
무엇을 했나?
이론 정리
카운트 기반의 단어 표현
- 모델링을 위한 데이터 전처리의 목적은 바로 단어의 수치화이다. 그 중 카운트 기반의 단어 표현은 단어의 출현 빈도에 집중한 표현이다.
Bag of words
-
you know I want your love. because I love you. -
다음의 문장을 아래와 같이 나타낼 수 있다.
단어 벡터 : [2, 1, 2, 1, 2, 1, 1]
단어 사전 : {you : 0, know : 1 , I : 2, want : 3, love : 4, because : 5, your : 6}- Bag of words는 문장 또는 문서의 단어를 빈도수를 이용한 벡터를 나타내고, 각 벡터가 어떤 단어를 가리키는지 인덱스를 통해 파악한다.
- 위 예시에서 0번째 인덱스에 있는
2는you임을 나타낸다.
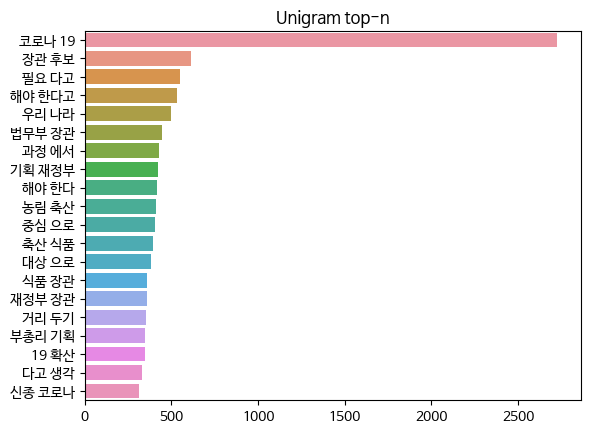
- bigram을 기준으로 단어의 출현 빈도를 나타낸 그래프이다. 코로나 19에 대한 출현빈도가 매우 높은 것을 알 수 있다.
- 만약 문서의 주제를 찾아야 하는 문제라면 '코로나 19'가 들어간 문서가 코로나 19를 주제로 삼고 있다는 것을 알 수 있다.
- 이렇게 카운트 기반의 단어 표현은 단어의 중요도를 나타낼 수 있다.
TF-IDF
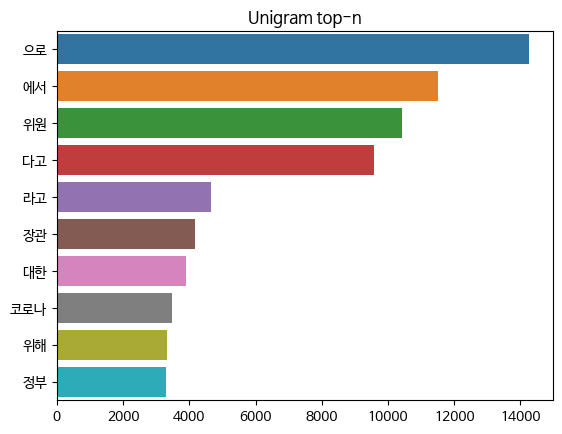
- 이번엔 unigram을 기준으로 단어의 출현 빈도를 나타낸 그래프이다.
- ~으로, ~에서, ~다로, ~라고와 같은 조사의 출현 빈도가 매우 높은 것을 알 수 있다.
- 이들을 빈도수가 높지만, 사실 문서의 주제를 파악하는데 있어 하나도 중요하지 않은 요소이다.
- 그러나 Bag of words에서는 이를 고려하지 못한다.
- TF-IDF는 이를 고려하여 중요하지 않은 단어에 적은 가중치를 부여하는 방법이다.
- 다음의 세가지 문장을 보자
정부가 코로나19 위기 단계 하향 여부를 5월 초 결정하기로 했습니다.
각종 지원을 정상화하면서도 고위험군은 보호하기 위해 마련했다고 중대본은 설명했습니다.
"손 씻기, 환기 및 소독, 기침 예절 등 개인 및 공동체가 지켜야 할 기본 수칙을 일상에서 실천해달라"고 당부했습니다.- '했습니다'를 하나의 토큰으로 볼 때 '했습니다'는 모든 문장에 등장한다.
- 반면 '코로나19', '고위험군', '소독'과 같은 토큰은 각 문장에만 등장하는 단어이다.
