참조 칼럼 : How to Grid Search Hyperparameters for Deep Learning Models in Python with Keras
딥러닝의 하이퍼파라미터 튜닝
- 딥러닝에서도 보다 나은 성능을 내기 위해 사용자가 설정할 수 있는 파라미터가 상당히 많다.
- 가장 최적의 성능을 내는 하이퍼파라미터를 찾기 위한 방법 중 하나가 바로 Grid Search이다.
- 사용자가 범위를 지정하면, 해당 범위로 가능한 조합을 전수조사 하는 방법이다.
- 모든 하이퍼파라미터를 때려넣고 한번에 최적의 조합을 찾을 수 있다면 좋겠지만, 당연히 시간이 오래걸리기 때문에 그렇게 할 수 없다.
- 현재 수준에서 튜닝 해볼 수 있는 파라미터는 다음과 같다.
- 최적화 알고리즘 : Adam, Adadelta, Adagrad, SGD 등
- 알고리즘 하이퍼파라미터 : Learning rate, momentum 등 알고리즘 별 하이퍼파라미터
- Network Initialization : 가중치를 초기화 하는 방법
- 활성 함수 : relu, swish, sigmoid 등
- Dropout_rate : 매 배치 당 제거할 노드의 비율
- 뉴런(노드)의 수 : 히든 레이어의 크기
이 외에 히든 레이어의 수도 있지만, 이는 Grid Search에서 탐색할 방법을 찾지 못했다.
scikeras
- scikeras는 scikit-learn과 keras/Tensorflow를 함께 사용하기 위한 패키지이며, keras 모듈을 scikit-learn 클래스로 래핑하는 형식을 취한다.
- 별도로
scikeras패키지를 설치해야한다.- scikeras.wrappers 모듈에서 분류/회귀 문제별로 래핑 클래스를 가져오면 된다.
try:
import scikeras
except:
!python -m pip install scikeras
from scikeras.wrappers import KerasClassifier, KerasRegressor모델 래핑
- 별도로 keras 모델을 선언하는 함수를 만들어 넣어주면 된다.
- 래핑 시 optimizer, 등 모델 선언시 필요한 인자를 전달할 수 있다.
- 함수에서 사용할 인자를 전달해야할 경우 매개변수명을 명시해서 전달하면 된다.
# 모델 함수
def create_model(nureons=16, activation='swish', dropout_rate=0.0, optimizer='adam'):
keras.backend.clear_session()
# 레이어 연결
il = Input(shape=(8, ))
hl = Dense(nureons, activation=activation)(il)
dl = Dropout(dropout_rate)(hl)
hl = Dense(nureons, activation=activation)(dl)
dl = Dropout(dropout_rate)(hl)
hl = Dense(8, activation=activation)(dl)
dl = Dropout(dropout_rate)(hl)
ol = Dense(1, activation='sigmoid')(dl)
# 모델 선언
model = Model(il, ol)
# 컴파일
model.compile(loss=keras.losses.binary_crossentropy,
metrics=['accuracy'],
optimizer=optimizer)
return model
# Scikeras로 래핑
model = KerasClassifier(model=create_model, verbose=0, epochs=100,
optimizer='Nadam', activation='relu')GridSearchCV
- scikit-learn이 제공하는 그리드 서치 함수이다.
- GridSearchCV에 사용할 모델과 파라미터 범위를 딕셔너리 형태로 전달하여 사용할 수 있다.
- 성능 점수 기준, cv값, n_jobs 등을 설정할 수 있다.
- n_jobs는 탐색시 사용할 스레드의 수를 의미한다. n_jobs=-1을 선언하면 모든 스레드를 사용하는데, 그리드 탐색이 굉장히 오래 걸리는 과정인만큼 -1을 사용하는 것을 권장한다.
자세한 것은 공식문서 참조
from
# 파라미터 설정
nureons = [8, 16, 32, 64, 128]
optimizer = ['SGD', 'RMSprop', 'Adadelta', 'Adam', 'Nadam']
param_grid = dict(
model__nureons = nureons,
model__optimizer = optimizer
)
# GridSearchCV
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=5)학습하기 (피팅)
- 모든 범위 조합을 돌면서 최적의 설정을 찾아낸다.
- grid search의 사용된 모델 역시 최적값일 때의 하이퍼파라미터로 설정된다.
- 컬럼에서는 최적값을 맹신하지 말고, 전체적인 결과를 확인하면서 의사결정을 위해 참고하는 정도로 사용할 것을 권장하고 있다.
# Grid Search
grid_result = grid.fit(x_train, y_train, validation_split=0.2, callbacks=[es])의문점
- 피팅시 validation_split과 callbacks 작동하는지가 의문이다.
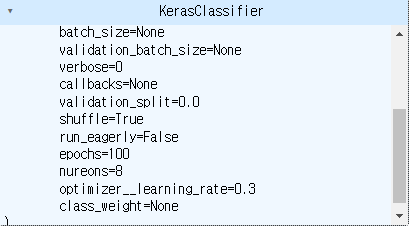
- 학습 후 모델을 확인해보면 validation_split = 0, callbacks=None이 적용되어있다.
- 이게 적용되는 것이 맞는지 계속 찾아보아야겠다.
결과 확인
- grid_result의 여러 속성을 통해 결과를 확인할 수 있다.
best_scores_: 최고성능일 때의 성능 점수best_params_: 최고성능일 때의 하이퍼파라미터 설정값cv_results_: 각 그리드서치 조합의 결과를 딕셔너리 형태로 반환
소감
-
별다른 강의 없이 무작정 실습으로 배운 것인데 다행히 잘 작동되었다.
-
그러나 EarlyStopping이 정상 작동된건지 확인할 방법이 없어 이 부분을 추가로 학습해야할 것 같다.
-
한가지 더 궁금한 것은 어떠한 순서대로 하이퍼파라미터의 최적값을 탐색해야 가장 좋은 모델을 얻을 수 있을까? 이다. optimizer를 먼저 찾아야 할지, 노드의 수를 먼저 찾아야 할지 잘 짐작이 가지 않는다. 이부분에 대한 칼럼 및 동영상을 찾아서 배워보아야겠다.
