
무엇을 했나
텍스트 분류 모델링
머신러닝 기반 모델링
- N-gram 기반으로 구한 TF-IDF 행렬 데이터를 바탕으로 머신러닝 모델링을 하였다.
1. 모델 선정
- 간단히 Logistic Regression, Soft Vector Machine, LightGBM 세가지로 모델링을 진행하였다.
- 먼저 아무런 하이퍼 파라미터 튜닝 없이 기본 모델을 생성하여 성능을 테스트하였다.

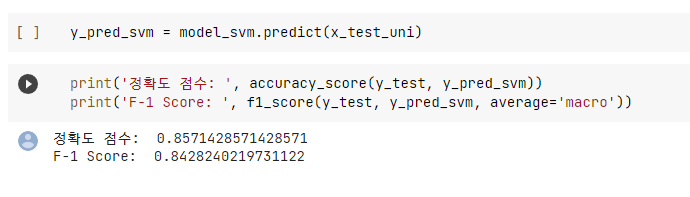
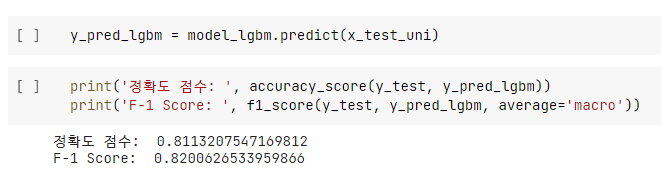
- 성능은 SVM ≒ LR > LGBM 순으로 나왔다. SVM이 조금더 튜닝할 요소가 많으므로 최종적으로 SVM을 모델로 선정하였다.
2. 베이지안 최적화
- 지난 경진대회 때 처음 사용했던 베이지안 최적화를 이번에도 사용해보기로 하였다.
- 베이지안 최적화를 사용한 이유는 쿠팡에서 작성한 칼럼에서 최적의 파라미터를 찾기 위해 베이지안 최적화를 사용하였다는 글을 보고, 짧은 시간 내에 최적의 조합을 찾기에 가장 적합한 모델이라고 생각하였기 때문이다.
Optimizing the inbound process with a machine learning model
# Colab환경에서 설치 필요
!pip install scikit-optimize
# 필요 라이브러리
from skopt import BayesSearchCV
from skopt.space import Real, Integer, Categorical
model = SVC()
# 탐색 범위 설정
params = {
'kernel' : Categorical(['rbf', 'sigmoid', 'linear']),
'C' : Real(0.1, 20, prior='log-uniform'),
'gamma' : Real(0.001, 1, prior='log-uniform', base=2),
}
# 탐색 조건 설정 - f1_macro를 기준으로 50회 탐색
result = BayesSearchCV(model, params, scoring='f1_macro', n_jobs=-1, cv=3, verbose=1, n_iter=50)- 탐색 범위는 kernel, C, gamma 총 3가지를 두었는데, 다른 하이퍼파라미터를 건들기에는 아직 모델에 대한 지식이 충분하지 않아서 알고있는 것만을 범위에 넣었다.
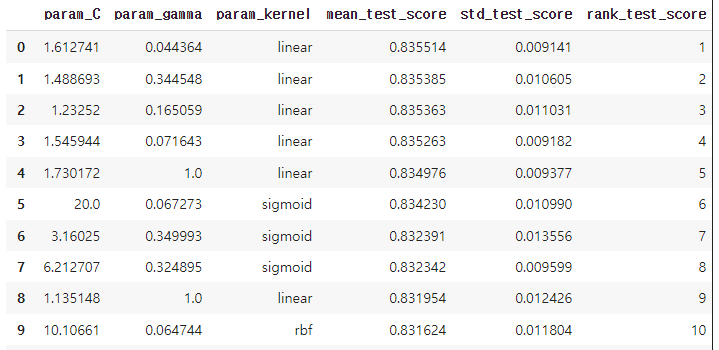
- 탐색 결과 성능이 좋았던 순으로 파라미터를 표시하고, 조금씩 범위를 줄여나가는 방식으로 최적의 파라미터를 찾았다.
