

Sequential Model
Sequential Model이란 연속적인 입력으로부터 연속적인 출력을 생성하는 모델이다.- 일상생활에서 접하는 대부분의 데이터(Audio, Video, 동작 등)는
sequential data형태이기 때문에 이를 다루는 것을 목표로 한다. - 어려움 : 얻고 싶은 것은 결국 하나의 라벨(one-out vector)또는 하나의 정보인데, sequential data는 데이터가 언제 끝날지 알 수 없다. 즉 input의 차원을 알 수 없다.
Sequential Model의 종류
Naive sequence model
- 가장 기본적인 모델로, t번째 입력이 들어왔을 때 t-1, t-2 ... t=1까지의 output을 모두 고려해서 t번째 output을 생성하는 모델이다.
- input이 늘어날수록 고려해야할 data가 늘어난다는 문제가 있다.
p(
xt|xt-1,xt-2, ...)
Autoregressive model
- 현재 t에 대한 output은 과거 n개의 output에 의존한다고 가정하는 모델이다.
- 과거 1개에 dependent하다면
AR(1), 2개에 dependent하다면AR(2)와 같이 표기한다.
p(
xt|xt-1,xt-2, ... ,xt-n)
Markov model (first-order autoregressive model)
- t+1번째의 상태(state)는 오직 t번째에 상태에만 영향을 받는
Markov 성질을 가정한 모델이다. - 장점 : joint distribution(결합확률분포)를 표현하기 쉽다.
- joint distribution : 두 개 이상의 확률변수에 대한 확률분포 - 단점 : 과거의 더 많은 정보를 고려할 수 없다.
- 예를들어 내일 수능의 성적은 오직 오늘 공부한 양에 의해서만 결정된다는 것과 같다.
Latent autoregressive model
- Markov model과 동일하게 과거 하나의 데이터에만 영향을 받지만, 그 과거 데이터로 이전 정보를 summarize한
hidden state(h)를 사용한다. - Input
xt를 그대로 사용하지 않고,xt-1에서 얻은ht와xt를 통해 얻은ht+1을 사용한다.
X̂ = p(
xt|ht)
ht= g(gt-1,xt-1)
Recurrent Neural Network
아래에 나오는 모든 자료는 colah 님의 블로그에서 가져온 자료입니다.
- Sequential Model을 구현할 수 있는 방법 중 하나가 바로
RNN(Recurrent Neural Networks)이다. - MLP와 거의 동일하지만, 자기자신으로 돌아오는 구조가 있다는 차이를 갖는다.
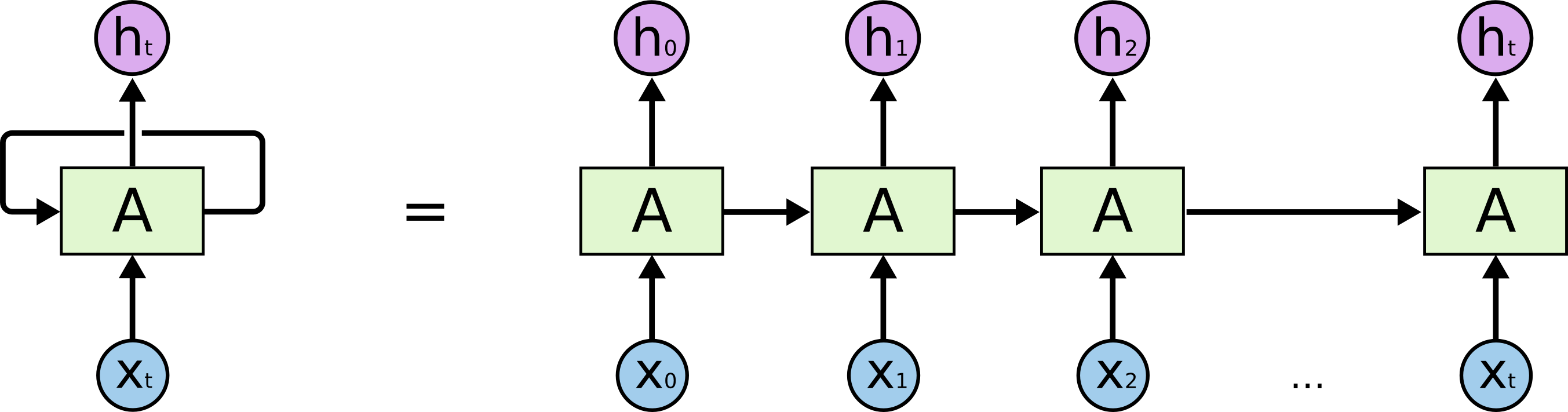
- RNN을 시간순으로 풀면(unroll) t는 t-1에서 전달된 정보에 의존함을 알 수 있다.
