, y_pred) # 정확도 계산
print(f"정확도: {accuracy}") # 정확도 출력
# ROC-AUC 시각화
fpr, tpr, _ = roc_curve(y_test, y_prob) # ROC 곡선 계산
roc_auc = auc(fpr, tpr) # AUC 값 계산
plt.plot(fpr, tpr, color="blue", label=f"ROC curve (area = {roc_auc:.2f})") # ROC 곡선 시각화
plt.plot([0, 1], [0, 1], color="gray", linestyle="--") # 대각선(무작위 예측) 시각화
plt.xlabel("False Positive Rate") # x축 라벨 설정
plt.ylabel("True Positive Rate") # y축 라벨 설정
plt.title("ROC Curve for Loan Approval Prediction") # 그래프 제목 설정
plt.legend() # 범례 표시
plt.show() # 그래프 출력
코드 해석 및 시각화
1)
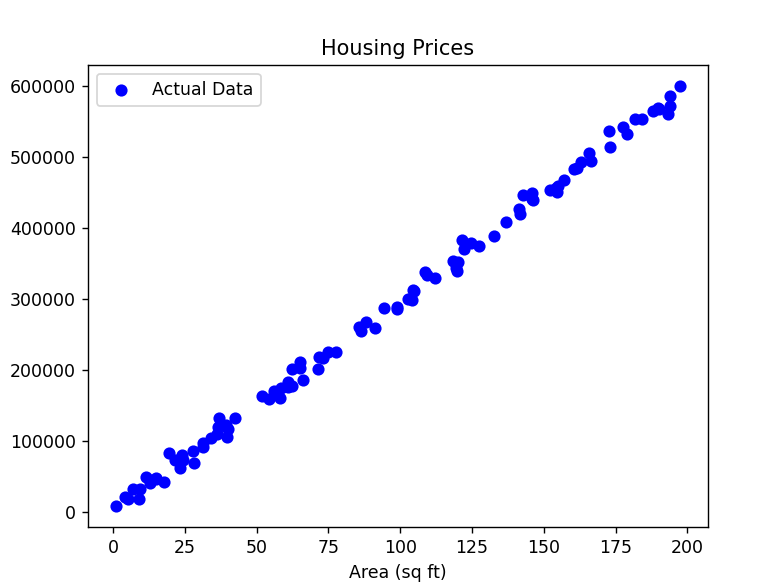
그래프 해석
- 실제 데이터 시각화:
- 파란 점: 각 점은 면적(입력 변수)과 그에 따른 실제 가격(출력 변수)을 나타낸다. 점들의 분포를 통해 데이터가 어떤 패턴으로 분포되어 있는지 시각적으로 확인할 수 있다. (가상의 데이터이지만) 면적이 증가할수록 가격도 대체로 증가하는 패턴이 관찰된다.
- 선형 회귀 결과 시각화:
- 빨간 선: 선형 회귀 모델이 예측한 직선이다. 이 선은 데이터의 패턴을 가장 잘 설명하는 직선이다. 해당 직선을 통해 면적이 특정 값일 때 가격이 얼마가 될지를 빨간 선을 통해 추정할 수 있다.
- 모델 성능 평가:
- 회귀 계수와 절편:
- 회귀 계수(기울기):
lin_reg.coef_[0]값은 면적이 1 단위 증가할 때 가격이 얼마만큼 증가하는지를 나타낸다.- 절편:
lin_reg.intercept_값은 면적이 0일 때의 기본 가격을 나타낸다.- 평균 제곱 오차(MSE): 예측 값과 실제 값 간의 오차 제곱 평균을 나타낸다. 값이 작을수록 모델의 예측 성능이 좋음을 의미한다.
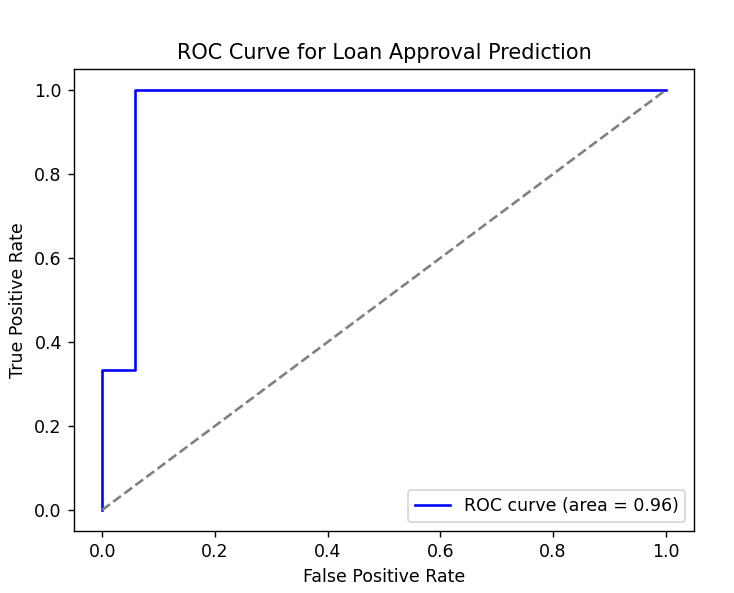
2)
1. ROC-AUC 시각화:
- ROC 곡선: 파란색 곡선으로 표시된 ROC 곡선은 모델의 분류 능력을 시각화하여 모델의 성능을 평가하는 데 사용된다. ROC 곡선은 x축에 거짓 긍정 비율(False Positive Rate), y축에 진정 긍정 비율(True Positive Rate)을 나타낸다. 곡선 아래의 면적(AUC)이 클수록 모델의 성능이 좋음을 의미한다.
- 대각선(회색 점선): 무작위로 예측한 모델의 성능을 나타낸다. 파란 곡선이 이 대각선보다 위에 위치할수록 모델의 성능이 우수함을 나타낸다.
- 모델 성능 평가:
- 정확도:
accuracy_score(y_test, y_pred)값은 전체 샘플 중 정확하게 예측된 비율을 나타낸다. 값이 높을수록 모델의 예측 성능이 좋음을 의미한다.- AUC 값:
auc(fpr, tpr)값은 ROC 곡선 아래의 면적을 나타내며, 1에 가까울수록 모델의 성능이 좋음을 나타낸다.
정리하자면
- 선형 회귀에서는 부동산의 면적과 가격 간의 관계를 직선으로 모델링하여 예측해 보았다. 빨간 선이 데이터의 패턴을 잘 설명하고 있으며, MSE를 통해 모델의 예측 성능을 평가할 수 있다.
- 로지스틱 회귀에서는 대출 승인 여부를 예측하는 모델의 성능을 ROC 곡선을 통해 평가해 보았다. ROC 곡선과 AUC 값이 모델의 분류 성능을 나타내며, 정확도를 통해 전체 예측 성능을 확인할 수 있다.
편의상 가상 데이터를 사용했지만(그래서 그래프가 너무 이상적으로 나왔지만...), 실제 서비스의 개발을 목적으로 한다면 저번 포스팅에서 소개했던 공개 데이터를 활용해봐도 좋을 것 같다.