- 대략적으로 설명하면 TF-IDF는 모든 문서에 등장하는 단어에 낮은 가중치를 주고, 다른 문서에 잘 등장하지 않는 단어에 높은 가중치를 주어 조금 더 정확한 중요도를 파악할 수 있다.
- 구글 가이드에 의하면 Bag of Words보다 TF-IDF가 0.25 ~ 15% 정도 더 높은 정확도를 보인다고 한다. 하지만 경우에 따라 처리에 2배 더 오래 걸릴 수 있으니 적절한 선택이 필요하다.
시퀀스 기반의 단어 표현
- 카운팅 기반의 단어 표현에는 명확한 한계가 있는데, 바로 단어의 순서를 전혀 고려하지 못한다는 것이다.
you know I want your love. because I love youknow you your you want I love because love I- 카운팅 기반의 단어라면 두 문장을 구분하지 못할 것이다.
- 시퀀스 기반의 단어 표현은 문서에 있는 각 단어에 1대1 맵핑되는 정수를 부여하고, 그 정수로 단어를 나타내는 것이다.
단어 시퀀스 : [0 1 2 3 6 4 5 2 4 0]
단어 사전 : {you : 0, know : 1 , I : 2, want : 3, love : 4, because : 5, your : 6}- 1:1로 맵핑된 단어 사전만 알고 있으면 시퀀스를 단어로, 단어를 시퀀스로 자유롭게 변환할 수 있다.
임베딩 벡터
- 문제는 시퀀스 기반이든 카운팅 기반이든 단어를 그대로 벡터로 표현하는 한 발생하는 문제가 있다.
문서 1
안녕?
문서 2
제가 LA에 있을때는 말이죠... (중략) ... 태균이가 어 선배님 정말 오랜만입니다. 잘지냈습니까? 이러는거에요 ... (후략)- 머신러닝 또는 딥러닝 학습을 위해서는 Input 데이터가 모두 똑같은 shape을 가져야하는데, 그러기 위해서는 문서 1에 의미없는 값(pad)를 채워 길게 늘이거나, 문서 2를 잘라내어야 한다.
- 그러나 문서 2를 크게 잘라내면 정보가 많이 손실되기 때문에 정확한 예측이 어렵다.
- 반대로 문서 1에 pad를 너무 많이 채우면 모델이 모든 문장을 전부 pad로 학습해도 적은 loss를 얻게 되어 학습이 잘 이루어지지 않게된다.
- 이를 보완해주는 것이 바로 임베딩 벡터이다.
- 임베딩 벡터는 모든 단어를 n개의 feature 갖는 벡터로 간주하는데, 단어의 집합인 문장 및 문서를 이들 벡터의 연산으로 나타낸다.
- 그리고 연산 결과에 따른 loss를 학습하여 각 단어가 정답에 가까운 벡터값을 갖게 한다.
안녕 = [1 1]
LA = [0 0]
오랜만입니다 = [0.5 0.5]
잘 지냈습니까 = [-0.5 -0.5]- 만약 이 상태에서
오랜만입니다 + 잘지냈습니까 = [0 0]으로 나타낼 수 있는데 이는LA와 전혀 상관이 없다. - 그런데 학습을 통해 임베딩 벡터가 업데이트 되면
안녕 = [0.8 0.8]
LA = [-2 -2]
오랜만입니다 = [0.6 0.6]
잘 지냈습니까 = [0.1 0.1]-
오랜만입니다 + 잘지냈습니까 = [0.7 0.7]로안녕과 유사한 값을 갖게 된다. -
예시에서는 단 2개의 벡터로 이를 나타냈지만, 실제 모델에서는 관습적으로 128 또는 256차원의 벡터를 사용한다.
-
이러한 임베딩 기법 덕분에 Input 데이터의 크기를 줄이면서도 정보의 손실 및 왜곡 없이 단어를 모델에 넣을 수 있게 된다.
실습
불용어 처리
# 정규식 라이브러리 불러오기
import re
# 숫자, 알파벳, 한글이 아닌 모든 문자를 띄어쓰기로 변환
def stopwords(text):
return re.sub('[^0-9a-zA-Zㄱ-ㅣ가-힣()\[\]]', ' ' ,text)
x_train = x_train.apply(stopwords)
x_test = x_test.apply(stopwords)- 단어 토큰화에 앞서 분석의 의미가 없을거라 생각하는 특수문자를 모두 제거하였다.