- 이는 입력이 굉장히 많은 fully connected layer로 표현될 수 있다.
RNN dependencies
Short-term dependencies란
- 현재시점 t로부터 멀리떨어진 과거의 정보는
ht에 거의 영향을 주지 못하게 된다. (과거 정보를 summary한 A에서 점점 비중이 작아지므로) - 예를들어 번역기에서 문장이 길어지는 경우, 먼 문장의 정보를 활용하지 못한다.
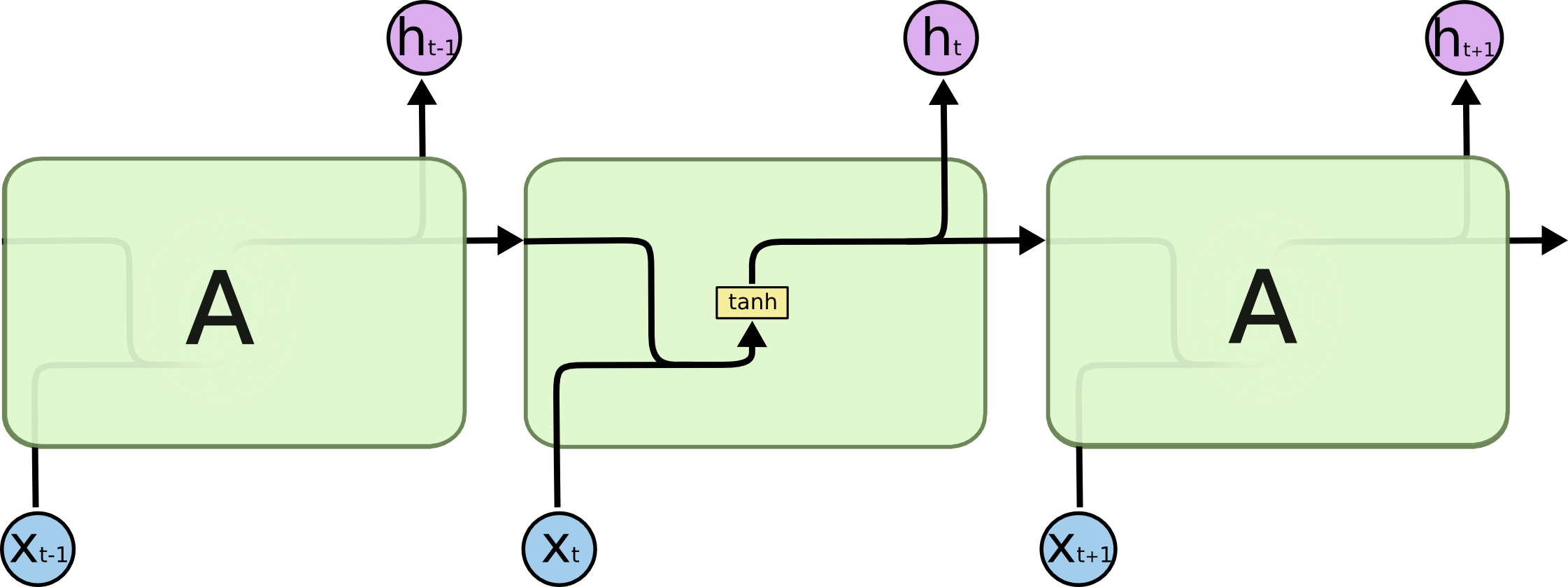
예시
- RNN에서 h1은 출발점
h0과 inputx1에 신경망의 weight를 곱하고, 활성함수의 넣은 값을 사용해 생성된다. - 이것이 중첩되면
ht에서h0의 영향은 활성함수와 weight를 t번 거친 값을 갖게 된다. - 이때 활성함수로 ReLU를 사용한다면, 양수 W가 계속 곱해져서 W의 t제곱을
h0에 곱하게 된다. 즉h0가 지수적으로 커져 exploding gradient(쉽게 말해 network가 폭발하는 것)가 발생한다. - 반면에 활성함수로 sigmoid(실수 입력값을 0~1 사이의 미분 가능한 수로 변환)를 사용한다면,
h0은 매우 작아져 의미가 없어지게 된다.
