
데이터베이스
데이터베이스 기초 이론
DB : 데이터를 통합하여 관리하도록 저장해놓은 데이터 집합
DBMS : DB를 관리하는 미들웨어 시스템
데이터베이스의 종류
RDBMS
관계형 데이터베이스 시스템이라고 하며, 관련있는 데이터를 열과 행으로 이루어진 하나의 테이블로 표현한 DB이다.
테이블 사이의 관계 설정을 통해 최적화된 스키마를 설계할 수 있다.
스키마는 DB의 논리적 구조 및 제약조건을 말한다. 사용자가 CRUD 작업을 명령할 때 DBMS는 정의된 스키마를 바탕으로 명령을 수행한다.
RDBMS는 최적화 된 스키마를 통해 Read 수행 속도가 빠르다.
대신 데이터를 변경해야할 때는 다른 테이블에도 영향을 주기 때문에 추가/수정/삭제 작업이 비교적 느린편이다.
NoSQL
데이터 사이에 관계가 없도록 저장하는 DB를 NoSQL이라고 한다.
관계 설정이 없기 때문에 DB의 복잡성이 줄어 RDBMS보다 데이터를 추가/수정/삭제하는 작업이 빠르다.
대신 Read 속도는 비교적 느린 편이다.
데이터가 어떤 형태로 저장되는지에 따라 다양한 종류가 있다.
대표적으로 MongoDB는 파이썬의 딕셔너리 처럼 데이터를 Key-Value 형태로 저장한다.
최근 빅데이터 등을 위한 로그 데이터가 중요해지면서, Read보다 Write 작업이 많이 발생하는 DB가 많이 사용되는데, 이러한 DB에 NoSQL이 유리하다.
트랜잭션
NoSQL의 또하나의 특징은 트랜잭션이 잘 지원되지 않는다는 것이다.
최근들어 트랜잭션을 지원하는 NoSQL이 있지만, RDBMS보다 제한적으로 지원한다.
트랜잭션이란 더 이상 쪼갤 수 없는 작업의 최소 단위를 뜻한다. 다소 쉽게 말하면 한꺼번에 처리되어야만 하는 일련의 작업(연산)을 말한다.
트랜잭션의 성질
- 원자성 : 트랜잭션 작업의 결과는 모두 완벽히 수행되거나 하나도 수행되지 않는다.
- 일관성 : 트랜잭션 전 후의 데이터베이스의 구조적 상태는 변하지 않아야 한다.
- 독립성 : 어떤 트랜잭션이 수행 중일 때, 다른 트랜잭션의 연산이 끼어들거나 값을 참조할 수 없다.
- 영속성 : 트랜지션이 완료되면 시스템이 고장나더라도 영구히 반영되어야 한다.
커밋(Commit)과 롤백(Rollback)
트랜잭션의 성질을 보장하기 위해 커밋과 롤백이라는 개념을 사용한다.
- 커밋 : 모든 트랜잭션이 완벽히 수행된 후, 결과를 확정하는 명령. 커밋이 되지 않으면 트랜잭션의 수행 결과는 DB 단 하나도 반영되지 않는다.
- 롤백 : 트랜잭션 수행 중 성질이 깨지는 등 트랜잭션을 취소해야할 때, 트랜잭션의 실행 전으로 되돌아가는 명령이다.
이를 통해 DB의 안정성을 보장하고, 이전 데이터로의 복구가 용이해진다.
MongoDB 문법
mongoDB는 Key-Value 형태로 데이터를 저장하는 대표적인 NoSQL DBMS이다.
mongoDB의 특징 중 하나는 자바스크립트와 유사한 문법을 사용한다는 것이다.
database 생성
// create database
use mongo;
db;
// db 조회
show dbs;// result
admin 112.00 KiB
config 72.00 KiB
local 72.00 KiBuse mongo: 사용할 db의 이름을 지정한다.db: db를 선언한다.
그런데 show dbs를 통해 조회해도 DB가 선언한 DB가 조회되지 않는다.
이는 mongo DB의 특징인데, mongo DB는 기존에 없는 데이터베이스, 콜렉션 등을 조회하면 에러를 출력하는게 아니라 아예 생성을 한다.
