Practical Gradient Descent Methods
Batch 사이즈에 따른 Gradient Descent
- 10만개의 데이터가 있다고 가정을 했을 때, 데이터를 한번에 얼마만큼 사용하는지에 따라 Gradient Descent를 크게 3가지로 분류할 수 있다.
Stochastic gradient descent (SGD)
- 한번에 하나의 데이터만을 사용하여 gradient를 구하고, 이를 반복하며 gradient를 업데이트 한다.
- 시간이 오래 걸린다는 단점이 있다.
Mini-batch
- batch size(64, 128 ... 등)를 정하여 batch 사이즈 만큼의 데이터를 묶어 사용한다.
- 가장 대중적으로 사용하는 방법이다.
Batch gradient descent
- 모든 데이터를 다 써서 gradient를 업데이트 한다.
Batch 사이즈의 영향
- batch size가 클수록 sharp minimizers에 도달한다.
- 반대로 batch size가 작을수록 flat minimizers에 도달한다.
- flat minimizers에 도달할 수 있도록 batch size를 선정하는 것이 좋다.
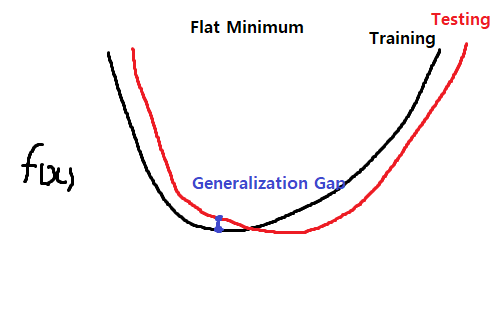
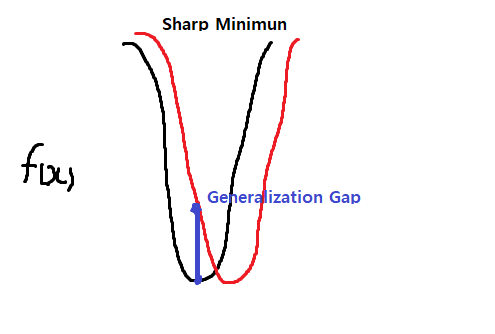
- 위 그림처럼 sharp minimum은 학습하지 않은 테스트 데이터에 대해 잘 동작하지 않을 위험이 높다. (Generalization Performance가 떨어진다)
