
데이터 집계
집계 함수
SUM(합계), AVG(평균), MAX(최댓값), MIN(최솟값), COUNT(개수) 등, 데이터를 집계한 값을 출력해주는 SQL의 함수이다.
SUM, AVG는 숫자에만 사용할 수 있지만 MAX, MIN은 문자열에도 사용할 수 있다.
가령 날짜 형식의 문자열에 사용할 경우 MAX는 가장 최신 날짜, MIN은 가장 오래된 날짜를 나타낸다.
집계 함수는 NULL 값을 무시한다.
예를 들어 COUNT() 함수를 사용할 때 NULL을 제외하고 센다.
대신 COUNT(*) 함수를 통해 NULL 값을 포함하여 집계할 수 있다.
집계함수는 기본적으로 중복을 체크하지 않는다.
때문에 집계함수에 들어갈 컬럼에DISTINCT로 중복제거를 한다면 성능면에서 더 빠른 처리를 할 수 있다. (불러와야하는 데이터 양이 적기 때문)
GROUP BY
일반적을 범주형 데이터를 기준으로 데이터를 그룹핑하여 집계하기 위한 구문이다.
-- 성별별로 그룹핑 -> SUM 함수로 point 합계 집계
SELECT gender, SUM(point) AS sum_point
FROM customer
GROUP BY gender;FROM → WHERE → GROUP BY → SELECT → ORDER BY 순으로 처리된다.
GROUP BY에서 이미 그룹별로 묶인 상태이므로 SELECT에서는 그룹 기준 컬럼과 집계함수를 사용해야 정상적인(의도한) 결과를 얻을 수 있다.
DBMS에 따라 다르지만, GROUP BY를 사용한 쿼리문의 SELECT 절에서 그룹 기준 컬럼과 집계 함수 외의 컬럼이나 함수가 사용되면 에러를 출력한다. (이를 only_full_group_by라고 한다.)
GROUP BY 기준을 여러개 작성하여 중첩 사용하는 것 역시 가능하다.
-- 2019.01 ~ 2019.06 기간 주문에 대하여 주문연도별, 주문월별 전체금액 합
SELECT year(order_date) AS order_year,
month(order_date) AS order_month,
SUM(total_due) AS sum_due
FROM order_header
WHERE order_date BETWEEN '2019-01-01' AND '2019-06-30 23:59:59'
GROUP BY year(order_date), month(order_date);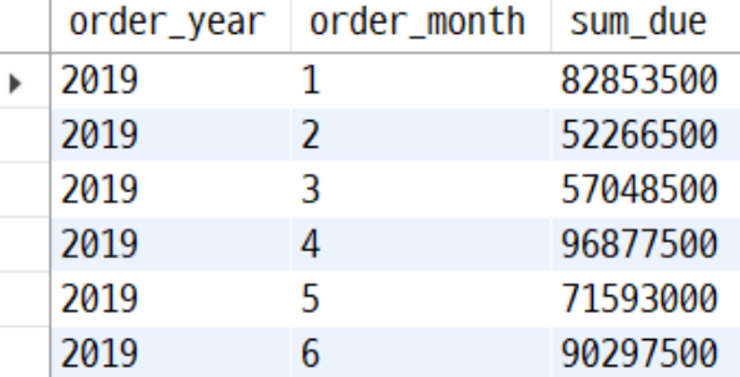
번외) 날짜 형식 비교시 주의점
일반적으로 날짜형식은
2023-05-09 22:05:18로 시간이 함께 지정되는 형태이다.
2023-05-09는2023-05-09 00:00:00과 같은 의미이다.
때문에 시간을 포함하여 월초 ~ 월말을 지정하고 싶은 경우'2019-06-30 23:59:59'이렇게 시간까지 명확이 명시해주어야 마지막 날을 포함할 수 있다.
