간만에 쓰는 첫 글은 인공지능을 처음 다뤄본 후기이다.
SAMPNet
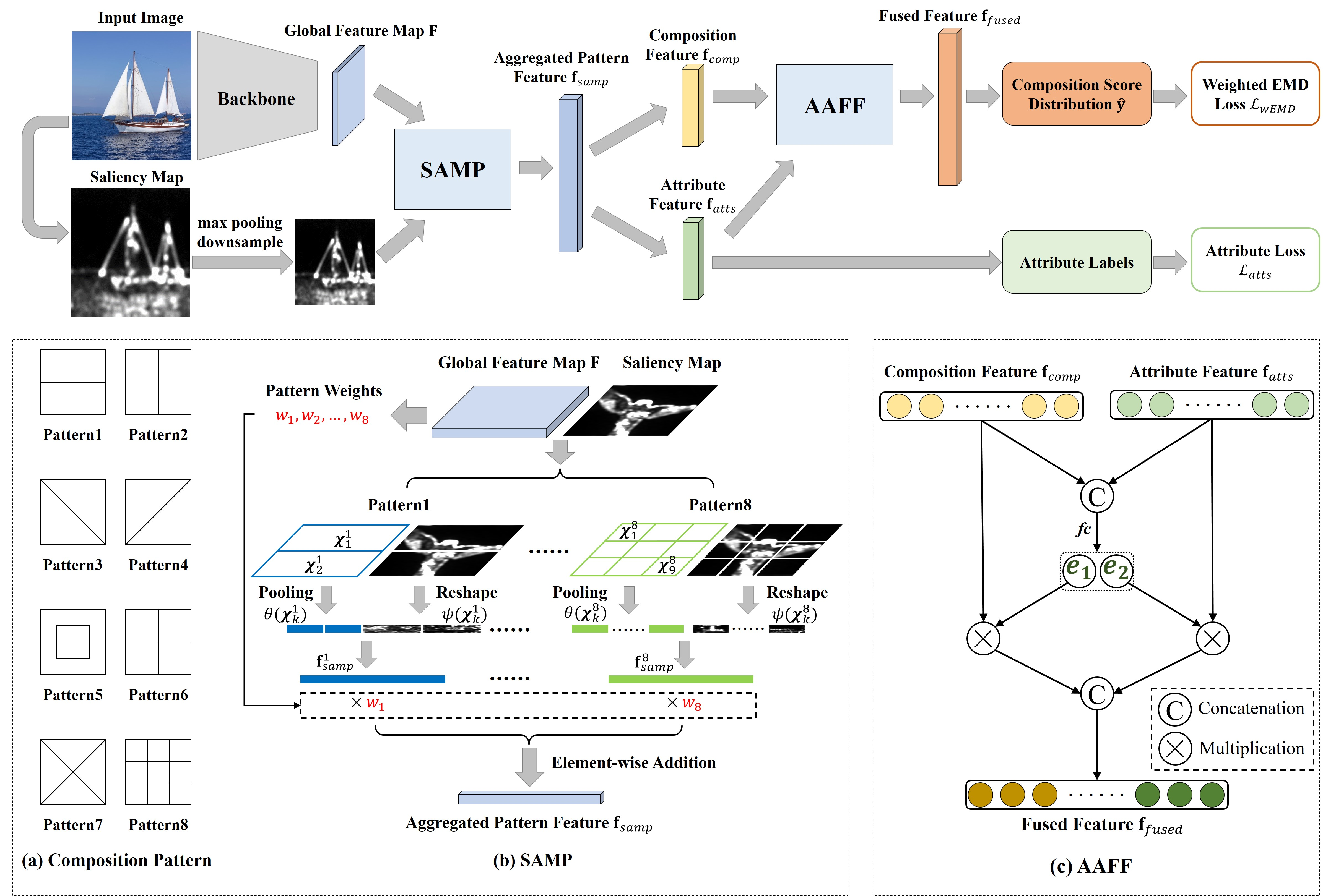
SAMPNet은 이미지 구도 평가를 위한 신경망이다.
출처: https://github.com/bcmi/Image-Composition-Assessment-Dataset-CADB
이미지를 넣으면 Saliency Map이라는 특징 맵을 추출하고, 원본 이미지와 특징 맵을 같이 넣어 신경망에 넣으면 특징 벡터가 나온다. 이 벡터는 composition feature와 attribute feature에 대한 가중치 리스트인데, 이것을 AAFF라는 모듈을 거치면 각 리스트에 대한 가중치를 합쳐 새로운 벡터가 나오고, 이 벡터를 기반으로 이미지 구도 평가 점수를 예측한다.