Practical Gradient Descent 방법론
Basic
- 제일 기본적인 형태의 Gradient Descent는 다음과 같다.
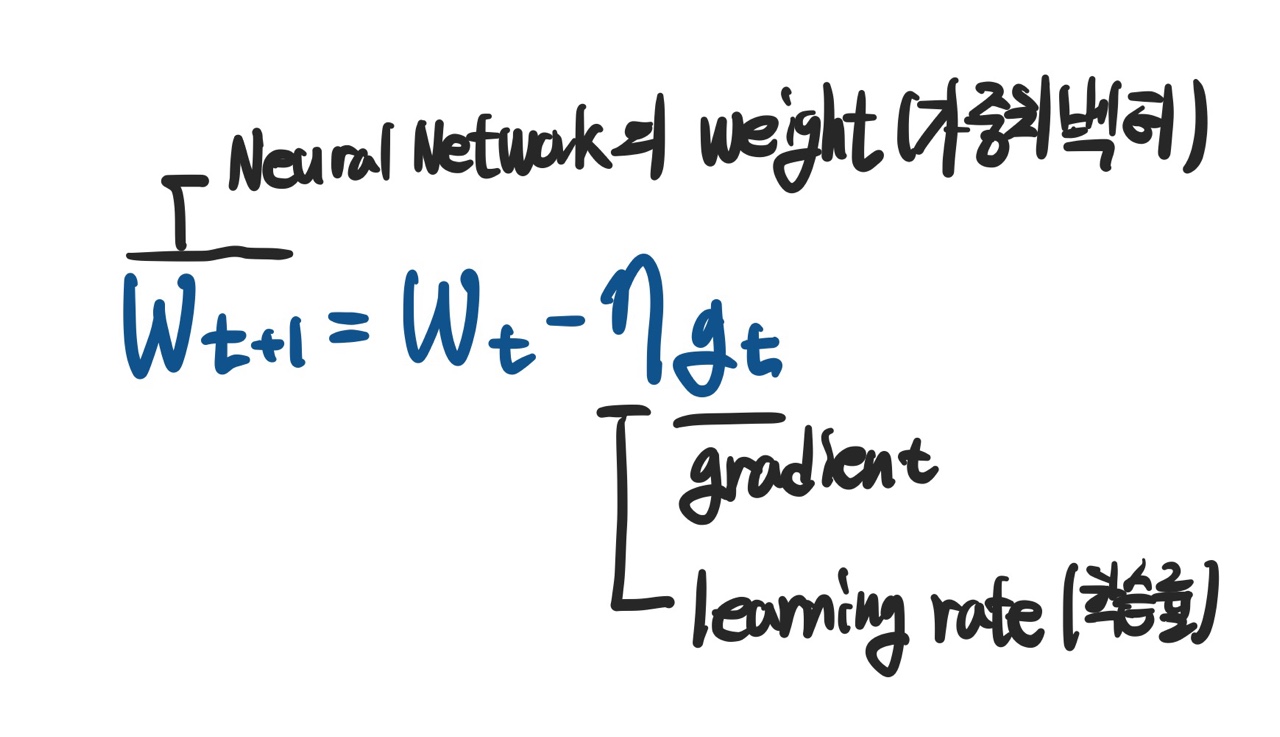
- 이 방법의 단점은 learning rate를 잡는 것이 너무 어렵다는 것이다.
- 너무 높으면 극소값을 찾을 수 없고, 너무 낮으면 학습에 걸리는 시간이 매우 길어진다.
Momentum
- 관성이라는 이름대로 이전에 구한 gradient 값을 현재 gradient에 반영하는 방법이다
- 이전의 값과 새로 구한 값을 통해
accumulation을 계산하여 사용한다.