GROUP BY 조건문
-- dept_id가 GEN인 데이터를 HRD로 간주하여 집계
SELECT IF (dept_id = 'GEN', 'HRD', dept_id) AS dept_id, COUNT(*) AS emp_count
FROM employee
WHERE retire_date IS NULL
GROUP BY IF (dept_id = 'GEN', 'HRD', dept_id);GROUP BY 절에도 조건문(IF, CASE)을 이용해서 집계 조건을 바꿀 수 있다.
서로 다른 범주를 하나의 범주로 집계하는 등 원하는 대로 집계 기준을 선택할 수 있다.
주의해야 할 점은 GROUP BY에서 사용한 조건문을 SELECT에서 그대로 사용해야 한다는 것이다.
번외) ORDER BY 조건문
ORDER BY에서도 조건문 사용이 가능하다.
예를 들어 어떤 컬럼을 제일 위로 출력하고 싶다면 ORDER BY 내에서만 조건문으로 그랩하여 'AAA' 같은 이름으로 간주하도록 할 수 있다.
이 경우 ORDER BY 절에서 정렬을 수행할 때만 ‘STG’를 ‘AAA’로 간주하는 것이기 때문에 정렬외의 출력 결과에는 아무런 영향을 주지 않는다.
HAVING
HAVING은 GROUP BY에 대한 조건을 지정하는 구문이다.
반드시 GROUP BY와 함께 사용해야 한다.
WHERE은 GROUP BY를 수행하기 이전 데이터를 걸러내는 과정이고,
HAVING은 GROUP BY를 수행한 후 SELECT를 수행하기 이전 데이터를 걸러내는 과정이다.
-- 직원수가 3명 이상인 부서만 그룹핑하여 직원수 출령
SELECT dept_id, COUNT(*) AS emp_count
FROM employee
WHERE retire_date IS NULL
GROUP BY dept_id
HAVING COUNT(*) >= 3
ORDER BY emp_count DESC;주의 사항 : 쿼리의 처리순서는 GROUP BY > HAVING > SELECT 이므로, HAVING에는 SELECT에서 사용 할 집계함수를 그대로 사용해야 한다.
예외적으로 MySQL에서는 SELECT의 선언된 별칭(Alias)를 HAVING 절에서도 사용할 수 있는데 다른 DBMS는 에러가 발생하는 경우가 많으므로 권장하지 않는다.
OVER
<집계함수 or 분석함수> OVER(ORDER BY <컬럼명> <정렬방법>)
집계 함수, 순위 함수 등을 GROUP BY 나 서브 쿼리 없이 사용할 수 있도록 해주는 함수이다.
내부에 ORDER BY 절을 지정하여 내부를 정렬된 상태로 출력할 수 있다.
-- OVER()
SELECT emp_name, dept_id, gender, salary,
COUNT(*) OVER() AS cnt
FROM employee
WHERE retire_date IS NULL
AND salary > 0;GROUP BY를 사용하지 않고 COUNT 집계 함수를 사용하였다.
-- OVER() + ORDER BY
SELECT emp_name, dept_id, gender, salary,
COUNT(*) OVER(ORDER BY emp_name) AS cnt,
SUM(salary) OVER(ORDER BY emp_name) AS tot_salary,
AVG(salary) OVER(ORDER BY emp_name) AS avg_salary
FROM employee
WHERE retire_date IS NULL
AND salary > 0;집계함수를 OVER(ORDER BY)절과 함께 사용할 경우 정렬된 방향으로 누적합, 이동평균 등을 쉽게 구할 수 있다.
RANK
RANK는 데이터에 저장된 값을 바탕으로 데이터 간의 순위를 매길 수 있는 함수이다.
RANK()
1, 2, 2, 4
일반적인 방법으로 순위를 매긴다.
DENSE_RANK()
1, 2, 2, 3
중복 순위가 발생하여도 사이에 빈공간을 허용하지 않는 순위 함수이다.
ROW_NUMBER()
1, 2, 3, 4
같은 숫자가 나오지 않도록 순위를 매긴다.