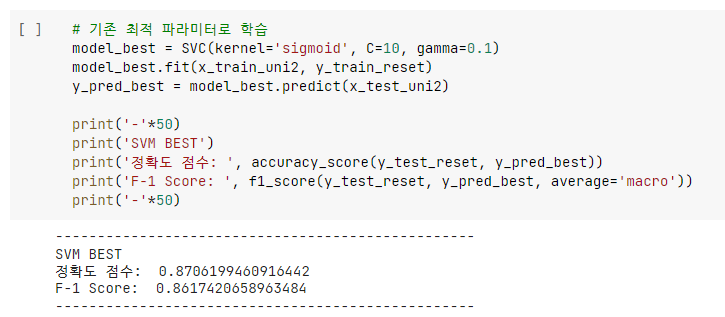
- 최종 결과는 sigmoid에서 C=10, gamma=0.1에서 제일 우수한 성능을 보였다.
- 튜닝이 없을 때에 비해 정확도와 F-1 macro score가 0.2 정도 상승하였다.
3. 오답 확인
--------------------------------------------------
실제 정답 : 코드
예측 정답 : 이론
문의 내용 : inclusive에 left를 써서 왼쪽 10만 포함을 의도했는데 오른쪽 20도 포함이 돼요
--------------------------------------------------
실제 정답 : 시스템 운영
예측 정답 : 웹
문의 내용 : 액세스 거부됨이라고 뜹니다
--------------------------------------------------
실제 정답 : 코드
예측 정답 : 이론
문의 내용 : 4. 데이터 분석에서 추가는 본인이 생각해서 분석해보라는뜻인가요?
--------------------------------------------------- 우선 길이가 짧은 문장에 대한 오답확률이 높았다.
- 통계기반으로 학습하는 모델인 만큼, 충분한 문장이 주어져야 정답을 잘 맞출 수 있는 것 같다.
--------------------------------------------------
실제 정답 : 코드
예측 정답 : 원격
문의 내용 : NAT와 Bridge와 Host-only의 차이점이 궁금하다면 문의남기라고 하셔서 남깁니다.
또한 원격 감사합니다.
--------------------------------------------------
실제 정답 : 코드
예측 정답 : 이론
문의 내용 : 오전 object config 설명에서 궁금한점이 생겨 질문드립니다
1. x, y 위치를 표준화 하는건가요 아니면 정규화하는건가요??
2. 강의안에는 center_x: 0.533, center_y: 0.3025로 나와있습니다. 혹시 0이 좌상단 모서리부터 시작인가요??
--------------------------------------------------
실제 정답 : 코드
예측 정답 : 이론
문의 내용 : 2. activation 함수
activation함수가 앞에서 들어온 신호에 대해서 가중치 곱한것들을 합친다음에
신호의 합을 다음 단계로 어떻게 넘길지 처리해주는 함수라고 설명해주셨는데,
지정하는 경우도 있고, 따로 지정하지 않을 경우도 있는데 사용 할때와 안할때 차이가 무엇인가요?
--------------------------------------------------- 데이터에서 label이 코드인 경우 말 그대로 코드 자체가 내용에 포함된 경우가 많았는데, 그래서 그런지 실제 코드가 없는 내용에 대해 오예측을 하는 경우가 많았다.
- 또한 label이 원격인 경우
원격단어가 항상 포함되어있기 때문에 높은 가중치를 받는 것 같다. 때문에원격단어가 들어간 문장의 정답을 원격으로 예측하였다.
AutoML
- 지난달 참여했던 ML 경진대회의 수상자는 전부 AutoML이 쓸어갔다.
- 정말 특별하게 Feature Extraction을 잘 하지 않는 한, 순수 모델링 싸움에서는 AutoML을 이기는 것이 힘들지 않을까라는 생각에 경험삼아 AutoML도 사용해보기로 하였다.
