혼자 공부하는 컴퓨터 구조+운영체제 책을 바탕으로 공부한 내용입니다.
노션에 정리한 것을 그대로 옮겨온 것으로, 일부 글자가 깨질 수 있습니다
Chapter 7. 보조기억장치
7-1. 다양한 보조기억장치
하드디스크
- 구성요소
- 플래터 : 실질적으로 데이터가 저장되는 동그란 원판, 0과 1을 기록하기 위해 자기물질로 덮여있다.
- 일반적으로 여러겹의 플래터로 이루어져있고, 양면을 모두 사용할 수 있다.
- 스핀들 : 플래터를 회전시키는 구성 요소
- 헤드 : 데이터를 읽고 쓰는 역할을 하는 구성 요소
- 플래터 : 실질적으로 데이터가 저장되는 동그란 원판, 0과 1을 기록하기 위해 자기물질로 덮여있다.
- 데이터를 저장하는 방법
- 트랙 : 플래터를 여러 동심원을 나누었을 때 각각의 원
- 섹터 : 한 트랙을 여러조각으로 나누었을 때 하나의 조각
- 한 섹터의 크기는 일반적으로 512바이트 ~ 4096바이트
- 실린더 : 여러겹의 플래터상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위
- 연속된 정보는 보통 하나의 실린더에 기록된다. (디스크 암을 움직이지 않고 접근 가능하므로)
- 데이터 접근 과정
- 탐색 시간 : 헤드가 접근하려는 데이터의 트랙까지 이동하는 시간
- 회전 지연 : 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간 : 하드디스크와 컴퓨터 간 데이터를 전송하는 시간
- 데이터 접근 시간을 줄이기 위해
- 물리적 : RPM을 높인다.
- 논리적 : 플래터 혹은 헤드를 조금만 움직여도 접근할 수 있도록 최적의 데이터 저장 위치를 결정
- 다중 헤드 디스크(고정 헤드 디스크)
- 트랙별로 헤드가 달려있어 탐색 시간이 필요없는 하드디스크 구조를 말한다.
- 반대로 헤드가 하나만 있어 탐색 시간이 필요한 헤드 디스크를 ‘이동 헤드 디스크’라고 한다.
플래시 메모리
- USB, SD 카드, SSD가 모두 플래시 메모리 기반의 보조기억장치이다.
- 보조기억장치 뿐 아니라 다양한 곳에서 널리 사용한다.
- 셀 : 플래시 메모리에서 데이터를 저장하는 가장 작은 단위로, 한 셀에 몇비트를 저장할 수 있느냐에 따라 플래시 메모리 종류가 나뉜다.
- SLC : 한 셀에 1비트 (한 셀에 2개의 정보)
- 빠른 입출력이 가능하다. (고성능)
- MLC 및 TLC보다 긴 수명을 갖는다.
- 용량 대비 가격이 높다.
- MLC : 한 셀에 2비트 (한 셀에 4개의 정보)
- SLC와 TLC의 중간정도의 성능, 용량 대비 가격, 수명을 갖는다.
- TLC : 한 셀에 3비트 (한 셀에 8개의 정보)
- 용량 대비 가격이 가장 저렴하다.
- SLC나 MLC보다 수명과 속도가 떨어진다.
- SLC : 한 셀에 1비트 (한 셀에 2개의 정보)
- 셀보다 더 큰 단위 : 셀 → 페이지 → 블록 → 플레인 → 다이
- 읽기와 쓰기는 페이지 단위로 이루어진다.
- 삭제는 블록 단위로 이루어진다.
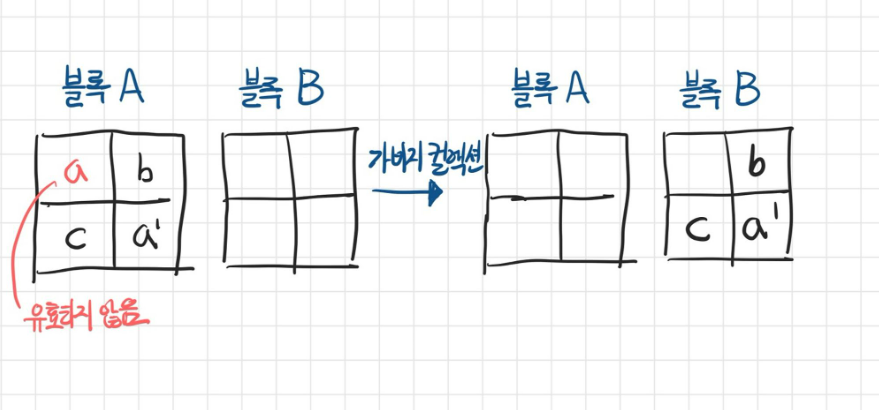
- 데이터를 읽고 쓸 때 페이지는 세 개의 상태를 가질 수 있다.
