
오늘은 지난번에 이어 Camera View Adjustment Prediction for Improving Image Composition 논문의 두 번째 리뷰이다. 오늘은 본 모델인 View Adjustment Prediction Network에 대해 중점적으로 다룬다.
모델 소개

모델의 아웃풋은 위에서 볼 수 있듯이 3개이다.
suggestion predictor
- 구도 조정을 해야하는지 하지 말아야 하는지 알려주는 output
- binary classification 문제이고, cross-entropy loss를 사용
adjustment predictor
- 어떤 구도를 적용해야 하는지 알려주는 output
- multi-class classfication 문제이고, categorical cross-entropy loss를 사용
magnitude predictor
- adjustment predictor에서 나온 구도를 얼마나 적용해야 하는지 알려주는 output
- regressor 문제이고, L1 loss를 사용
학습 과정
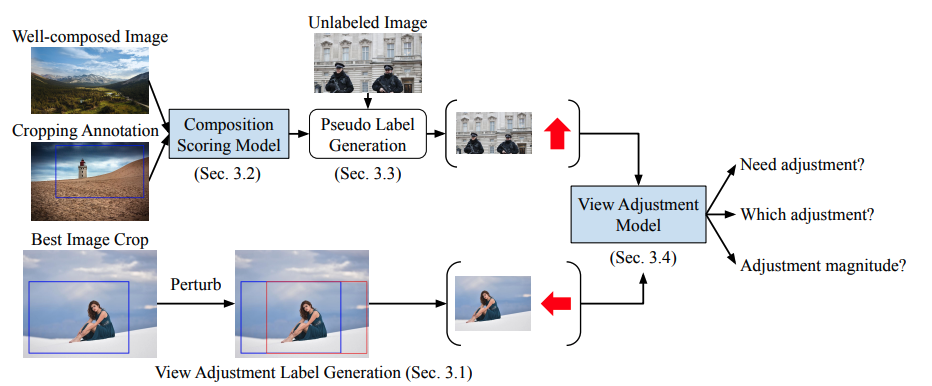
데이터셋
- Labeled dataset으로 best crop dataset을 사용
- Unlabeled dataset으로 Open images를 사용
학습 프로세스
-
Labeled dataset의 best crop을 원본 이미지 안에서 변형시킴
-
변형된 이미지를 input image, 변형의 역과정을 ground truth label로 사용
2-1. 만약 best crop을 오른쪽으로 20% shift 했다면, 왼쪽으로 20% shift하는 것을 ground truth adjustment/magnitude label로 사용 -
Unlabeled dataset의 원본 이미지를 변형시킴(원본 이미지 벗어나는 부분은 0픽셀로 채움)
-
Unlabeled image를 8가지 구도 가이드(left shift, right shift, up shift, down shift, zoom-in, zoom-out, clockwise rotation, counter-clockwise rotation)로 9가지 magnitude로 변형시키고, 각각의 변형 이미지(72개)를 Composition Scoring Network로 평가함. 원본 이미지도 평가함
-
변형된 이미지 중 가장 높은 점수와 원본 이미지 점수 차이가 특정 margin(논문에서는 0.2) 이상 차이 나면 그것을 label로 사용. 아니라면 suggestion이 0인 레이블로 사용
5-1. 만약 15% up shift가 가장 큰 점수를 가졌고, 원본 이미지 점수와 0.3점 차이난다면 원본 이미지를 input image로, 15% up shift하는 것을 ground truth adjustment/magnitude label로 사용 -
만약 ground truth suggesiton이 0이라면 suggestion predictor만 back propagation하고, 1이라면 adjustment predictor와 magnitude predictor를 back propagation함.
테스트 프로세스
- best crop 데이터셋의 test split을 사용.
- 각각의 best crop을 변형시킨 이미지(원본 이미지 안에 있어야함)를 input image로, 변형의 역과정을 ground truth label로 사용
평가 지표
- AUC(Area Under receiver operating characteristics curve)
- suggestion predictor를 평가하기 위한 지표 - TPR(True Positive Rate)
- suggestion predictor를 평가하기 위한 지표 - F1-score
- suggestino predictor와 adjustment predictor를 평가하기 위한 요소 - IoU(Intersection over Union)
- 종합적으로 평가. 예측된 bounding box와 ground truth bounding box 간의 IoU 계산
평가 결과

그다지 높지 않지만 Task가 어려워서 저 정도도 준수한 수준이라고 한다.
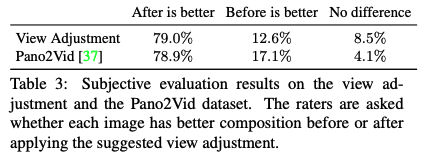
Subjective Evaluation이다.
마무리
오늘은 구도 가이드 모델에 관해 알아보았다. 정확도가 수치상으로는 그리 높진 않지만, Task 자체도 고려하면 나쁘지 않은 수준이라고 하니 괜찮게 학습되고 구성된 모델인 것 같다. 코드가 없다는 점이 아쉽지만 재밌는 논문이었고, 가이드 모델의 학습 데이터셋을 만들기 위해 평가 모델을 개발하고 학습시키는 점이 인상깊었다.

글 재미있게 봤습니다.