그러나 매번 잘못 입력할 때마다 생성을 하는 것은 비효율적이므로, 선언 이후 데이터를 1개 이상 추가해주어야 비로소 생성이 이루어진다.
// create document (row)
db.user.insert({name:'andy', age:28, email:'andy@gmail.com'})
show dbs;// result
admin 112.00 KiB
config 108.00 KiB
local 72.00 KiB
mongo 8.00 KiB데이터를 하나 추가하니 mongo라는 DB가 잘 생성된 것을 확인할 수 있다.
db를 생성할 때와 마찬가지로 콜렉션 역시 없는 이름을 지정하면 생성된다.
데이터의 생성 문법은 아래에서 보다 자세히 설명할 것이다.
collections
RDBMS에서 하나의 DB가 여러개의 테이블로 구성되듯이, mongoDB에서 하나의 DB는 여러개의 컬렉션으로 구성된다.
DB에 있는 콜렉션의 목록은 show collections로 확인할 수 있다.
// server > databases > collections > documents
// collection list
show collections;// result
user방금 생성한 user collection이 있는 것을 확인할 수 있다.
db.createCollection('name', option)
createCollection()은 새 컬렉션을 생성하는 쿼리이다.
name : 생성될 컬렉션의 이름
option : 컬렉션에 부여할 옵션 지정
capped: DB의 크기를 고정하는 옵션이다. 원래 콜렉션은 데이터를 무한으로 저장할 수 있지만 capped 옵션과 함께 최대 용량, 최대 개수를 지정하면 용량을 제한할 수 있다.size: DB의 최대 용량 지정. 단위는 Byte이고, 최소 4096 Byte를 갖는다.max: 최대 데이터 개수 지정
// info1 콜렉션 생성, 용량 4096Byte, 최대 5개 데이터 저장 가능
db.createCollection('info1', {capped: true, size: 500, max:5});db.collection_name.drop()
collection_name 이름을 가진 컬렉션을 제거한다.
데이터 CRUD
CRUD는 각각 Create(추가), Read(조회), Update(변경), Delete(삭제)를 의미하며, DB를 다루는 거의 모든 행동은 CRUD 중 하나이다.
CREATE
db.collection.insert(data) : 지정한 콜렉션에 데이터(document)를 추가한다.
딕셔너리 형식, json string 형식등을 사용할 수 있으며, 한번에 여러 데이터를 리스트에 담아 추가할 수 있다.
db.info1.insert([
{subject: 'python', level: 1},
{subject: 'css', level: 2},
{subject: 'js', level: 3},
{subject: 'scss', level: 4},
{subject: 'web', level: 5},
{subject: 'flask', level: 6},
{subject: 'nginx', level: 7}
]);// result
{
acknowledged: true,
insertedIds: {
'0': ObjectId("644b1ddb14426a624b299f50"),
'1': ObjectId("644b1ddb14426a624b299f51"),
'2': ObjectId("644b1ddb14426a624b299f52"),
'3': ObjectId("644b1ddb14426a624b299f53"),
'4': ObjectId("644b1ddb14426a624b299f54"),
'5': ObjectId("644b1ddb14426a624b299f55"),
'6': ObjectId("644b1ddb14426a624b299f56")
}
}// READ : find
db.info1.find();
분명 7개를 추가했는데 5개만 조회가 된다.
그 이유는 info1 컬렉션을 생성했을 때 capped, max 옵션을 이용해 데이터의 최대 개수를 5개로 한정했기 때문이다.
이 경우 5개를 넘는 데이터가 추가될 때 오래된 데이터를 제거하여 데이터 수를 유지한다.
DELETE
db.collection_name.deleteOne({colume: value}) : 지정한 콜렉션에서 컬럼을 기준으로 지정한 값을 가진 데이터 하나를 찾아 제거한다. id 순으로 가장 먼저 검색된 document를 제거한다.
만약 조건이 일치하는 모든 데이터를 제거하고 싶다면 deleteMany를 사용할 수 있다.