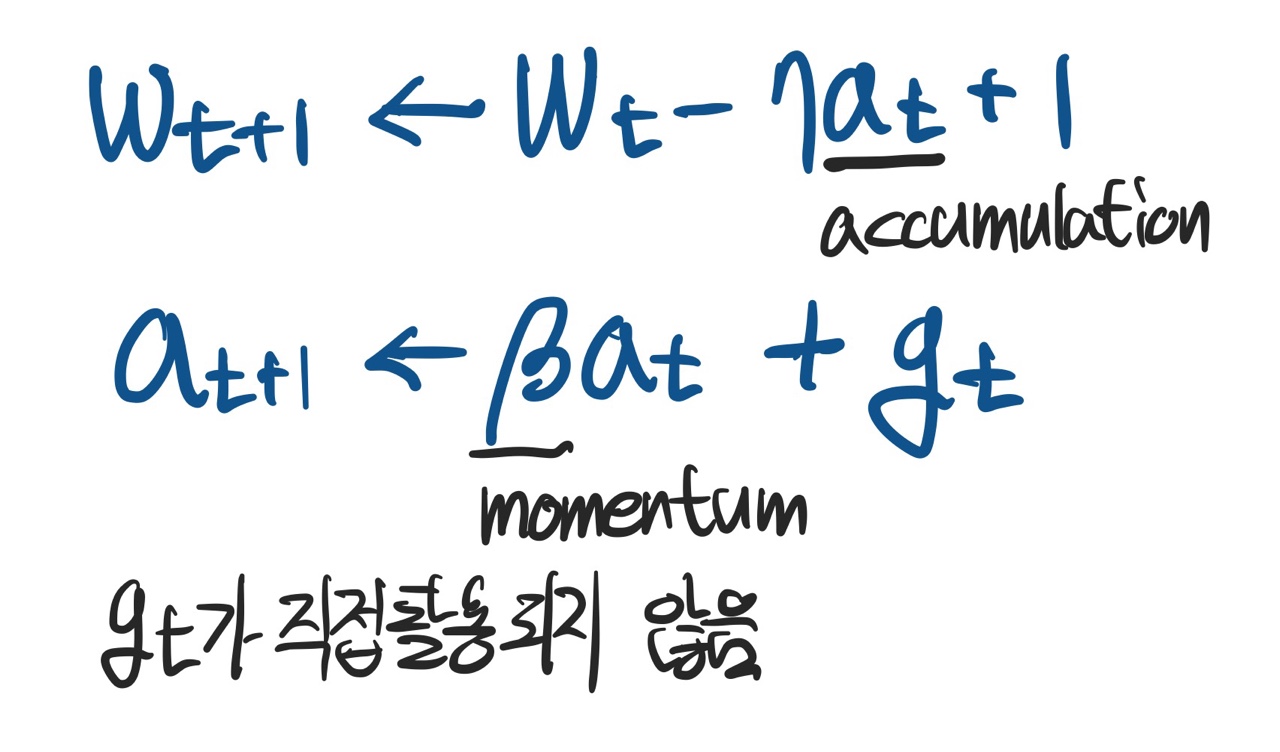
-
momentum 역시 hyper parameter로 사용자가 설정할 수 있다.
-
장점 : 데이터에 따라 gradient 방향이 자주 바뀌어도 결국 관성에 의해 한 방향으로 나가 학습이 잘 이루어진다.
-
단점 : momentum에 의해 local minimum의 주변을 계속 반복해서 돌면서 극소값으로 coversing을 이루지 못하는 현상이 발생한다.
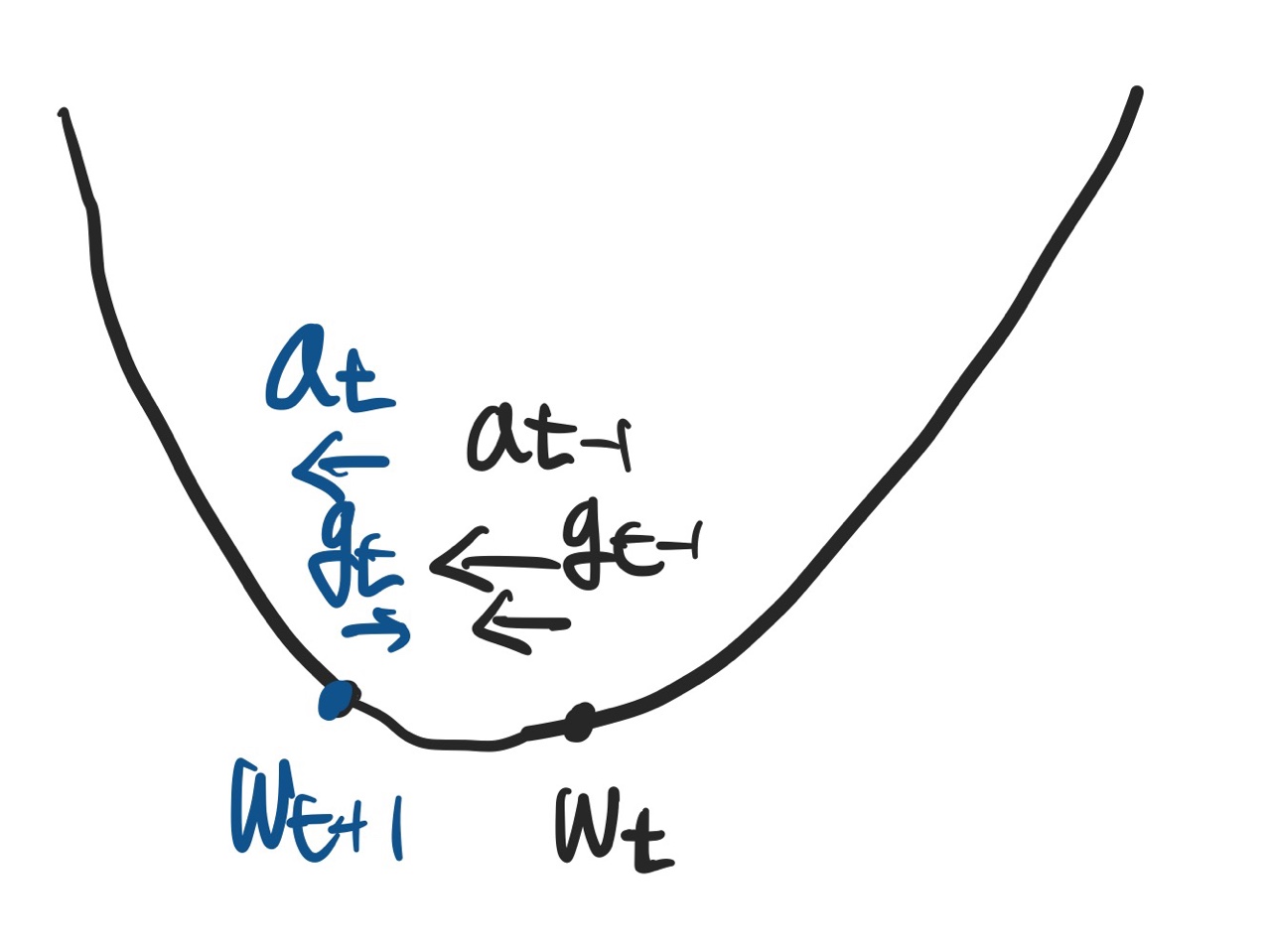
Nesterov Accelerated Gradient (NAG)
- momentum의 단점을 개선한 방법이다.