Autogluon
- 데이콘 AI 경진대회에서 1등을 차지한 API이다.
- MutilModalPredictor를 통해 텍스트 데이터를 처리할 수 있는데, TF-IDF 행렬을 그대로 넣으니 수십분동안 변화가 일어나지 않아 학습을 중단하였다. (아마 수시간 단위로 기다렸다면 학습이 진행되었을 수도 있다.)
- 결국 토큰화만 진행된 데이터를 통채로 전달해 보았는데, 학습은 빠르게 이루어졌으나 성능이 좋지 못했다.
from autogluon.multimodal import MultiModalPredictor
import uuid
model_path = f"./tmp/{uuid.uuid4().hex}-automm_sst"
predictor = MultiModalPredictor(
label='label',
eval_metric='acc',
path=model_path,
problem_type='multiclass'
)
predictor.fit(df_train, time_limit=180)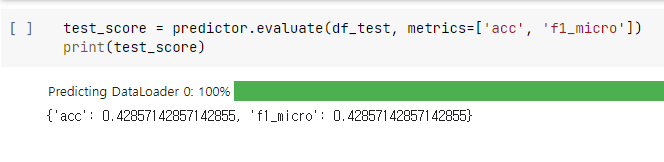
PyCaret
- 시각화를 정말 잘 제공해준다고 생각이 드는 AutoML API이다.
- 코드도 단순하고 학습 과정이 실시간으로 보여 AutoGluon때와 달리 믿음을 갖고 2시간 가량의 학습을 할 수 있었다.
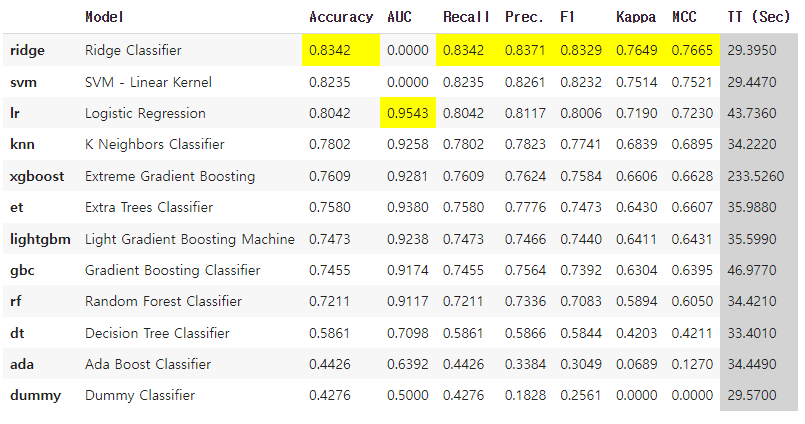

- 배워본적이 없는 Ridge Classifier가 가장 높은 성능을 보일 것이라 예측하였다.
- 이는 내일 시간이 된다면 한번 시도해봐야겠다.
- SVM에서도 linear 커널이 제일 성능이 좋을 것이라 예측하였는데, 직접 했을 때는 그렇지 않았다는 것을 생각하면 AutoML을 바탕으로 역시 직접 분석하는 과정을 거치는 것이 좋을 것 같다.
딥러닝 기반 모델링
(비교적) 무거운 모델
- 시퀀스 전처리된 데이터를 기반으로 딥러닝 모델 구조로 학습을 진행해보았다.