- Free : 저장된 데이터가 없음
- Valid : 이미 유효한 데이터를 저장하고 있음
- Invalid : 유효하지 않은 데이터를 저장하고 있음 (삭제 해야 새로 쓸 수 있다)
- 삭제는 블록 단위로 가능하기 때문에, 블록 내부에는 덮어쓸 수 없는 낭비되는 공간이 존재하게 되는데, 이를 정리하기 위해 가비지 컬렉션 기능을 제공한다.
7-2. RAID의 정의와 종류
- RAID : 보조기억장치를 안전하고 빠르게 활용하는 방법
RAID의 정의
- 상대적으로 장은 용량의 여러 개 물리적 보조기억장치를 합쳐 하나의 논리적 보조기억장치로 사용하는 기술
- 데이터의 안정성을 높일 수 있다. (하나의 보조기억장치가 고장이나도 복구가 가능)
- 큰 보조기억장치 하나를 사용하는 것 보다 더 빠르게 데이터를 입출력 할 수 있다.
RAID의 종류
- RAID 구성 방법은 여러가지인데 이러한 구성 방법을 RAID 레벨이라 표현한다.
- RAID 0
- 여러 개의 보조기억장치에 데이터를 나누어 저장하는 방식
- A라는 파일이 있다면 이를 보조기억장치 만큼 쪼개서 나누어 저장한다.
- 이렇게 줄무늬처럼 분산되어 저장하는 것을 스트라이핑이라하며, 분산된 데이터를 스트라입이라 한다. 이렇게하면 하나의 데이터를 동시에 읽고 쓸 수 있기 때문에 데이터의 입출력속도가 빨라진다. (4TB 한 개보다 1TB 4개가 이론상 4배 빠름)
- 다만 여러 보조기억장치중 하나라도 고장이 난다면 모든 장치의 정보를 읽는데 문제가 생길 수 있다.
- RAID 1
- 거울처럼 완전한 복사본을 만드는 방법으로, 미러링이라고도 한다.
- 복구가 매우 간단하다는 장점이 있지만, 사용 가능한 용량이 절반이 되는 단점이 있다.
- RAID 4
- 오류를 검출하고 복구하기 위한 정보인 패리티 비트를 이용하여 RAID 1보다 적은 보조기억장치로 오류 검출 및 데이터 복구가 가능하다.
- 패리티 비트는 본래 오류를 검출할 수만 있지만, RAID에서는 오류 복구 역시 가능하다.
- RAID 5
- RAID 4는 새로운 데이터가 저장될 때마다 패리티를 저장하는 디스크에도 데이터를 저장해야하므로, 패리티를 저장하는 장치에 병목현상이 발생하는 문제가 있다.
- RAID 5는 모든 보조기억장치에 패리티 정보를 분산하여 저장한다.
- RAID 6
- RAID 5와 같은 구성이지만, 같은 패리티 비트를 두 개의 보조기억장치에 나누어 저장한다.
- RAID 4, RAID 5보다 정보를 안전하게 저장할 수 있다.
- 대신 쓰기 속도가 느리다는 단점이 있다.
- Nested RAID : RAID 방식을 혼합한 방식이다. 예를들어 RAID 10은 RAID 0과 RAID 1을 혼합한 것이다. 이러한 구조를 Nested RAID라고 한다.
Chapter 8. 입출력장치
8-1. 장치 컨트롤러와 장치 드라이버
장치 컨트롤러
- 입출력장치는 종류가 매우 다양하기 때문에, 장치별로 정보를 주고받는 방식을 규격화하기가 어렵다.
- 입출력장치는 데이터 전송률이 일반적으로 낮기 때문에, CPU와 원활한 통신을 하기 어렵다.