Long-term dependencies
- 멀리 떨어진 과거의 정보도 현재에 영향을 주는 것을 말한다.
- 이를 위해 LSTM이라는 새로운 모델이 출현했다.
Long Short Term Memory(LSTM)
- 이전 RNN(Vanilla RNN)의 구조는 다음과 같다.
LSTM의 구조
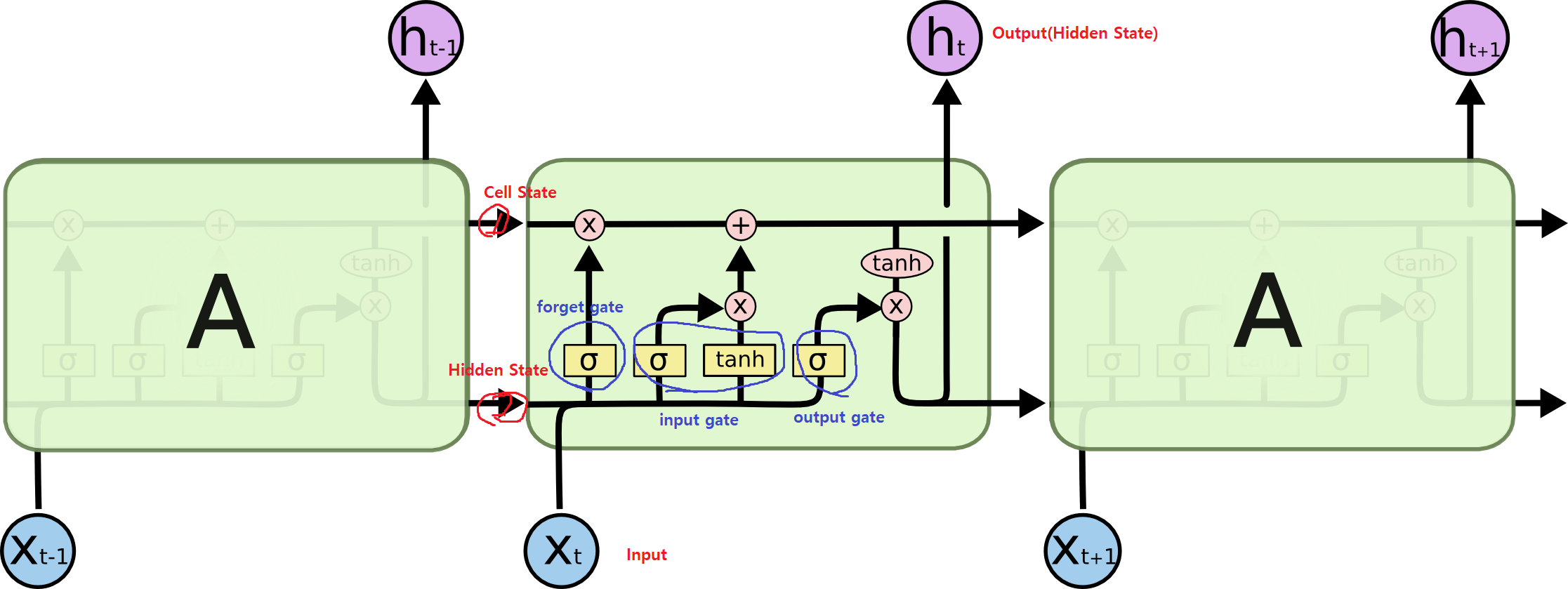
1. Cell State
- Vanilla RNN과의 가장 큰 차이점으로, 0부터 t까지의 정보를 summarize한 것이다.
- output으로 출력되지 않고, 내부에서만 처리되어 다음 cell state로 전달된다.
- 일종의 컨베이어 벨트와 같다.