- 전처리 과정에서 x와 y의 순서가 섞이는 것을 뒤늦게 발견하기도 하고, 실제 성능도 잘 나오지 않아서 보완이 많이 필요해보인다. (특히 전처리)
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
il = Input(shape=(max_len,))
hl = Embedding(input_dim=vocab_size, output_dim=embedding_size)(il)
hl = Conv1D(64, kernel_size=4, padding='same', activation='swish')(hl)
# Bidirectional layer - 정방향 : LSTM, 히든스테이트 32, 역방향 : LSTM, 히든스테이트 32
forward_LSTM = LSTM(32, return_sequences=True)
backward_LSTM = LSTM(32, return_sequences=True, go_backwards=True)
hl = Bidirectional(layer=forward_LSTM, backward_layer=backward_LSTM)(hl)
# Bidirectional layer - 정방향 : GRU, 히든스테이트 32, 역방향 : RNN, 히든스테이트 16
forward_GRU = GRU(32, return_sequences=True)
backward_RNN = SimpleRNN(16, return_sequences=True, go_backwards=True)
hl = Bidirectional(layer=forward_GRU, backward_layer=backward_RNN)(hl)
# Conv1D 블록 : 필터수 32개, 윈도우 사이즈 5
hl = Conv1D(filters=32,
kernel_size=5,
strides=1,
padding='valid',
activation='swish')(hl)
# MaxPool1D 블록 : 필터사이즈2
hl = MaxPool1D(pool_size=2)(hl)
# 플래튼
hl = Flatten()(hl)
# FC Layer : 노드 1024개
hl = Dense(1024, activation='swish')(hl)
hl = Dropout(0.3)(hl)
# Output
ol = Dense(5, activation='softmax')(hl)
# 3. 모델 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'],
optimizer=keras.optimizers.Adam(learning_rate=1e-4))
# 요약
model.summary()
model.fit(x_train_pad, y_train, epochs=1000, batch_size=32 ,verbose=1, validation_split=0.2, callbacks=[es, lr])Epoch 1/1000
84/84 [==============================] - 54s 363ms/step - loss: 1.4023 - accuracy: 0.4179 - val_loss: 1.3203 - val_accuracy: 0.4273 - lr: 1.0000e-04
Epoch 2/1000
84/84 [==============================] - 26s 308ms/step - loss: 1.2751 - accuracy: 0.4516 - val_loss: 1.2468 - val_accuracy: 0.4573 - lr: 1.0000e-04
Epoch 3/1000
84/84 [==============================] - 26s 307ms/step - loss: 1.0535 - accuracy: 0.5652 - val_loss: 1.2060 - val_accuracy: 0.4903 - lr: 1.0000e-04
Epoch 4/1000
84/84 [==============================] - 30s 356ms/step - loss: 0.7905 - accuracy: 0.6889 - val_loss: 1.2672 - val_accuracy: 0.5127 - lr: 1.0000e-04
Epoch 5/1000
84/84 [==============================] - 27s 317ms/step - loss: 0.5559 - accuracy: 0.7969 - val_loss: 1.4579 - val_accuracy: 0.5307 - lr: 1.0000e-04
Epoch 6/1000
84/84 [==============================] - 26s 314ms/step - loss: 0.3976 - accuracy: 0.8636 - val_loss: 1.4992 - val_accuracy: 0.5817 - lr: 1.0000e-04
Epoch 7/1000
84/84 [==============================] - 27s 317ms/step - loss: 0.2463 - accuracy: 0.9232 - val_loss: 1.8562 - val_accuracy: 0.5757 - lr: 5.0000e-05
Epoch 8/1000
84/84 [==============================] - 26s 308ms/step - loss: 0.1795 - accuracy: 0.9490 - val_loss: 1.9675 - val_accuracy: 0.5727 - lr: 5.0000e-05
Epoch 9/1000
84/84 [==============================] - 26s 310ms/step - loss: 0.1338 - accuracy: 0.9663 - val_loss: 2.1827 - val_accuracy: 0.5787 - lr: 5.0000e-05
Epoch 10/1000
84/84 [==============================] - 26s 307ms/step - loss: 0.0973 - accuracy: 0.9764 - val_loss: 2.2817 - val_accuracy: 0.5697 - lr: 2.5000e-05
Epoch 11/1000
84/84 [==============================] - 24s 289ms/step - loss: 0.0810 - accuracy: 0.9805 - val_loss: 2.3991 - val_accuracy: 0.5832 - lr: 2.5000e-05
Epoch 12/1000
84/84 [==============================] - 27s 315ms/step - loss: 0.0658 - accuracy: 0.9854 - val_loss: 2.5031 - val_accuracy: 0.5802 - lr: 2.5000e-05
Epoch 13/1000
84/84 [==============================] - ETA: 0s - loss: 0.0559 - accuracy: 0.9876Restoring model weights from the end of the best epoch: 3.