- 전송률 : 데이터를 얼마나 빨리 교환할 수 있는지 나타내는 지표
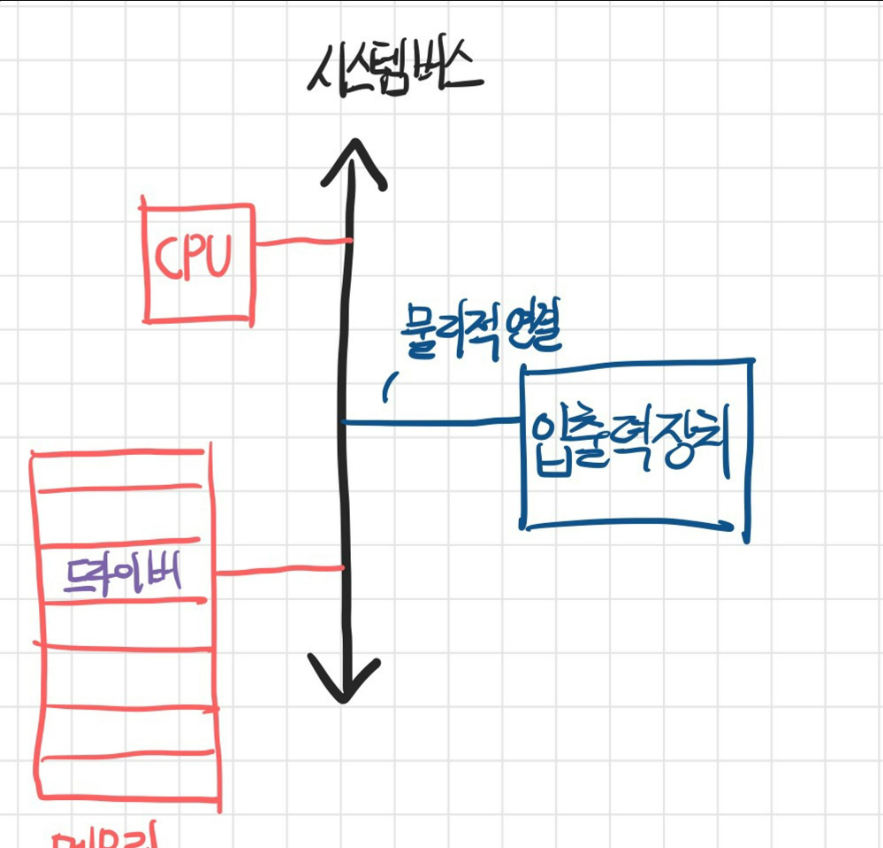
- 이러한 이유로 입출력장치는 컴퓨터에 직접 연결되지 않고 장치 컨트롤러라는 하드웨어를 통해 연결된다.
- 모든 입출력 장치는 장치 컨트롤러를 통해 컴퓨터 내부와 정보를 주고 받는다.
- 각 장치 컨트롤러는 하나 이상의 입출력 장치와 연결된다.
- 장치 컨트롤러의 역할
- CPU와 입출력장치 간의 통신 중개
- 오류 검출
- 데이터 버퍼링
- 버퍼링 : 전송률이 다른 장치 사이의 원활한 통신을 위해 데이터를 버퍼라는 임시 저장 공간에 저장하는 것. 전송률을 비슷하게 맞추는 효과가 있다.
- 일반적으로 빠른쪽에서 보낸 데이터를 천천하게 전송하는 역할, 느린쪽에서 보낸 데이터를 모았다가 한번에 전송하는 역할을 한다.
- 장치 컨트롤러의 내부 구조
- 데이터 레지스터
- 서로 주고받을 데이터가 담기는 레지스터 (버퍼 역할)
- 주고 받는 데이터가 많을 경우 레지스터 대신 RAM을 사용하기도 한다.
- 상태 레지스터
- 입출력 관련 작업 상태 정보를 저장
- 제어 레지스터
- 입출력장치가 수행할 내용에 대한 제어 정보 및 명령 저장
- 데이터 레지스터
장치 드라이버
- 장치 컨트롤러가 컴퓨터 내부와 정보를 주고받을 수 있게하는 프로그램
- 새로운 장치를 연결하여 사용하려면 장치 드라이버를 설치해야 한다.
- 최종적으로 입출력장치와 컴퓨터가 연결된 구조는 다음 그림과 같다.
8-2. 다양한 입출력 방법
- 프로그램 입출력, 인터럽트 기반 입출력, DMA 입출력 크게 세 가지가 있다.