NTILE(3)
1, 1, 1, 2, 2, 2, 3, 3, 3
nTILE이란 n개의 타일을 의미함
순위 함수 중 유일하게 인자가 필요한 함수이며, 정수 n을 인자로 넣어주면 전체 데이터를 n개로 쪼개어 1에서 n까지 순위를 매긴다.
PARTITION BY
RANK() OVER(PARTITION BY <그룹 기준 컬럼명> ORDER BY <컬럼명> <정렬 방법>)
OVER를 이용한 집계 함수, 순위 함수에서 집계 및 순위 산정을 그룹별로 수행하고 싶을 때 사용한다.
하위쿼리 (서브쿼리)
하위쿼리는 쿼리문 안의 또다른 쿼리를 말한다.
예를들어 어떤 쿼리에서 SELECT로 생성한 컬럼이 있을 때, 이를 조건절 등으로 활용하는 또 다른 테이블을 만들고 싶다면, 컬럼을 생성하는 부분을 하위쿼리로 작성하고 별칭을 부여하면 된다.
SELECT *
FROM (SELECT emp_id, emp_name, dept_id, gender, phone, salary,
RANK() OVER(PARTITION BY gender ORDER BY salary DESC) AS rnk
FROM employee
WHERE retire_date IS NULL) AS T
WHERE rnk = 1;위 예시의 경우 FROM 절에 하위 쿼리를 넣고 별칭 T 를 부여했다.
이는 하위쿼리로 만들어진 T라는 이름의 테이블을 가져온 것과 같이 활용할 수 있다.
이 경우 조심할 점은 반드시 별칭을 부여해주어야 테이블이 생성된 것으로 취급한다는 점이다.
하위쿼리는 SELECT절 WHERE절 FROM절 등 다양한 곳에서 쓰일 수 있지만, FROM 절에서만 Alias를 지정해주어야 불러올 수 있다.
또한 하위쿼리에서는 ORDER BY를 쓸 수 없다.
다중 테이블 조회 (Join)
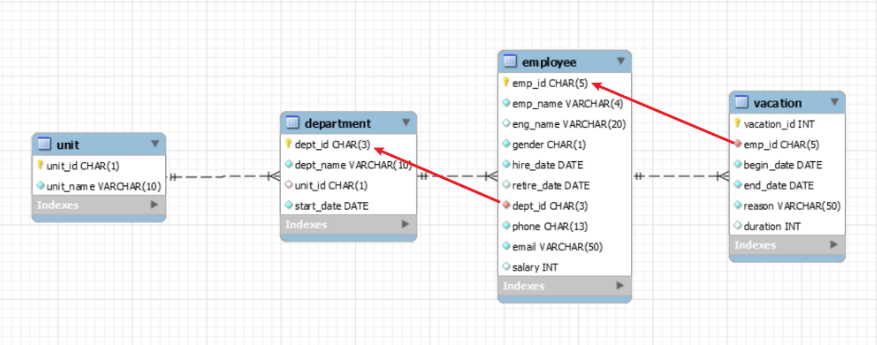
다른 테이블과 특정 컬럼을 기준으로 연결하여, 값을 가져와 사용하는 것을 join이라고 한다.
일반적으로 외래키(FK)를 이용해 조인을 하지만, 관계가 없는 컬럼끼리도 데이터 형식이 맞다면 조인을 할 수 있다.
예시
vacation 테이블에서 department 의 값을 참조하기 위해서는 3개의 테이블을 join해야한다.
emp_id외래키를 통해employee테이블에 join 한다.employee테이블에 존재하는dept_id외래키를 통해department테이블에 join 한다.- 이제 vacation에서 department 테이블의 값에 접근할 수 있게 되었다.