84/84 [==============================] - 27s 319ms/step - loss: 0.0559 - accuracy: 0.9876 - val_loss: 2.5231 - val_accuracy: 0.5802 - lr: 1.2500e-05
Epoch 13: early stopping
<keras.callbacks.History at 0x7fd6b1da2700>
12/12 [==============================] - 2s 62ms/step
--------------------------------------------------
Deep Learning
정확도 점수: 0.3908355795148248
F-1 Score: 0.2174116667836151- 데이터 크기에 비해 다소 복잡한 모델을 쌓았고, EarlyStopping에 ReduceLR을 사용하여 과적합을 방지하였다.
- Learning Rate 역시 기본값 1e-3 대신 1e-4를 사용하였다.
- 그런데 val_accuracy가 0.6도 넘지 못하였고, 테스트 데이터에 대한 점수는 더 심각하게 나왔다.
- 때문에 시간이 된다면 내일 중 전처리를 다시 정리하여 한번에 돌려볼 계획이다.
가벼운 모델
# 1. 세션 클리어
clear_session()
# 2. 레이어 연결
il = Input(shape=(max_len,))
hl = Embedding(input_dim=vocab_size, output_dim=embedding_size)(il)
# Bidirectional layer - 정방향 : LSTM, 히든스테이트 32, 역방향 : LSTM, 히든스테이트 32
hl = LSTM(32, return_sequences=True)(hl)
# 플래튼
hl = Flatten()(hl)
# FC Layer : 노드 16개
hl = Dense(16, activation='swish')(hl)
hl = Dropout(0.3)(hl)
# Output
ol = Dense(5, activation='softmax')(hl)
# 3. 모델 선언
model = Model(il, ol)
# 4. 컴파일
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'],
optimizer=keras.optimizers.Adam(learning_rate=1e-4))
# 요약
model.summary()Epoch 1/1000
84/84 [==============================] - 21s 128ms/step - loss: 1.5065 - accuracy: 0.4010 - val_loss: 1.4293 - val_accuracy: 0.4288 - lr: 1.0000e-04
Epoch 2/1000
84/84 [==============================] - 9s 101ms/step - loss: 1.4096 - accuracy: 0.4172 - val_loss: 1.3396 - val_accuracy: 0.4288 - lr: 1.0000e-04
Epoch 3/1000
84/84 [==============================] - 10s 117ms/step - loss: 1.2834 - accuracy: 0.4378 - val_loss: 1.1989 - val_accuracy: 0.4798 - lr: 1.0000e-04
Epoch 4/1000
84/84 [==============================] - 8s 101ms/step - loss: 1.1740 - accuracy: 0.4906 - val_loss: 1.1140 - val_accuracy: 0.5787 - lr: 1.0000e-04
Epoch 5/1000
84/84 [==============================] - 9s 110ms/step - loss: 1.0504 - accuracy: 0.5922 - val_loss: 1.0167 - val_accuracy: 0.6282 - lr: 1.0000e-04
Epoch 6/1000
84/84 [==============================] - 9s 113ms/step - loss: 0.9119 - accuracy: 0.6492 - val_loss: 0.9138 - val_accuracy: 0.6837 - lr: 1.0000e-04
Epoch 7/1000
84/84 [==============================] - 8s 96ms/step - loss: 0.7786 - accuracy: 0.7058 - val_loss: 0.8162 - val_accuracy: 0.7256 - lr: 1.0000e-04
Epoch 8/1000
84/84 [==============================] - 11s 133ms/step - loss: 0.6380 - accuracy: 0.7714 - val_loss: 0.7598 - val_accuracy: 0.7481 - lr: 1.0000e-04
Epoch 9/1000