- 현재 위치에서 계산한 accumulation 정보를 바탕으로
Lookahead gradient를 계산하여 새로운 accumulation을 계산한다.
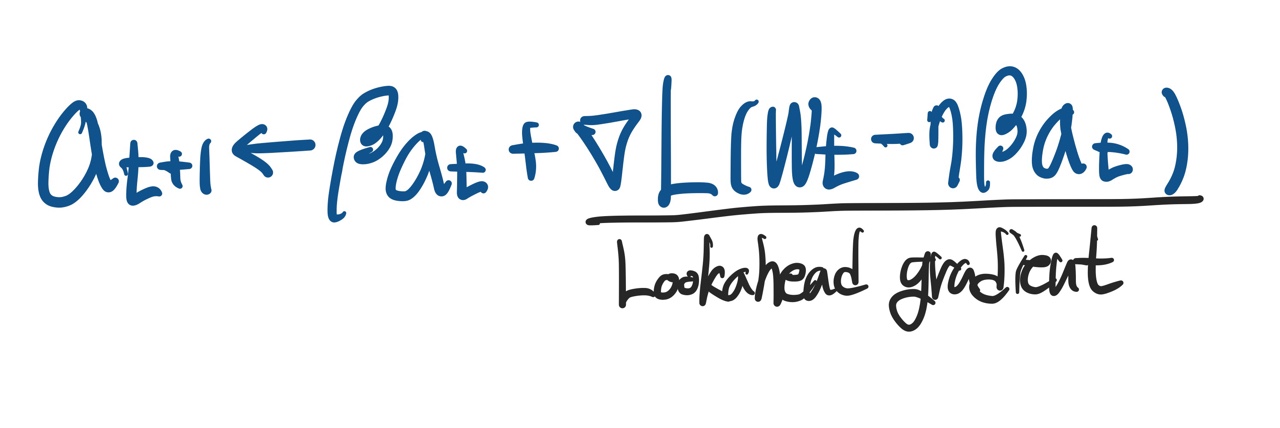
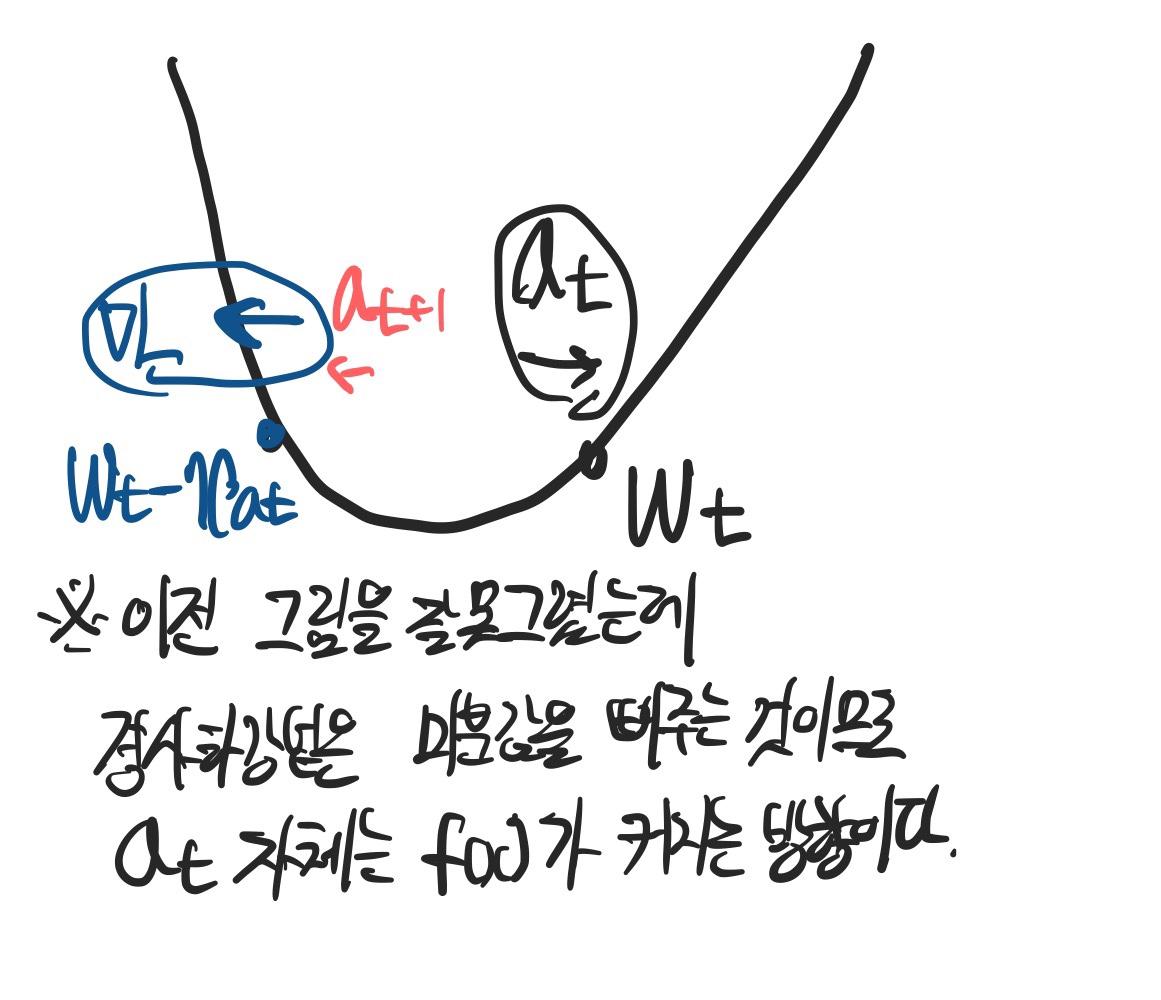
- 한번 지나간 자리에서 새로운 gradient를 계산하기 때문에 local minimal에 도달하는 accumulation을 계산할 수 있다.
Adagrad (ADA)
- momentum과는 다른 접근으로, 현재까지의 파라미터 변화량을 반영하여 파라미터를 업데이트 하는 방법론이다.
- 많이 변한 파라미터는 적게 변화하도록, 적게 변한 파라미터는 많이 변화하도록 조정된다.
