참고자료
서론
불균형 데이터
- 불균형 데이터는 클래스 별 관측치가 현저하게 차이가 나는 데이터를 말한다.
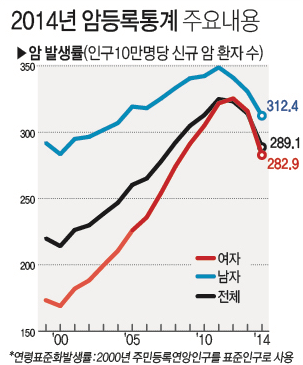
출처 : 연합뉴스
그림은 2014년 인구 10만명당 암 환자수를 나타낸 그래프이다.
위의 경우 암환자를 1, 걸리지 않은 사람을 0으로 했을 때, 데이터가 10만개 있다면 클래스 1의 데이터는 불과 300여개지만, 클래스 0의 데이터는 9만 9700여개인 셈이다.
불균형 데이터의 문제점
어떤 입력값을 받던지 0으로 분류하는 모델이 있다고 하자
이 모델에 암환자 데이터를 준다면 이 모델의 정확도는 99.7%이다.
이 모델이 정확하다고 할 수 있을까?
여기서 등장하는게 recall score 개념이다.
recall은 실제로 1인 데이터를 1로 분류한 비율을 나타내는데, 위의 경우에서 recall score는 0이다.
즉 불균형 데이터에서 아무리 정확도가 높다고 해도, recall이 높지 않다면 성능이 좋지 않은 모델이라 할 수 있다.
머신러닝에서의 문제점
인간이라면 암환자 데이터에서 암에 걸린 사람을 찾는 것이 더 중요하다는 것을 알 수 있다. 그러나 머신러닝에서는 어떤 데이터가 중요한지 구분하지 않는다.(따로 가중치를 주지 않으면)
때문에 다수 클래스에 훨씬 쏠려서 학습을 하게 되고, 적절한 분류 경계선을 형성하지 못해 소수 클래스에 대한 recall이 매우 낮게 측정되는 현상이 발생한다.
해결 방안
크게 데이터를 조정해서 해결하는 방안과, 모델을 조정해서 해결하는 방안이 있다.
여기서는 데이터를 조정해서 해결하는 언더샘플링, 오버샘플링에 대해 알아보자.
샘플링 기법
언더 샘플링
- 다수 클래스의 데이터를 제거하는 방법으로, 소수 클래스와의 비율을 맞추는 기법이다.
1. Random undersampling
- 무작위로 다수 범주 데이터를 선택하여 제거하는 방법이다.
- 매 샘플링마다 결과가 다르고, 편향이 발생할 수 있다.
- 안좋아보이지만 실제로는 대부분 랜덤으로도 샘플링 효과가 잘 나타난다.
2. Tomek links
- 다수 클래스와 소수 클래스 사이의
Tomek link를 연결하여, 연결된 다수 범주를 모두 제거하는 기법이다.
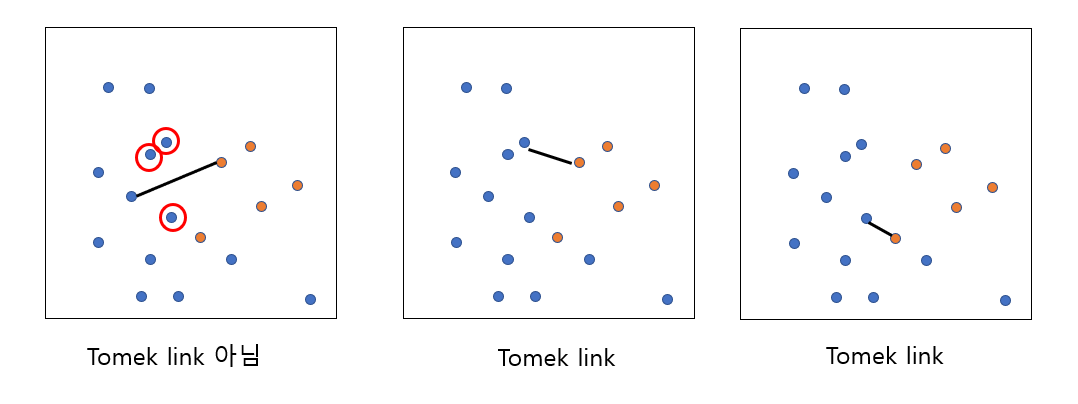
-
Tomek link란 다수 클래스와 소수 클래스를 연결했을 때, 중간에 다른 데이터가 없는 연결선을 의미한다.
