오늘은 두 번째 인공지능이다.
구글 리서치에서 발표한 Camera View Adjustment Prediction for Improving Image Composition이라는 제목의 논문이다.
논문 주소: https://arxiv.org/pdf/2104.07608.pdf
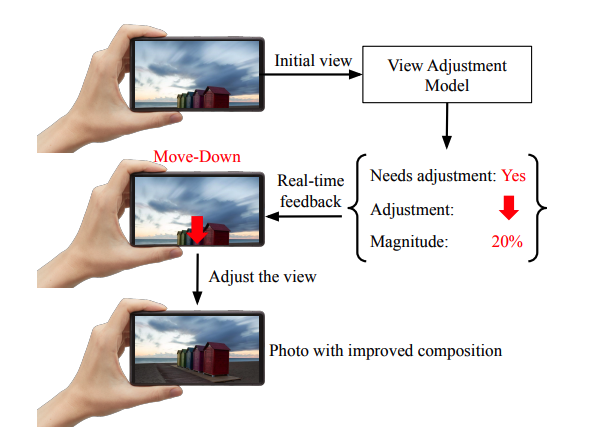
간단 요약하자면, 구도 개선을 위해 사용자가 카메라로 어떤 행동을 취해야할 지 알려주는 인공지능 모델에 관한 논문이다.
2회차에 걸쳐서 볼 건데, 1회차는 Composition Scoring Model을, 2회차는 View Adjustment Predictioni Model을 설명할 것이다.
문제 해결
해결하려는 문제는 다음 3가지이다.
1. 현재 이미지에서 구도 개선 방안이 존재하는지
2. 존재한다면 어떻게 해야 하는지
3. 그 행동을 얼마만큼 해야 하는지
모델 소개
Composition Scoring Model
- 이미지를 input으로 주었을 때, 구도적인 점수를 [0, 1]의 output으로 내는 모델
- loss는 pairwise ranking loss를 사용.(I(n)이 점수가 낮은 이미지, I(p)가 점수가 높은 이미지)
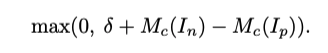
- 학습 과정은 다음과 같음
-
점수가 매겨진 크롭들이 여러 개 있는 데이터셋으로 페어를 만들어 높고 낮음을 따짐.
1-1. 학습 한 번에 1개의 이미지에 대해서 N개(논문에서는 16)의 크롭을 뽑아서 N(N-1)/2개의 pairs를 만듦. 그리고 이 pairs에 대한 loss를 구한 후, 평균을 내어 L(sc)를 산출
1-2. 데이터셋으로는 CPC(점수가 있는 크롭 이미지가 24개)와 GAICD(점수가 있는 크롭 이미지가 90개) 사용 -
이미지의 베스트 크롭이 있는 데이터셋으로 페어를 만듦
2-1. 베스트 크롭에 적절한 변형(perturbation)을 가해서 구도적으로 좋지 않은 이미지를 만듦. 이때 이 변형은 원본 이미지를 벗어나서는 안 됨.
2-2. 학습 한 번에 K(논문에서는 16)개의 이미지에서 K개의 pairs를 만듦. 그리고 이 pairs에 대한 loss를 구한 후, 평균을 내어 L(bc)를 산출
2-3. 데이터셋으로는 FCDB(이미지마다 베스트 크롭이 존재)와 GAICD(점수가 있는 크롭 이미지가 90개 있는데, 가장 높은 점수의 크롭을 베스트 크롭으로 선정) 사용 -
unlabeled data를 사용하여 페어를 만듦
3-1. unlabeled data에 2-1에서 가한 변형을 그대로 가해서 구도적으로 좋지 않은 이미지를 만듦. 이때 이 변형은 원본 이미지를 벗어날 수도 있는데, 이 부분을 0 픽셀로 채움
3-2. 학습 한 번에 P(논문에서는 16)개의 이미지에서 P개의 pairs를 만듦. 그리고 이 pairs에 대한 loss를 구한 후, 평균을 내어 L(wc)를 산출
3-3. 구도적으로 좋은 데이터를 unlabeled data로 삼아야 하기 때문에, 전문 사진가가 찍은 잘 찍은 사진들이 모여있는 Unsplash라는 사진 공유 사이트에서 데이터를 수집함 -
data augmentation
4-1. unlabeled data의 변형에 0 픽셀이 들어가다보니 모델이 0 픽셀이 있다 없다로 학습해버릴 수도 있음. 이를 방지하기 위해 unlabeled data에 augmentation을 가해서 0픽셀이 들어간 이미지도 좋은 이미지로 인식할 수 있도록 함.
4-2. labeled data에 대해서도 pair의 각 이미지에 대해 동일한 augmentation 방식을 적용하여 데이터 수를 늘림 -
총 Loss = L(sc) + L(bc) + L(wc)로 하여 학습함
변형은 다음의 종류가 있다.
1. shift: 이미지를 상/하/좌/우로 조금씩 움직이는 것
2. zoom-out: 줌 아웃 하는 것
3. cropping: zoom-in과 shift가 결합된 형태로, 이미지의 크롭을 따내는 것
4. rotation: 이미지를 특정 각도로 회전시키는 것
augmentation은 다음의 종류가 있다.
1. shift borders: 상 or 하 와 좌 or 우의 일정 부분을 0픽셀로 채움
2. zoom-out borders: 상하좌우 모두 일정 부분을 0픽셀로 채움
3. rotation borders: 이미지를 특정 각도로 돌렸다가 다시 반대로 돌림. 수학적으로는 다시 원본 이미지로 돌아오지만, 이미지에서 봤을 때는 돌렸을 때 잘리는 부분이 있기 때문에 다시 반대로 돌리면 잘린 부분은 0픽셀로 남게 되어 augmentation 효과가 있음
모델 구현

꽤 상세하게 설명되어 있다.
backbone으로는 MobileNet을 사용. input size는 MobileNet의 input과는 다르게 299x299를 사용한다. 마지막 레이어와 아웃풋 레이어는 위와 같이 구성한다.
모델의 목적
이 모델은 2회차에 나올 View Adjustment Prediction Model의 학습 데이터를 생성하기 위해 만들어졌다. 이 평가 모듈을 통해 원본 이미지에 대하여 원본의 점수와 변형된 이미지들 간의 점수를 비교하여 가장 높은 점수의 이미지로 가이드해주도록 하기 위해 이 모델을 사용한다.
마무리
오늘은 Composing Scoring Model에 대해 알아보았다. 역시 논문은 어렵고, 이해하기가 힘든 것 같다. 그래도 재미있는 논문이었고, 특히 변형과 augmentation에 관한 부분이 재밌었다. 논문의 supplementary에 보면 얼마나 변형했는지, augmentation도 어떻게 했는지 디테일이 나와 있기 때문에 더 흥미롭게 읽을 수 있었다. 다음 글은 View Adjustment Prediction Model로 쓸 것이다.

잘 봤습니다. 좋은 글 감사합니다.