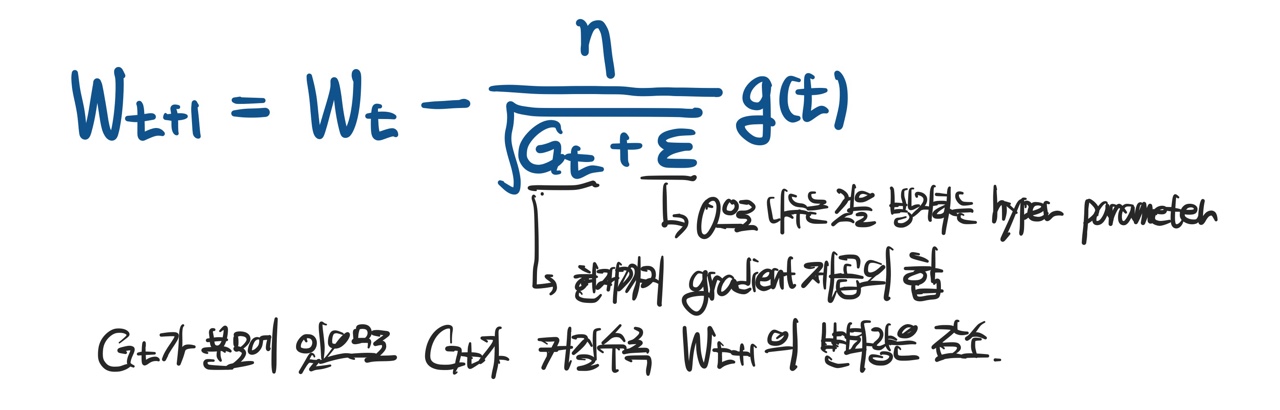
- 단점 : 학습이 진행되어 Gt가 계속커지게 되면 gradient가 0에 수렴하게 된다. 즉 학습이 멈추는 현상이 발생한다.
Adadelta
- Adagrad에서 Gt가 계속 커져 학습이 멈추는 문제를 개선한 방법론이다.
- EMA(Exponential Moving Average)를 이용해 Gt를 업데이트 한다.
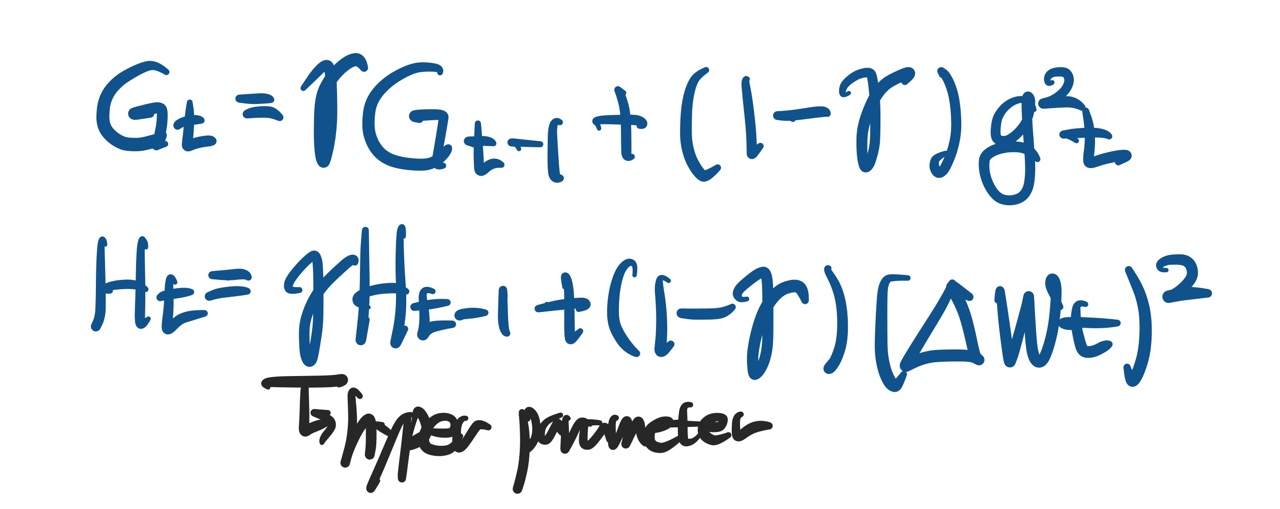
- Adadelta의 특징으로
W의 변화량에 대한 EMA값인H를 learning rate 대신에 사용한다는 것이다. - 이는 사용자가 설정할 수 있는 hyper parameter가 그만큼 적어진다는 의미로, 이로 인해 많이 사용되지 않는다.
