
오늘 배운 것
조금 더 복잡한 동적페이지 크롤링
- 요청 한 번으로 데이터를 온전히 받아올 수 있는 경우는 사실 많지 않다.
- 이 경우 최종 목표 데이터로부터 거슬러 올라가면서 데이터의 흐름을 찾아야 한다.
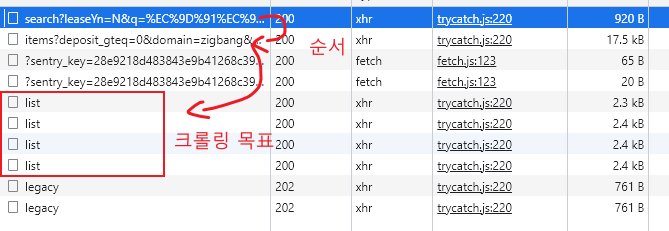
요청 및 필요 파라미터를 찾는 팁
- 동적페이지의 경우 개발자도구의 네트워크 탭에서
Fetch/XHR을 보면 JSON 이나 XML을 통해 데이터를 받아온 내역을 볼 수 있다.- Payloads를 통해 요청을 보낼 때 어떤 데이터를 담아 보냈는지 확인 할 수 있다.
- Preview 또는 Response를 통해 어떤 데이터를 받아오는지 확인 할 수 있다.
geohash2
geohash2는 위도, 경도의 특정 좌표를 영역을 나타내는 문자열 좌표로 변환해주는 패키지이다.
geohash = geohash2.encode(위도, 경도, precision=5)- precision은 출력될 문자열의 길이를 나타낸다.
최대 12까지 설정할 수 있으며, 문자열이 길수록 좁은 범위를 갖는다. (더 자세한 위치를 표현할 수 있으므로)
- precision은 출력될 문자열의 길이를 나타낸다.
정적페이지 크롤링을 위한 HTML, CSS 지식
이미 알고 있는 내용이 많으므로 필요한 개념 위주로 짚고 가자
HTML 구성 요소 (용어)
- Document : 한 페이지 전체를 나타내는 단위
- Element : 하나의 레이아웃을 나타내는 단위
- 시작태그, 끝태그, 테스트로 구성된다.
<div>텍스트</div>이런 형식
- Tag : 엘리먼트의 종류를 정의 및 구분
- Attribute : 태그의 특정 기능을 하는 값으로, 시작태그에 작성된다.
태그의 종류
- pre 태그 : 줄바꿈이나 띄어쓰기가 적용되는 태그로, 드물게 사용된다.
- iframe 태그 : 외부 url 페이지를 보여주기 위한 태그이다.
- src 속성을 통해 url을 지정하여 보여줄 수 있다.
- input 태그 : 사용자로부터 무언가를 입력받는 태그로, type 속성에 따라 입력받는 형태가 다르다.
- 종종 무언가를 누르거나 입력해야 데이터가 표시되는 경우가 있기 때문에 크롤링 때 종종 선택해서 사용한다.
- select 태그 : 옵션 선택을 할 수 있는 드랍 다운 태그
정적페이지 크롤링 실습
BeautifulSoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)-
HTML 문서를 크롤링하면 문자열 형태로 받아오게 되는데,
BeautifulSoup라는 클래스를 이용하여 파싱할 수 있다. -
soup.select('CSS 선택자')메서드를 이용하여 CSS 선택자로 원하는 Element를 선택할 수 있다.- 한 번에 여러개를 받아올 수 있지만 값이 무조건 리스트에 담긴다.
- 한 개의 엘리멘트롤 받고 싶으면
select_one메서드를 이용할 수 있다.
-
soup.text로 엘리먼트의 텍스트를 추출할 수 있다. -
soup.get('attr')메서드를 이용하여 엘리먼트의 속성값에 접근할 수 있다.
이미지 처리
from PIL import Image as pil
pil.open('경로명.확장자')파이썬에서 이미지를 처리하기위해서는 Pillow 패키지가 필요하다.
lazyload 개념
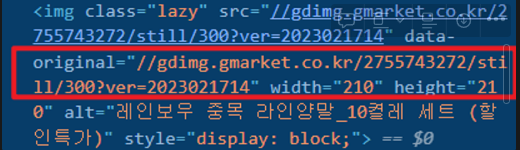
- lazyload란 웹페이지의 모든 요소를 한번에 로딩(다운로드)하지 않고, 보이는 만큼만 로딩하는 것을 말한다.
- 나머지 요소는 화면에 들어오려 할 때 로딩된다.
