
무엇을 했나?
미션
- 미세먼지 농도 예측 머신러닝 모델링
목표
- 머신러닝을 통해 1시간 뒤의 미세먼지 농도를 예측하는 모델을 완성한다.
CRISP-DM
- 비즈니스의 이해 -> 데이터 탐색 ->데이터 전처리 -> 모델링 -> 평가 ->
배포
모델링 과정
- 알고리즘 선택 -> 하이퍼파라미터 튜닝 -> 모델 완성
1일차는 굵게 표시된 과정을 실습을 통해 체득하는 과정이다.
1. 강의를 통해 비즈니스를 이해하고
2. 직접 데이터 전처리를 수행하며
3. 모델링을 완성하여 예측 및 평가를 수행한다.
프로젝트 수행
- 강사의 도움 및 예제 코드 없이 스스로의 힘으로 데이터 전처리와 모델링 과정을 수행한다.
- 공통적인 방향성을 위한 간단한 가이드라인이 제공된다.
0. 데이터 탐색
- 이번 과정은 데이터 탐색을 익히는 것이 목적이 아니므로, 데이터 탐색에 한해 예제 코드가 제공된다.
- 변수 확인 및 데이터 분포 확인 정도의 기본적인 과정만 수행하였다.
1. 전처리
- 공공데이터로 제공되는 raw 데이터를 가공하여 모델링에 적합한 데이터로 변환
- 날짜 데이터를 포맷에 맞게 datetime으로 변환
- 결측치 제거 및 처리
- 의미 없는 요인 드랍
- 두 개의 데이터프레임을 merge하여 하나의 csv로 출력
- (추가학습) 가설을 바탕으로 새로운 변수 생성
- 0~360도 방위로 제공되는 풍향 데이터를 동풍, 남풍, 서풍, 북풍의 범주값으로 변환 및 가변수화
- 결측치 비율이 높은 강수량 변수를 강수여부(binary class)로 재가공
2. 모델링
- 다양한 모델의 성능 비교
- Linear Regressor
- Random Forest
- GBM(Gradient Boosting Algorithm)
- Feature Importance 시각화
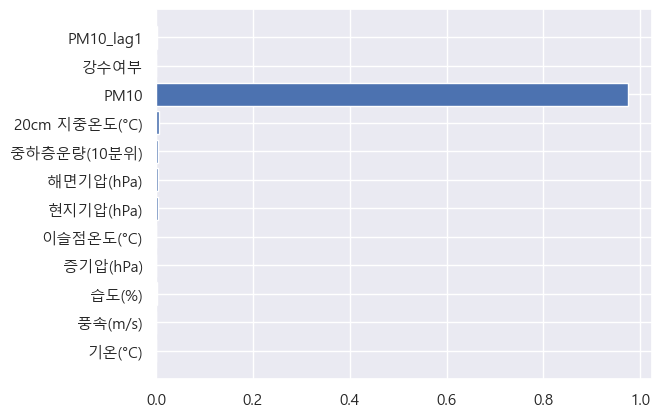
- 불과 1시간 뒤의 값을 예측하는 것이기 때문에, 대부분 현재 농도의 영향을 받는 것으로 나타났다.
- 6시간 뒤 값을 예측했을 때, 모델 성능이 크게 줄어들어 나머지 변수는 성능에 큰 도움이 되지 않았다고 우선 결론을 내렸다.
- 모델을 pickle 파일로 출력
- joblib 모듈의 dump 함수를 이용하여 학습한 모델을 pkl 파일로 출력하였다.
소감
좋았던 점
- 아웃풋은 평범했지만 나름 결론과 인사이트를 도출하여 발표까지 잘 진행하였다.
- 데이터 전처리 과정에서 나름 다양한 시도를 해보았다. 비록 의미있는 요인을 도출하지는 못했지만 데이터 전처리 연습에 큰 도움이 되었다.
아쉬웠던 점
-
데이터 탐색을 잘 다루지 않는 과정이었다고는 하나, 데이터 간의 상관관계 분석, 박스 플롯 등의 기본적인 데이터 탐색은 했어야 한다고 생각한다. 만약 데이터 탐색을 꼼꼼히 했으면 전처리 때 더 좋은 인사이트를 도출할 수 있었을 것이다.
-
모델링 과정을 함수화 했다면 더 빠르게 많은 알고리즘을 살펴 볼 수 있었을 것이다. 하나하나 따로 하다보니 작업이 비효율적이었다.
-
머신러닝 알고리즘에 대한 지식이 적다보니 시도해 볼 수 있는 알고리즘과 튜닝 방법이 한정적인 것 같다. 이부분을 공부해서 보완해야 할 것이다.