프로그램 입출력
- 프로그램(입출력 컨트롤러) 속 명령어를 통해 입출력 장치를 제어
- CPU가 하드디스크에 새 정보를 쓰려는 경우
- CPU가 제어 레지스터에 ‘쓰기’ 명령어 전송
- 하드디스크 컨트롤러는 하드디스크의 상태를 확인하고 ‘준비’ 상태를 상태 레지스터에 저장
- CPU는 준비가 완료될때까지, 상태 레지스터를 체크하고, 준비가 확인되면 데이터 레지스터에 데이터 전송
- CPU가 하드디스크에 새 정보를 쓰려는 경우
- 이러한 입출력을 수행하기 위해서는 CPU가 각 장치 컨트롤러 속 레지스터의 주소를 알고 있어야 한다. 이를 구현하는 2가지 방식이 있다.
- 문제는 매번 cpu가 검사를 해주어야 입출력이 이루어지기 때문에, cpu가 짧은 주기로 체크하면 cpu 효율이 감소하고, 반대로 너무 긴 주기로 체크하면 입출력에 지연이 발생한다는 단점이 있다.
ㄴ 메모리 맵 입출력
- 하나의 주소 공간에 메모리르 위한 주소 공간, 입출력장치를 위한 주소 공간을 나누어 사용한다.
- 메모리 주소를 사용하듯 주소 접근이 가능하기 때문에 메모리 접근과 동일한 명령어를 사용할 수 있다.
- 메모리 주소 공간이 축소된다는 단점이 있다.
- 주로 임베디드나 RISC 시스템에서 주로 사용
ㄴ 고립형 입출력
- 메모리를 위한 주소 공간과, 입출력장치를 위한 주소 공간을 분리하는 방법
- 대신 제어버스에 메모리에 접근하기 위한 제어버스와 장치 컨트롤러에 접근하기 위한 제어버스를 따로 둔다. (별개의 선)
- 사용할 제어버스가 다르기 때문에 서로 다른 입출력 명령어를 사용해야한다는 단점이 있다.
- 주로 Intel 계열에서 사용하며, 프로세서 칩셋에 물리적인 신호판을 두어 IO명령을 전달한다.
인터럽트 기반 입출력
- 앞서 배웠던 인터럽트를 통해 CPU와 입출력을 주고 받는다.
- CPU의 명령을 받고 인터럽트를 보내는 것은 장치 컨트롤러가 수행한다.
- 앞서 프로그램 입출력 방식에서는 CPU가 주기적으로 장치 컨트롤러의 상태 레지스터를 체크해야 했다. 이를 폴링(polling)이라고 하는데, 인터럽트 기반 입출력에서는 폴링이 필요 없기 때문에 CPU의 부담이 감소한다.
- 입출력 장치는 매우 많기 때문에 동시에 여러 인터럽트가 발생할 수 있다. 이러한 경우 어떤 인터럽트를 먼저 처리할지 결정하는 방법이 중요한 요소이다.
- 이를 위해 인터럽트에 우선순위를 부여하여, 우선순위가 높은 인터럽트 부터 처리한다.
- 우선 순위가 낮은 인터럽트가 먼저 처리중이라고 하더라도, 우선 순위가 높은 인터럽트가 들어오면, 높은 쪽 부터 처리한다.