2. Hidden State
- t-1에서 output으로 출력된
ht-1을 말한다.
3. Gate
- 말그대로 일종의 관문으로, 3가지 입력 데이터(input, cell state, hidden state)를 조작하고, 빼고, 더하는 것으로 의미있는 정보만을 남기는 역할을 한다.
- LSTM에서는
forget gate,input gate,output gate3가지로 구성된다.
LSTM Gate
Forget gate
- Previous Cell State에서 어떤 정보를 버릴지 결정하는 게이트이다.
- Forget gate의 output(
ft)은Ct-1에 대응되는 0~1 사이의 값을 갖는다.- 0은
Ct-1의 해당 데이터를 완전히 잊어버린다는 뜻 - 1은
Ct-1의 해당 데이터를 완전히 기억하고 가져간다는 뜻이다.
- 0은
Input gate
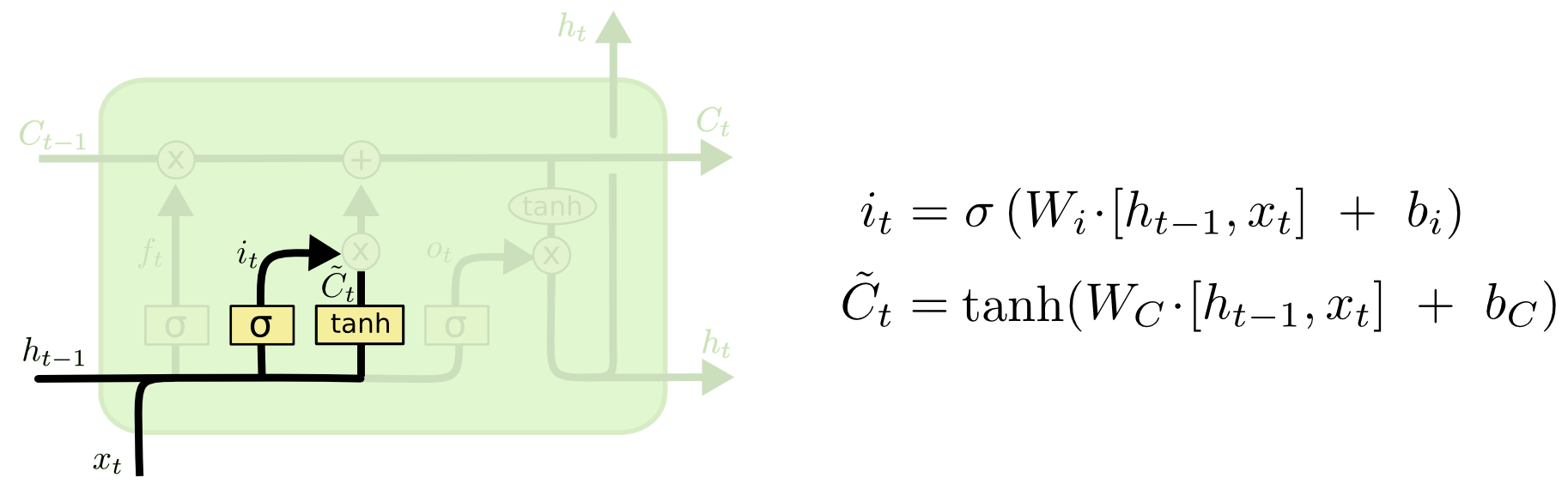
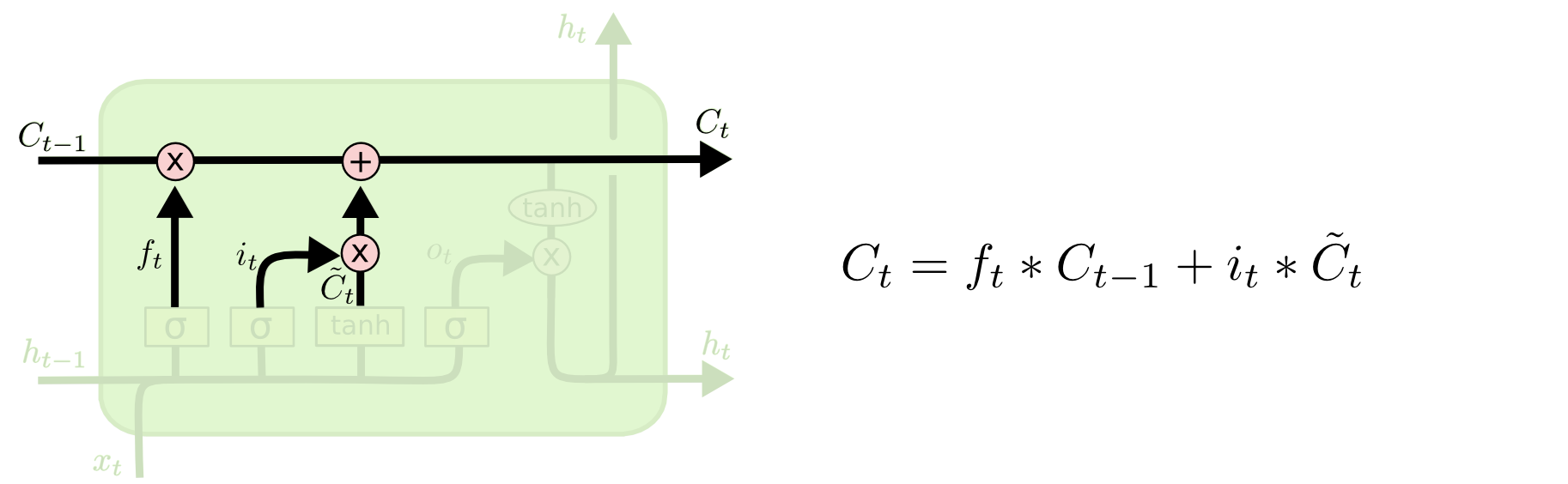
- forget gate는
Ct-1에서 어떤 것을 버릴지를 결정했다면, input gate는Ct-1에서 어떤 정보를 추가해서Ct를 만들지 결정하는 게이트이다. - tanh를 통해 업데이트하고자 하는 값을 -1 ~ 1로 조정하고, 여기에 sigmoid gate로 한번 더 조정한 값이다.
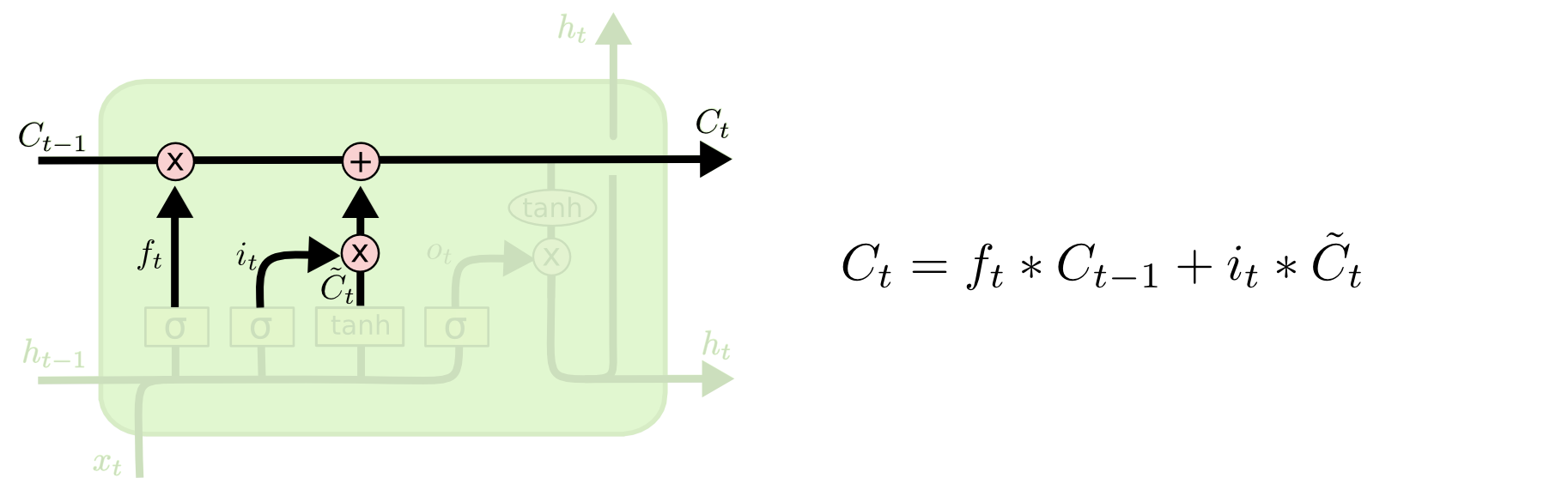
- 최종적으로 next cell state(
Ct)는 각각의 게이트를 통과한 두 cell state를 더하한 것이다.