JOIN 구문
SELECT emp_id, emp_name, employee.dept_id, dept_name
FROM employee
JOIN department ON employee.dept_id = department.dept_id
WHERE retire_date IS NULL;JOIN department ON employee.dept_id = department.dept_idJOIN+ 조인할 테이블 명 +ON+ 조인 기준- 조인 기준은
<테이블 명>.<컬럼명>형식으로 어떤 테이블의 어떤 컬럼을 사용할 것인지 명시한다.
SELECT emp_id, emp_name, employee.dept_id, dept_namedept_id는 양쪽 테이블에 모두 존재하는 컬럼명이므로, 그냥 입력하면 DBMS가 어떤 테이블의 컬럼을 사용해야할 지 몰라 오류를 출력한다.
때문에 중복되는 컬럼명이 있다면 어느 테이블의 것인지 분명히 명시해야한다.- 되도록 JOIN을 호출한 테이블(FROM절에 있는 테이블)의 것을 사용한다.
Alias 활용
-- Alias
SELECT emp_id, emp_name, e.dept_id, dept_name
FROM employee AS e
JOIN department AS d ON e.dept_id = d.dept_id
WHERE retire_date IS NULL;테이블에 alias를 지정해주어, 긴 테이블명 대신 짧은 alias를 사용할 수 있다.
이때 별칭은 되도록 각 테이블을 구분할 수 있는 최소한의 길이로 작성한다. (가독성)
가독성을 위한 권장 사항
-- Alias
SELECT e.emp_id, e.emp_name, e.dept_id, d.dept_name
FROM employee AS e
JOIN department AS d ON e.dept_id = d.dept_id
WHERE e.retire_date IS NULL;쿼리를 작성할 당시는 상관 없지만, 나중에 쿼리를 다시 읽거나 다른 사람이 쿼리를 볼 때 어떤 컬럼이 어떤 테이블에서 온 것인지 파악하기 위해 되도록 모두 테이블(alias)을 명시해주는 것이 좋다.
중첩 조인
SELECT v.emp_id, e.emp_name, d.dept_name, e.gender, v.begin_date, v.reason, v.duration
FROM vacation AS v
JOIN employee AS e ON v.emp_id = e.emp_id
JOIN department AS d ON e.dept_id = d.dept_id
WHERE e.retire_date IS NULL;JOIN문을 여러개 중첩하여 여러 테이블을 조인할 수 있다.
INNER JOIN & OUTER JOIN
판다스의 merge 함수를 통해 데이터 프레임을 병합할 때 left, right, outer, inner 4가지 종류가 있었듯, SQL에서도 다양한 조인 방법이 있다.
INNER JOIN
양쪽의 데이터가 모두 맵핑되어야 조인이 이루어진다.
기본값이므로 생략하고 JOIN 만 작성할 경우 INNER JOIN이 이루어진다.
OUTER JOIN은 한쪽의 데이터만 맵핑된다면 조인이 이루어진다.
- LEFT OUTER JOIN
왼쪽(조인을 신청한) 테이블의 모든 데이터를 보존한다.
일대다 관계에서 1에 해당한다. (비교적 자주 사용)
- RIGHT OUTER JOIN
오른쪽(조인이 되는) 테이블의 모든 데이터를 보존한다.