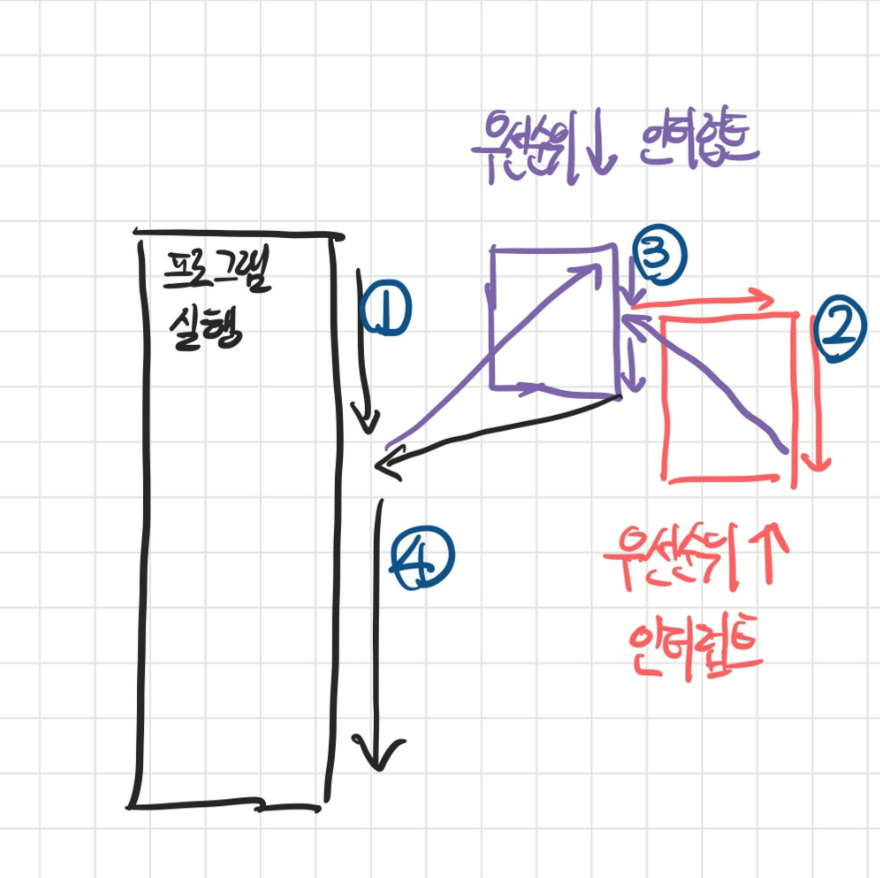
- 컴퓨터는 이러한 다중 인터럽트에 우선순위를 부여하기 위해 프로그래머블 인터럽트 컨트롤러(PIC) 라는 하드웨어를 사용한다.
- PIC는 입출력 장치의 인터럽트를 보낼 수 있는 약속된 하드웨어와 물리적으로 연결되어있다.
- PIC에 다중 인터럽트가 들어오면 PIC가 우선순위를 판단하여 CPU에 처리할 인터럽트 요청 신호를 보낸다.
- 일반적으로 더 많고 복잡한 장치의 인터럽트를 관리하기 위해 PIC를 두 개 이상 계층으로 구성한다.
- NMI(Non-Maskable Interrupt)는 플래그 레지스터의 인터럽트 비트와 상관없이 최우선 처리되는 인터럽트로, PIC의 판단을 거치지 않는다.
DMA 입출력
- 프로그램 입출력과 인터럽트 기반 입출력은 모두 CPU를 거쳐서 이루어진다.
- DMA(Direct Memory Access)는 CPU를 거치지 않고 입출력장치와 메모리간 상호작용할 수 있는 입출력 방식이다.
- DMA 입출력을 위해서는 시스템 버스에 DMA 컨트롤러라는 별도 하드웨어가 필요하다.
DMA 입출력 과정
- CPU가 입출력장치에 명령을 한 경우
- CPU가 DMA 컨트롤러에 필요한 정보 및 작업 명령을 전송한다.
- DMA가 장치 컨트롤러와 직접 상호작용하고, 메모리에 접근하면서 작업을 수행한다.
- 작업이 완료되면 DMA가 CPU에 작업 완료 인터럽트를 전송한다.
- CPU는 작업의 시작과 끝에만 관여하기 때문에 작업 부담이 훨씬 감소한다.
- 단, 시스템버스는 공용자원이기 때문에 CPU와 DMA가 동시에 시스템버스를 사용할 수 없다는 단점이 있다. (DMA의 작업으로 CPU가 시스템 버스를 사용할 수 없는 상황을 사이클 스틸이라 한다)
- CPU가 시스템 버스를 사용하지 않을 때마다 DMA가 사용하거나
- CPU가 시스템 버스를 이용하지 않도록 하고 집중적으로 이용하는 방법이있다.
입출력 버스
- DMA가 시스템 버스를 너무 너무 오래 사용하면, CPU가 시스템 버스를 이용할 수 있는 시간이 감소한다. 이를 위해 입출력 버스라는 별도의 버스에 DMA와 장치 컨트롤러를 연결하는 방법이 있다.
- 입출력 버스에는 PCI버스, PCIe 버스 등 다양한 종류가 존재한다. 이러한 버스를 연결해주는 통로를 PCIe 슬롯이라고 한다.
- 최근에는 입출력 장치에 입출력 전용 CPU가 탑재되어 아예 컴퓨터의 CPU를 거치지 않고 컴퓨터 내부와 데이터를 주고받는 경우가 있다.