- 다만 괄호 및 대괄호는 남겨두었는데, 데이터에는 코드도 있기 때문에 코드에서 많이 사용하는 기호를 남겨둔다면 모델이 코드인지 아닌지 분류하는데 도움이 될까 싶어서이다.
TF-IDF (n-gram 카운팅 기반)
# Countvectorizer 및 Kkma 토크나이저 불러오기
from sklearn.feature_extraction.text import TfidfVectorizer
from konlpy.tag import Kkma
# vectorizer 선언 (unigram)
tokenizer = Kkma()
vectorizer = TfidfVectorizer(tokenizer=tokenizer.morphs, ngram_range=(1, 1))
# 벡터화
x_train_uni = vectorizer.fit_transform(x_train)
x_test_uni = vectorizer.transform(x_test)
# vectorizer 선언 (bigram)
vectorizer = CountVectorizer(tokenizer=tokenizer.morphs, ngram_range=(2, 2))
# 벡터화
x_train_bi = vectorizer.fit_transform(x_train)
x_test_bi = vectorizer.transform(x_test)-
kkma 형태소 분석기를 통해 토큰화한 문장을
TfidfVectorizer에 넣어 TF-IDF 행렬을 구하였다. -
TF-IDF가 중요하지 않은 단어를 잘 구분해 줄 것이라 믿고 별도의 불용어 처리는 하지 않았다.

- 단 bigram을 기준으로 쪼갰을 때 약 7만개에 달하는 어마어마한 단어 종류가 나와 데이터를 줄이기 위해 약 20000개 정도로 한도를 설정해야 하여 다시 구해야 할 것 같다.
시퀀스 기반 단어 표현
# 필요 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 꼬꼬마 형태소 분석기를 이용해 토큰화합니다.
tokenizer = Kkma()
x_train_token = [tokenizer.morphs(sent) for sent in x_train]
x_test_token = [tokenizer.morphs(sent) for sent in x_test]
# 문자열 상태인 토큰을 시퀀스로 바꾸어 줍니다.
seq_train = Tokenizer(filters='', lower=True)
seq_test = Tokenizer(filters='', lower=True)
seq_train.fit_on_texts(x_train)
seq_test.fit_on_texts(x_test)
x_train_seq = seq_train.texts_to_sequences(x_train)
x_test_seq = seq_test.texts_to_sequences(x_test)- 단어를 시퀀스로 바꾸는 과정이다.
- 이제 Input 모양을 맞추기 위해서 문서에 pad를 채우거나 잘라내는 과정을 거쳐야 한다.

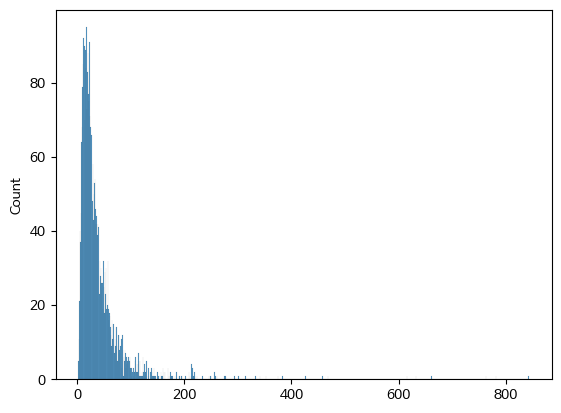
- 토큰의 길이 분포를 확인해봤는데 최대 843부터 2까지 매우 넓은 분포를 보였다.
- 대부분의 값이 0 ~ 100 구간에 존재하므로 pad의 양을 줄이는 것이 전체 모델 성능에 더 좋을 것이라 생각하여 시퀀스 길이가 128이 되도록 하였다.
# 128 정도로 설정해보자.
x_train_pad = pad_sequences(x_train_seq, maxlen=128, padding='pre', truncating='post')
x_test_pad = pad_sequences(x_test_seq, maxlen=128, padding='post', truncating='post')Word2Vec
- 임베딩 매트릭스를 구하는 과정인데, 이는 교안에 제공된 코드를 그대로 사용했기 때문에 올릴 수 는 없다.
- 사실 모델에서 자체적으로 임베딩 레이어를 제공하지만, 가지고 있는 코퍼스 데이터를 바탕으로 임베딩 레이어를 만들면 OOV(단어 사전에 없는 모르는 단어) 문제가 발생할 가능성이 줄어들기 때문에 별도로 만들어 주는 것도 좋은 접근이다.