-
소수 클래스 근처의 다수 클래스를 제거함으로써, 분류 경계선을 명확히 하는 기법이다.
3. CNN (Condensed Nearest Neighbor)
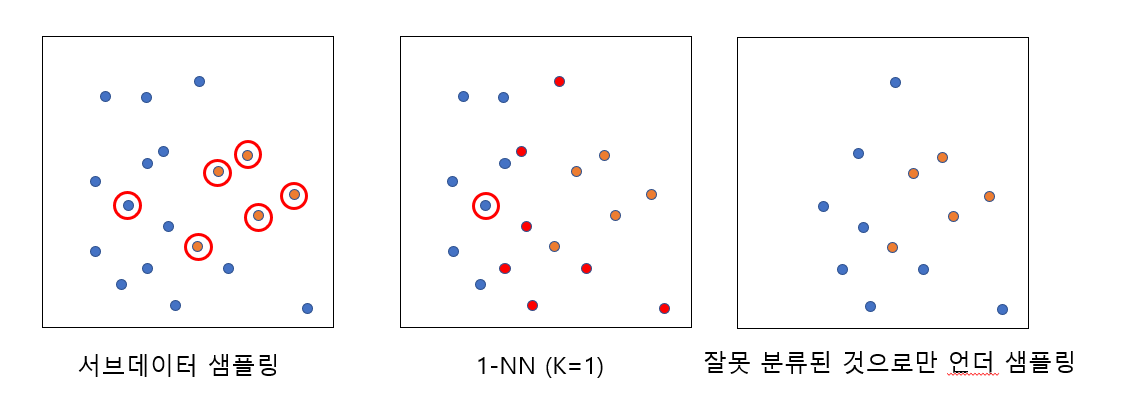
- 소수 클래스 전체와 다수 클래스 중 무작위로 선택된 하나를 샘플링하여 서브데이터를 구성한다.
- 서브데이터를 학습 데이터로 하여, 나머지 원 데이터에 1-NN 알고리즘(K=1인 KNN알고리즘)을 통해 분류하도록 한다.
- 예측값과 실제값을 비교해 잘못 분류된 다수 범주 데이터만을 남기고, 나머지는 모두 제거한다.
- 머신 러닝 예측을 다수 클래스쪽으로 쏠리게하는 데이터를 모두 제거함으로써 분류 성능을 높이는 기법이다.
4. OSS (One-Side Selection)
- Tomek link와 CNN을 동시에 적용하는 기법
- 소수 클래스 근처와, 소수 클래스에서 아예 멀리 떨어진 다수 클래스 데이터를 모두 제거함으로써, 균형있는 데이터를 확충한다.
언더샘플링의 장단점
- 장점 : 전체 데이터 제거로 학습 시간을 줄일 수 있다.
- 단점 : 데이터 제거로 인한 정보의 손실이 발생한다.
오버 샘플링
- 소수 클래스의 데이터를 늘리는 방향으로, 다수 클래스와의 비율을 맞추는 기법이다.
1. Resampling
- 소수 클래스의 데이터를 그대로 복제하여 데이터 수를 늘리는 방법
- 매 복제마다 무작위로 선택하여 복제하기 때문에, 어떤 소수 클래스는 적게 복제되고, 어떤 것은 많이 복제 될 수 있다.
- 소수 클래스에 대한 과적합이 발생할 수 있다는 문제점이 있다.