- 크롤링 시 lazyload 요소에 접근하면 크롤링이 이루어지지 않으므로, 오리지널 부분을 찾아 가져와야 한다. (사진에서 data-original)
복습
복습을 위해 스탯티즈 홈페이지에서 순위 정보를 크롤링 해보았다.
import requests
import pandas as pd
from bs4 import BeautifulSoup
# 1. url (생략)
# 2. request(url) > response : html(str)
response = requests.get(url)
response
# 3. html(str) > data(soup)
data = BeautifulSoup(response.text)
# 4. data(soup) > dict, list
dfs = []
for n in range(4, 14):
team = data.select_one(f"#mytable > tr:nth-child({n})")
if team:
team_data = team.select("td")
team_dict = {
"구단명" : team_data[1].text,
"순위" : team_data[0].text,
"WAR" : team_data[3].text,
"홈런" : team_data[11].text,
"타점" : team_data[13].text,
"도루" : team_data[14].text,
"타율" : team_data[23].text,
"출루" : team_data[24].text,
"OPS" : team_data[26].text,
"WRC+" : team_data[28].text,
"WPA" : team_data[30].text,
}
dfs.append(team_dict)
# 5. dict, list > DataFrame
df = pd.DataFrame(dfs)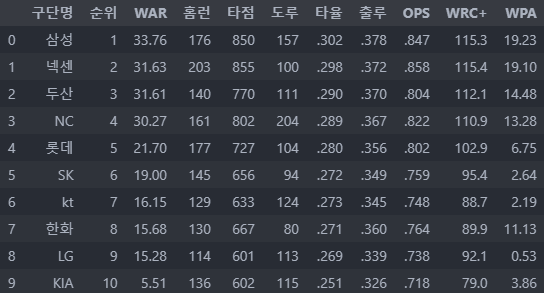
- 클래스나 id가 거의 없어서 당황했는데, 어찌어찌 잘 가져왔다.
셀레니움 개념 및 실습
개념
-
셀레니움은 자동화를 위해 브라우저를 프로그래밍 언어로 컨트롤하는 라이브러이다.
-
파이썬 뿐만 아니라 다른 언어에서도 사용이 가능하다.
-
크롤링에서는 봇을 차단하는 웹사이트에 접근하기 위해 사용한다. (직접 브라우저를 실행해 접근하므로)
사용법
- 크롬을 사용할 경우, 크롬 드라이버가 필요하다.
- 드라이버를 다운 받아 셀레니움을 사용할 코드가 있는 디렉토리에 같이 넣어주면 된다.
- 또는 크롬 드라이버를 환경 변수에 등록하는 방법이 있는데, 윈도우에서는 오류가 잦아 권장되지 않는다.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()- 이렇게 드라이버를 선언하면 driver 객체를 통해 브라우저를 조종할 수 있다.
브라우저 제어
- 엘리먼트 탐색 :
driver.find_element(By.CSS_SELECTOR, "css selector")- send_keys('텍스트') : 해당 엘리먼트에 텍스트를 입력
- click() : 해당 엘리먼트를 클릭
- 자바스크립트 코드 사용 :
driver.execute_script("스크립트")window.scrollTo(a, b);과 같은 JS 코드를 사용해 스크롤 조절이 가능하다.- 셀레니움에서는 브라우저 창에 들어오지 않는 요소는 가져올 수 없기 때문에 이런 스크롤 조정이 필요하다.
- 종료 :
driver.quit()
xpath
css 선택자와 동일한 역할을 한다.
//*[@id="shoji"]/div[2]/div/div[2]/header/div/div[1]
//: document의 최상위 엘리먼트를 의미/: 한단계 아래 엘리먼트를 의미*: 모든 하위 엘리먼트를 의미 (css selector에서 공백과 같은 의미)[@id="shoji"]: 속성값으로 엘리먼트 선택 (id값이 shoji인 엘리먼트)div[2]: 태그[n번째] - 1부터 시작
driver.find_element(By.XPATH, "xpath")를 통해 사용할 수 있다.
Headless Selenium
서버 컴퓨터와 같이 화면이 없는 브라우저에서는 창을 띄워 브라우징하는 것이 불가능하다.
이 때, 메모리상에만 화면을 띄우는 방법이 있는데 이를 headless 라고 한다.
headless 옵션을 설정하는 것을 통해 쉽게 사용할 수 있다.
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(options=options)코멘트
-
곧 미니프로젝트가 있는데, 프로젝트에 쓰일 데이터를 크롤링을 통해 최대한 많이 모으면 좋을 것 같다.
-
수업 도중에 정규표현식, 파이썬의 PEP 문서, xpath, 스페셜커맨드 등 다양한 개념을 추가로 배울 수 있었는데, 이번 주말에 조금 더 자세히 공부해봐야겠다.