Output gate and Output
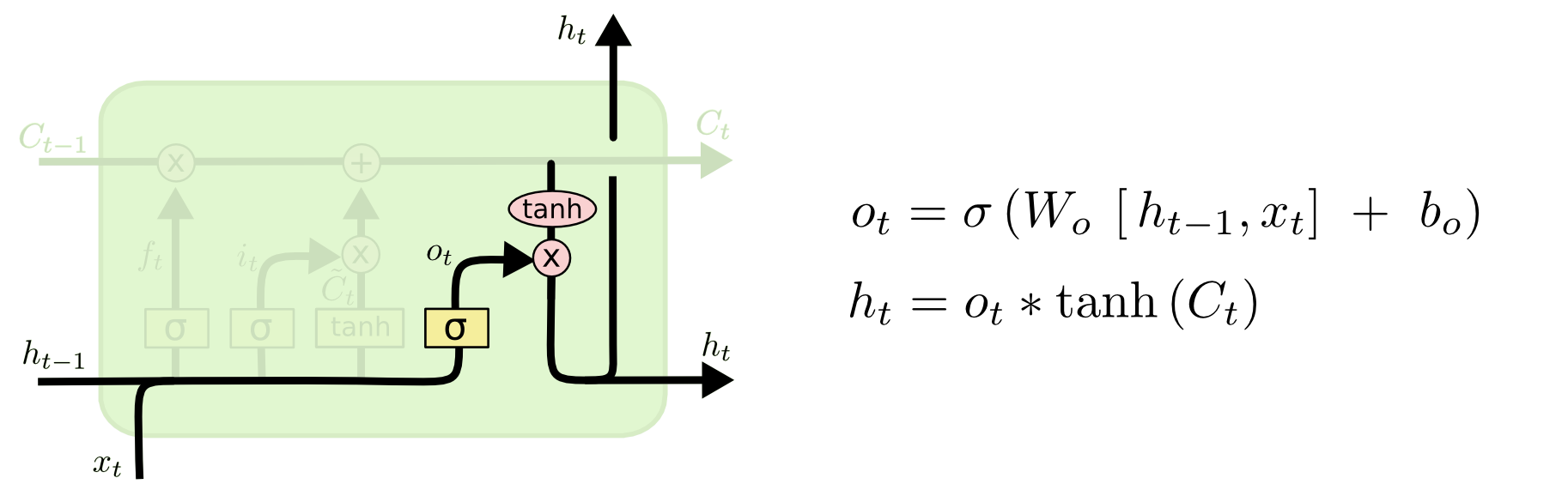
- 새로 업데이트 된 cell state(
Ct)를 바탕으로 output(ht)를 생성한다.
GRU

- 간단하게 다루자면 LSTM에서 gate를 2개로 줄여 network parameter의 수를 줄인 모델이다.
- 앞선 강의에서 말했듯 parameter의 수가 작을수록 일반화 성능이 증가하기 때문에 test data에 대해 LSTM보다 성능이 좋을 떄가 많다.
GRU와 LSTM 차이점
- GRU의 가장 큰 차이점은 cell state가 없다는 것이다.
- hidden state가 곧 output이고, 과거를 summarize하여 다음 state에 전달되는 정보이다.
결론
- RNN은 Sequential date를 다루기 위한 모델이다.
- Vanilla RNN은 lognterm dependency를 다루지 못한다는 단점이 있어 LSTM이 나왔다.
- LSTM에서 parameter를 줄이는 방향으로 일반화성능을 높인 것이 GRU이다.
- 많은 경우 LSTM보다 GRU를 사용할 때 성능이 더 좋다.
- 이후 transformer 구조가 등장하면서 적어도 언어 부분에서는 RNN이 거의 사용되지 않고 있는 추세이다.