// DELETE : deleteOne, deleteMany
db.info1.deleteOne({level: 7});// result
Uncaught
MongoServerError: cannot remove from a capped collection: mongo.info1그런데 이번엔 제거가 이루어지지 않는다.
그 이유는 info1의 옵션이 capped이기 때문인데, capped 옵션이 지정된 컬렉션의 데이터는 수정 및 삭제를 할 수 없다.
이를 위해 새로 info2 컬렉션을 생성해보자
db.createCollection('info2');
db.info2.insert([
{subject: 'python', level: 1},
{subject: 'css', level: 2},
{subject: 'js', level: 3},
{subject: 'scss', level: 4},
{subject: 'web', level: 5},
{subject: 'flask', level: 6},
{subject: 'nginx', level: 7},
{subject: 'was', level: 5},
{subject: 'db', level: 5},
]);
// Delete
db.info2.deleteOne({level:5})
db.info2.find();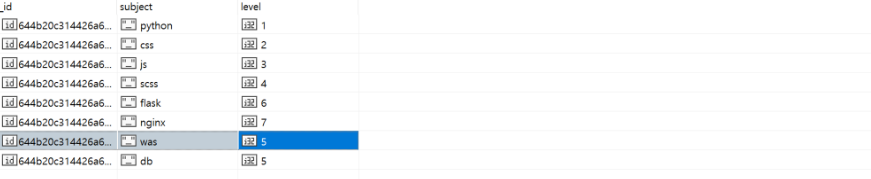
level: 5인 데이터는 총 3개이지만, 가장 먼저 선언되었던 데이터만 제거된 것을 확인할 수 있다.
추가적으로, 모든 데이터를 삭제하고 싶다면 db.deleteMany({}) 를 사용할 수 있다.
READ
db.collection.find() : 지정한 콜렉션의 데이터를 조회한다.
이때 condition query라는 것을 사용하여 다양한 조건을 바탕으로 조회가 가능하다.
// READ : 비교 연산자 사용 (4 이상인 데이터)
db.info2.find({ level: {$gte: 4} }); 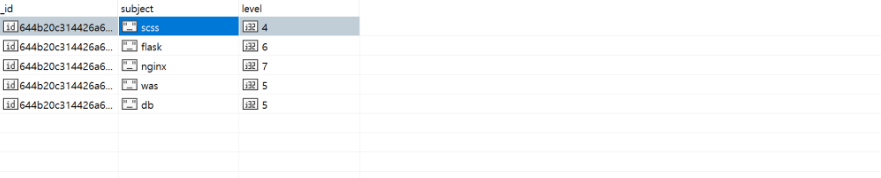
mongoDB에서는 $로 시작하는 다양한 비교연산자, 논리연산자 등을 활용해 원하는 데이터만을 조회할 수 있다.
$gte는 grater than equal로 ≥와 같은 의미이다.
실제로 level이 4 이상인 데이터만 조회되었다.
// READ : 리스트에 들어있는 값과 일치하는 데이터 조회
db.info2.find({ subject: {$in: ['nginx', 'python']}});
// READ : 2이상 5이하인 데이터 조회
db.info2.find( {$and: [{level: {$gte: 2}}, {level: {$lte: 5}}]} );Projection
Projection이란 document를 조회할 때, 원하는 컬럼만 지정하여 조회하는 것을 말한다.
find의 문법은 find(criteria?, projection?) 인데, 조회 범위 다음으로 projection을 입력할 수 있다.
db.collection_name.find( {}, {column_name1: bool, column_name2: bool ...} ) 이런 형식으로 컬럼을 출력할지 제외할지 설정할 수 있다.
컬럼 중 하나라도 true 옵션을 지정하면, 옵션을 별도로 지정하지 않은 컬럼은 false로 간주한다.
예외적으로 _id 컬럼은 직접 명시하지 않는 한 항상 true로 간주한다.
반대로 컬럼 중 하나라도 false 옵션을 지정하면, 지정하지 않은 컬럼은 true로 간주한다.