- FULL OUTER
왼쪽, 오른쪽 모든 값을 보존한다. (MySQL에서는 지원하지 않음)
-- left outer
SELECT d.dept_id, d.dept_name, u.unit_name
FROM department AS d
LEFT OUTER JOIN unit AS u ON d.unit_id = u.unit_id;
-- inner
SELECT d.dept_id, d.dept_name, u.unit_name
FROM department AS d
INNER JOIN unit AS u ON d.unit_id = u.unit_id;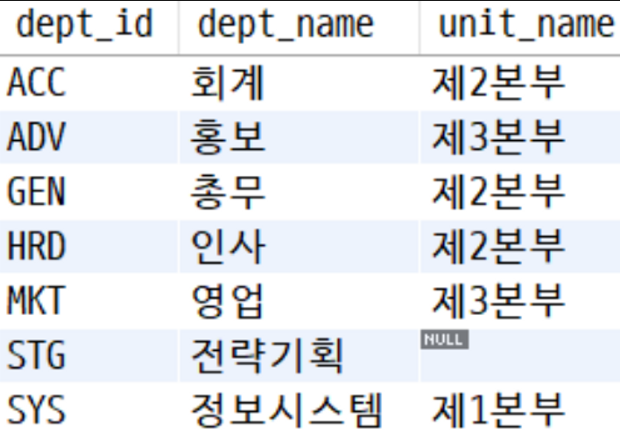
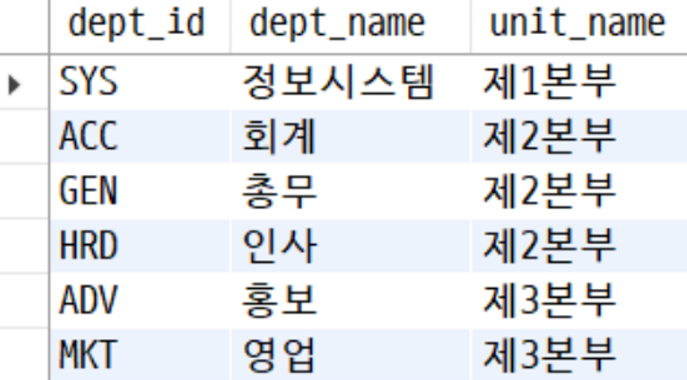
INNER에서는 unit_name 값이 NULL인 데이터가 조인에 포함되지 않았다.
반면 LEFT OUTER에서는 LEFT에 해당하는 department 테이블의 모든 데이터가 보존되었다.
CROSS JOIN
카티션 곱(Cartesian Product)를 수행하는 JOIN 방식이다.
한쪽 테이블의 모든 행 별로 다른 테이블의 모든 행을 조인한다.
가령 왼쪽 테이블에 데이터가 10개이고, 오른쪽 테이블에 데이터가 20개라면 CROSS JOIN의 결과로 10 * 20 = 200개의 데이터가 출력된다.
ON 절을 사용하지 않으며 중복, 맵핑 여부와 하나도 상관없이 모든 경우의 수 만큼의 행이 만들어진다
하위 쿼리
하위쿼리는 괄호안에 작성한 쿼리문으로, 다른 쿼리문에 의해 테이블 처럼 참조되는 쿼리이다.
-- 휴가를 간 적이 있는 정보시스템 직원
SELECT emp_id, emp_name, dept_id, phone, email
FROM employee
WHERE dept_id = 'SYS'
AND emp_id IN (SELECT DISTINCT emp_id FROM vacation);- 여기서 굳이 DISTINCT를 쓴 이유는 만약 해당 테이블 값에 중복이 있을 경우 조금이라도 테이블을 덜 들고오기 위해서이다.
상관 하위 쿼리
내부 쿼리 하나만으로는 쿼리가 독립적으로 시행되지 못할 때, 외부에서 넘겨진 쿼리 값을 갖고 수행되는 하위 쿼리를 상관 하위 쿼리라고 한다.
SELECT emp_id, emp_name, dept_id,
(SELECT dept_name FROM department WHERE dept_id = e.dept_id) AS dept_name,
phone, email, salary
FROM employee AS e
WHERE retire_date IS NULL;e.dept_id는 하위 쿼리에 없기 떄문에 바깥에서 선언된ealias를 가져와 사용한다.
EXISTS
EXISTS (<조건을 포함한 하위 쿼리>)
하위 쿼리의 조건만을 확인하는 구문이다.
SELECT emp_id, emp_name, dept_id, phone, email, salary
FROM employee AS e
WHERE EXISTS (
SELECT *
FROM vacation
WHERE emp_id = e.emp_id
) AND retire_date IS NULL;조건만을 판단하기 때문에 *을 사용하여도 성능에 영향이 없다