아직 완벽히 이해하진 못했지만 그래도 어떤 식으로 돌아가는지 정도는 알고 있는 것 같다.
문제는 코드였는데, pytorch에 대한 지식이 전무하다보니 코드를 이해하는데 어려움이 있었다. 기존 github를 fork하여 나만의 추론 코드를 만들어보았다.
def inference(model, cfg):
model.eval()
device = next(model.parameters()).device
testdataset = InferenceDataset(cfg)
testloader = DataLoader(testdataset,
batch_size=cfg.batch_size,
shuffle=False,
num_workers=cfg.num_workers,
drop_last=False)
print()
print('Inference begining...')
with torch.no_grad():
for (image_name, im, saliency) in tqdm(testloader):
image = im.to(device)
saliency = saliency.to(device)
weight, atts, output = model(image, saliency)
pred_score = round(dist2ave(output).item(), 2)
print(image_name[0])
print("pred_score:", pred_score)
print_pattern_weight(tensor_normalize(weight).tolist()[0])
print()
print_attribute_weight(tensor_normalize(atts).tolist()[0])
print()
print('Inference result...')
return weight, atts, pred_score
if __name__ == '__main__':
cfg = Config()
device = torch.device('cuda:{}'.format(cfg.gpu_id))
model = SAMPNet(cfg,pretrained=False).to(device)
weight_file = './pretrained_model/samp_net.pth'
model.load_state_dict(torch.load(weight_file, map_location='cuda:0'))
inference(model, cfg)가장 중요한 추론 함수와 main을 가져왔다.
if __name__ == '__main__':
cfg = Config()
device = torch.device('cuda:{}'.format(cfg.gpu_id))
model = SAMPNet(cfg,pretrained=False).to(device)
weight_file = './pretrained_model/samp_net.pth'
model.load_state_dict(torch.load(weight_file, map_location='cuda:0'))
inference(model, cfg)먼저 main이다. Config.py라는 파일이 import 되어 있기 때문에, Config 인스턴스를 생성했다. Config.py에는 이미지 경로나 배치 사이즈 등의 여러 설정값들이 들어가 있다. 다음으로 device를 할당하고, SAMPNet 모델을 가져와서 그 디바이스가 처리하도록 넘긴다. weight_file은 학습된 모델이고, 이 모델을 적용하여 추론을 시작한다.
model.eval()
device = next(model.parameters()).device
testdataset = InferenceDataset(cfg)
testloader = DataLoader(testdataset,
batch_size=cfg.batch_size,
shuffle=False,
num_workers=cfg.num_workers,
drop_last=False)model.eval()은 신경망을 거치는 과정에서 학습에 사용되는 신경망 계층을 제외하도록 설정하는 메소드이다. testdataset으로 내가 구성한 InferenceDataset으로 설정했다. 기존 dataset과 다른 점은 추론 과정이기 때문에 라벨링된 점수나 attribute 가중치들이 없다는 것이다.
with torch.no_grad():
for (image_name, im, saliency) in tqdm(testloader):
image = im.to(device)
saliency = saliency.to(device)
weight, atts, output = model(image, saliency)testloader에서 데이터들을 불러오는데, 추론 과정이기 때문에 이미지 이름과 이미지 파일, 그리고 saliency map만을 가져온다. 이 값을 가지고 model을 돌려 weight(패턴 가중치), atts(attribute 가중치), output(패턴 가중치와 attribute 가중치가 AAFF를 거친 것, 후에 점수의 기반이 됨)을 받아낸다.
pred_score = round(dist2ave(output).item(), 2)
print(image_name[0])
print("pred_score:", pred_score)
print_pattern_weight(tensor_normalize(weight).tolist()[0])
print()
print_attribute_weight(tensor_normalize(atts).tolist()[0])
print()
print('Inference result...')
return weight, atts, pred_score이후 output에서 예측 점수를 뽑아내면 추론은 끝이다.
후기
처음 돌려본 인공지능이라서 재밌는 경험이었고, 한편으론 코드가 익숙치 않아 이해하는데 애를 많이 먹었다. 예를 들면, testloader에서 데이터를 가져올 때, 자동으로 dataset의 getitem 메소드를 호출한다는 것 등이 있다. 그래도 의미있는 경험이었고, 밑바닥부터 시작하는 딥러닝1을 읽으면서 이론적인 내용을 공부하였지만 그 책의 내용은 정말 기본적인 것들로만 구성되어 있다는 것을 깨달았다. 이번 일을 계기로 이전에는 관심없던 인공지능에 대해 더 열심히 알아보고, 많이 경험해보고 싶다.