마지막으로 true와 false는 섞어 쓸 수 없다. (지정되지 않은 컬럼의 처리가 애매해지기 때문)
// Projection
db.info2.find( {}, {subject: true});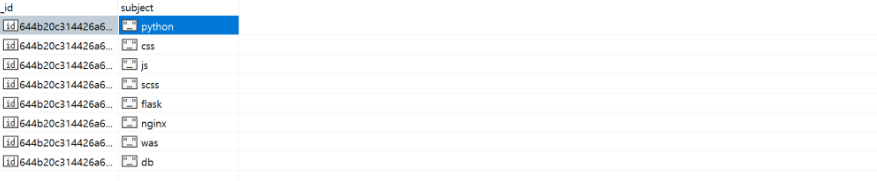
_id와 subject 컬럼만 조회되는 것을 확인할 수 있다.
정렬
.sort({})를 이용해 결과를 정렬할 수 있다.
반드시 중괄호를 함께 사용해야하며, 중괄호 안에 정렬 기준이 될 컬럼과 정수(오름차순/내림차순 지정)를 입력해주어야 한다.
// sort
// level 기준 오름차순(1)
db.info2.find().sort({level: 1});
// level 기준 내림차순(-1)
db.info2.find().sort({level: -1});조회 데이터 수 제한
limit()를 이용해 조회되는 데이터의 수를 제한할 수 있다.
// limit + sort
db.info2.find({level: {$lte: 5}}).sort({level: -1}).limit(3);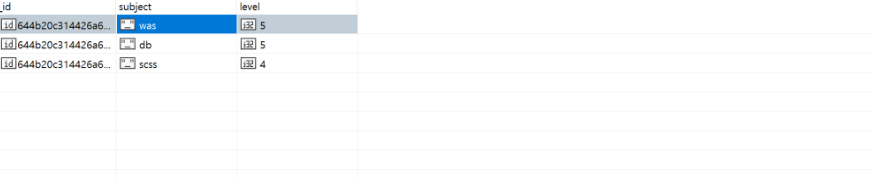
- 레벨이 5이하인 데이터를
- 내림차순으로 정렬하고
- 최대 3개까지 출력해라
위와 같은 문법으로 메서드를 줄줄이 엮는 것을 체이닝(Chaining)이라고 한다.
UPDATE
db.collection_name.update(query, update, option?) : 지정한 query에 맞는 document 하나를 찾아 그 값을 업데이트 한다.
$set 연산자와 함께 업데이트 할 컬럼 및 값을 입력해주어야 한다.
옵션으로 multi:true 를 지정하면 query에 맞는 모든 documents 값을 바꿀 수 있다.
또는 update 대신 updateOne(), updateMany()를 사용할 수 있다.
// UPDATE : update
db.info2.update({subject: 'css'}, {$set: {level: 5}});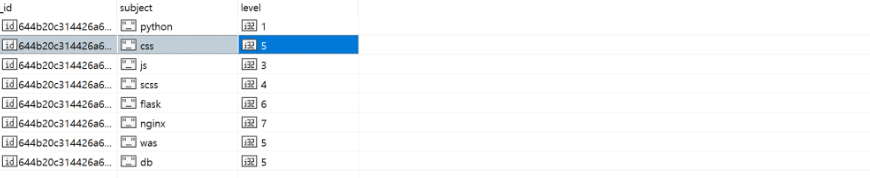
mongoDB 함수
mongoDB는 자바스크립트 문법을 차용했기 때문에, 자바스크립트 처럼 함수를 선언하여 사용할 수 있다.
// 데이터를 페이지 단위로 나누어 지정한 페이지를 조회
var pagenation = function(page, pageblock){
return db.info2.find().skip((page-1)*pageblock).limit(pageblock);
}
// 한 페이지당 3개의 데이터를 담고, 2페이지를 출력
pagenation(2, 3);Pymongo
mongoDB를 파이썬에서 사용할 수 있도록 도와주는 패키지이다.
서버 접속
import pymongo
# URI를 통한 접속
client = pymongo.MongoClient('URI')
# DB 리스트 확인
client.list_databases()# result
[{'name': 'admin', 'sizeOnDisk': 114688.0, 'empty': False},
{'name': 'config', 'sizeOnDisk': 73728.0, 'empty': False},
{'name': 'local', 'sizeOnDisk': 73728.0, 'empty': False},
{'name': 'mongo', 'sizeOnDisk': 167936.0, 'empty': False}]여기서 URI는 mongodb://myDBReader:D1fficultP%40ssw0rd@mongodb0.example.com:27017/?authSource=admin 형식의 UI를 사용한다.