2. SMOTE (Synthetic Minority Oversampling Technique)
- 기존 소수 클래스의 주변에 가상 데이터를 생성하여 채우는 기법
- KNN 알고리즘을 기반으로 한다.
- 소수 클래스 중 하나를 무작위로 선택
- 해당 클래스에서 K개의 소수 클래스 이웃을 찾고, 이중 하나를 무작위 선택
- 선택된 두 클래스 사이에서 가상 데이터를 생성
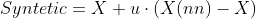
- 생성식은 위와 같은데 쉽게 말하면 두 데이터를 연결하는 직선 사이에 균등 분포를 따라 데이터가 하나 생성되는 것이다.
- 주의사항 : K=1 일 경우 무조건 서로 가까운 값 사이에만 관측치가 생성되므로 과적합이 발생할 수 있다.
3. Borderline-SMOTE
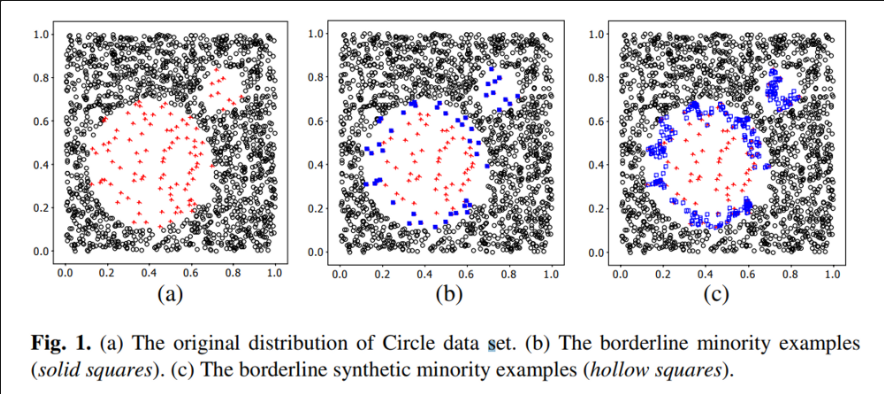
출처 : Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning
- 다수 클래스와 가까운 경계에 존재하는 소수 클래스만 선택하여 SMOTE를 진행하는 기법
- KNN 알고리즘을 바탕으로 소수 클래스 데이터를 크게 3가지 종류로 구분한다.
- 이웃 중 다수 클래스가 과반수일 경우 -> Danger
- 이웃 중 소수 클래스가 다수 클래스보다 많거나 같을 경우 -> Borderline
- 이웃 모두가 다수 클래스일 경우 -> Noise
- 이중 Borderline으로 분류된 데이터에 대해서만 SMOTE를 적용하여 가상 데이터를 생성한다.
4. ADASYN (Adaptive Synthetic Sampling Approaach)
- 다수 클래스와의 거리에 따라 오버샘플링 하는 개수를 다르게 하는 기법이다.
- 모든 소수 클래스에 대해 KNN 알고리즘을 적용하여 이웃을 탐색한다.
- 발견된 다수 클래스 이웃이 n개일 때 r 값을 구한다.
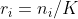
- 여기서 r은 이웃이 모두 소수클래스이면 0, 모두 다수클래스이면 1이다.
- 계산한 r값의 합계가 1이 되도록 스케일링한다.
- 오버샘플링 할 값을 G로 정의하고, 각 r값에 G을 곱한만큼 가상 데이터를 생성한다. 일반적으로
G = 다수클래스 수 - 소수클래스 수이다. - 생성할 개수 만큼 SMOTE를 적용하여 가상 데이터를 생성한다.
- 다수 클래스가 여러개의 분포를 가진 multi modal 데이터 형태에서 우수한 성능을 보인다.
장단점
- 장점
- 정보 손실이 없음
- 언더 샘플링에 비해 높은 분류 정확도
- 단점
- 과적합 가능성이 증가
- 학습 시간이 증가
- 노이즈나 이상치에 민감