84/84 [==============================] - 9s 113ms/step - loss: 0.5532 - accuracy: 0.8002 - val_loss: 0.8231 - val_accuracy: 0.6957 - lr: 1.0000e-04
Epoch 10/1000
84/84 [==============================] - 9s 107ms/step - loss: 0.4856 - accuracy: 0.8268 - val_loss: 0.7419 - val_accuracy: 0.7691 - lr: 1.0000e-04
Epoch 11/1000
84/84 [==============================] - 8s 94ms/step - loss: 0.4257 - accuracy: 0.8624 - val_loss: 0.7870 - val_accuracy: 0.7526 - lr: 1.0000e-04
Epoch 12/1000
84/84 [==============================] - 9s 112ms/step - loss: 0.3784 - accuracy: 0.8741 - val_loss: 0.7975 - val_accuracy: 0.7736 - lr: 1.0000e-04
Epoch 13/1000
84/84 [==============================] - 9s 108ms/step - loss: 0.3390 - accuracy: 0.8879 - val_loss: 0.8148 - val_accuracy: 0.7631 - lr: 1.0000e-04
Epoch 14/1000
84/84 [==============================] - 8s 93ms/step - loss: 0.2938 - accuracy: 0.9112 - val_loss: 0.8188 - val_accuracy: 0.7781 - lr: 5.0000e-05
Epoch 15/1000
84/84 [==============================] - 9s 106ms/step - loss: 0.2872 - accuracy: 0.9119 - val_loss: 0.8254 - val_accuracy: 0.7841 - lr: 5.0000e-05
Epoch 16/1000
84/84 [==============================] - 8s 95ms/step - loss: 0.2835 - accuracy: 0.9052 - val_loss: 0.8708 - val_accuracy: 0.7826 - lr: 5.0000e-05
Epoch 17/1000
84/84 [==============================] - 9s 106ms/step - loss: 0.2547 - accuracy: 0.9202 - val_loss: 0.8769 - val_accuracy: 0.7871 - lr: 2.5000e-05
Epoch 18/1000
84/84 [==============================] - 9s 111ms/step - loss: 0.2507 - accuracy: 0.9213 - val_loss: 0.8915 - val_accuracy: 0.7871 - lr: 2.5000e-05
Epoch 19/1000
84/84 [==============================] - 8s 95ms/step - loss: 0.2387 - accuracy: 0.9254 - val_loss: 0.9080 - val_accuracy: 0.7856 - lr: 2.5000e-05
Epoch 20/1000
84/84 [==============================] - ETA: 0s - loss: 0.2388 - accuracy: 0.9299Restoring model weights from the end of the best epoch: 10.
84/84 [==============================] - 9s 108ms/step - loss: 0.2388 - accuracy: 0.9299 - val_loss: 0.9180 - val_accuracy: 0.7856 - lr: 1.2500e-05
Epoch 20: early stopping
<keras.callbacks.History at 0x7fd6b19cefa0>
12/12 [==============================] - 0s 25ms/step
--------------------------------------------------
Deep Learning
정확도 점수: 0.38005390835579517
F-1 Score: 0.16008859001186365- 혹시라도 과적합 문제일까 싶어서 훨씬더 가벼운 모델을 생성하였지만, 결과는 크게 다르지 않았다.
아쉬웠던 점
- 테스트 결과를 정리하고, 결과를 바탕으로 다음 변수, 파라미터를 어떻게 조절할 지 차근차근 생각했어야 했는데, 눈 앞의 성능 향상에 집착하다보니 다소 중구난방 식으로 모델링과 튜닝을 했던 것 같다.
- 다음부터는 테스트를 한번 했으면 결과를 정리하여, 어떤 변수, 파라미터가 성능에 어떠한 영향을 주는 지 파악하는 시간을 가져보고 싶다.