DB 및 컬렉션 접근
연결된 client 객체를 통해 DB 및 컬렉션에 접근이 가능해진다.
# mongo라는 이름의 db에 접속
db = client.mongo
# 컬렉션 목록 확인
list(db.list_collection_names())
# info1 컬렉션에 접근
collection = db.info1
collection앞서 mongoDB를 다룰 때 생성했던 컬렉션들을 확인할 수 있다.
CRUD
pymongo의 가장 큰 장점은 mongoDB에서 사용하는 문법을 거의 그대로 쓸 수 있다는 점이다.
컬렉션 생성
mongoDB때와 마찬가지로, 기존에 없던 DB나 컬렉션을 호출하면 생성이 이루어진다.
데이터를 하나 이상 추가하여야 하는 것도 동일하다.
# 이름이 'info'인 컬렉션을 생성
collection = db.info컬렉션 변경
# UPDATE collections
db.user.rename('users')
list(db.list_collection_names())
>>> ['info1', 'info2', 'users']READ
## READ documents
# 콜렉션 접근
collection = db.info2
# 콜렉션에서 데이터 하나를 가져옴
document = collection.find_one({'subject': 'python'})
print(document)
>>> {'_id': ObjectId('644b20c314426a624b299f57'), 'subject': 'python', 'level': 1}
# 콜렉션에서 데이터를 여러개 가져옴
document = collection.find({'subject': 'python'})
print(document)
>>> <pymongo.cursor.Cursor object at 0x7fde05df8400>
print(list(document))
>>> [{'_id': ObjectId('644b20c314426a624b299f57'), 'subject': 'python', 'level': 1}]find_one을 사용할 경우 데이터가 딕셔너리 형태로 반환된다.
find를 사용할 경우 데이터 개수에 관계 없이 리스트 안의 딕셔너리 형태로 반환된다.
번외 : document 객체의 특징
# 콜렉션에서 데이터를 여러개 가져옴
document = collection.find({'level': {'$gte': 4}})
df = pd.DataFrame(document)
print(list(document))
>>> []document 객체를 이용해 판다스 데이터프레임을 생성했는데, 이후 객체를 리스트에 담아 출력해보면 빈 리스트가 출력된다.
이는 pymongo 객체의 특징으로, 한 번 사용되면 값이 사라지게 된다.
CREATE
## CREATE document
# 컬렉션에 삽입할 데이터
data = {'subject': 'brainfuck', 'level': '999'}
# 데이터 삽입
result = collection.insert_one(data)
print(result.inserted_id)
>>> 644b3929b303d32612a0bfddUPDATE
# UPDATE documents
collection.update_many({'subject': 'brainfuck'},
{'$set' : {'subject': 'brainfuxx', 'level':99}})
documents = collection.find({'subject': 'brainfuxx'})
print(list(documents))
>>> [{'_id': ObjectId('644b3929b303d32612a0bfdd'), 'subject': 'brainfuxx', 'level': 99}]위 코드들을 보면 알 수 있듯이, 기존 mongoDB에서 사용하는 문법을 거의 그대로 사용하고 있다.
추가로 pymongo는 상수값을 지원하기 때문에, 상수값을 잘못 기입하는 일 없이 참조하여 사용할 수 있다.
# 오름차순, 내림차순 상수값
print(pymongo.DESCENDING)
>>> -1
print(pymongo.ASCENDING)
>>> 1코멘트
아직 Flask를 통해 서버를 구축하는 과정이 남았다.
수업 시간이 부족해 진행하지 못했지만, AI 모델을 서버에 띄우는 것 역시 직접 진행해보고 정리하고 싶다.
불과 4일간의 수업이었지만, 하루 안에 정리하기도 벅찰만큼 많은 내용을 배우게 된 것 같다.
그래도 수업 때 전혀 이해가 가지 않거나 까먹었던 내용도 대략적으로 정리가 되는 것 같아 다행이다.