RMSprop
- 논문을 통해 제안된 방법이 아닌, 강의중에 소개된 방법이다.
- 실제로 사용해보니 정말로 성능이 좋아서 많이 쓰였다. - Adadelta에서
H대신 learning rate를 쓴다는 것이 유일한 차이점이다.
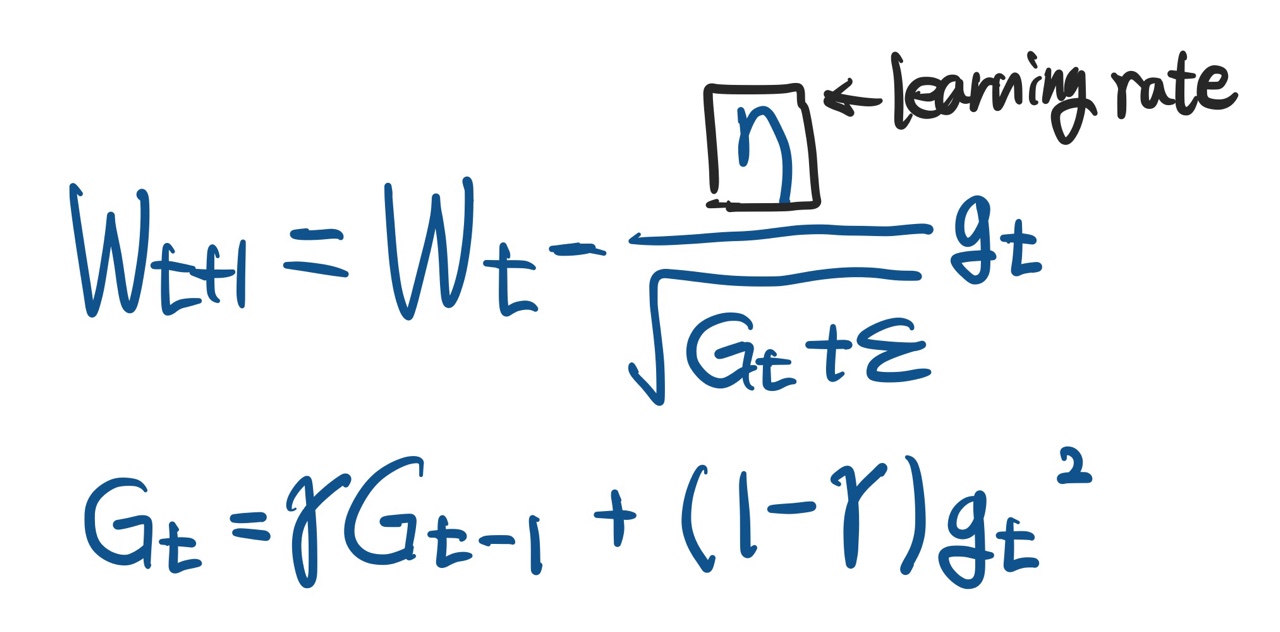
Adam (Adaptive Moment EstiMation)
- momentum과 EMA of gradient squares 두가지를 모두 사용하여 gradient를 계산한다.
- 가장 널리 사용되는 모델이다.

- 공식을 모두 외울 필요는 없다 (프로그래밍 단계에서는 결국 코드 한줄 바꾸면 되기 때문)
- 어떤 개념인지, 어떤 성질이 있는지를 잘 알자!
