오늘은 Deep Residual Learning for Image Recognition (ResNet)에 대한 간단한 리뷰이다.
Deep Residual Learning
Residual Learning
모델이 찾아내야 하는 함수가 H(x)라고 할 때, H(x)를 위와 같이 정의하였다. 이렇게 정의함으로써 만약 모델이 찾아내야 하는 함수가 identity mapping이라면 F(x)가 0이 되게 학습이 쉽게 되기 때문에, identity mapping을 찾지 못해 에러가 커졌던 기존 방식의 문제를 해결할 수 있다.
Identity Mapping By Shortcuts
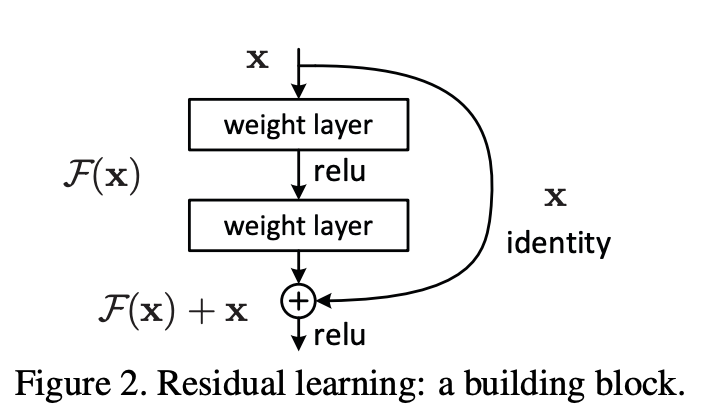
위와 같은 shortcut connection은 추가적인 파라미터가 없고, 계산이 간단하다는 점에서 이점을 가진다.
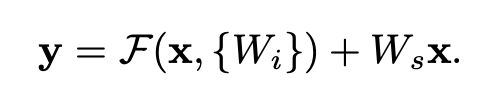
x와 F 아웃풋의 차원이 다른 경우, x에 따로 W 행렬을 곱해줌으로써 차원을 맞춰주면 된다.
또한 F 함수의 레이어 개수는 상관이 없지만, 하나만 쓸 경우 Linear와 다를 바 없기 때문에 이점을 발견하지 못했다고 한다.
Network Architectures
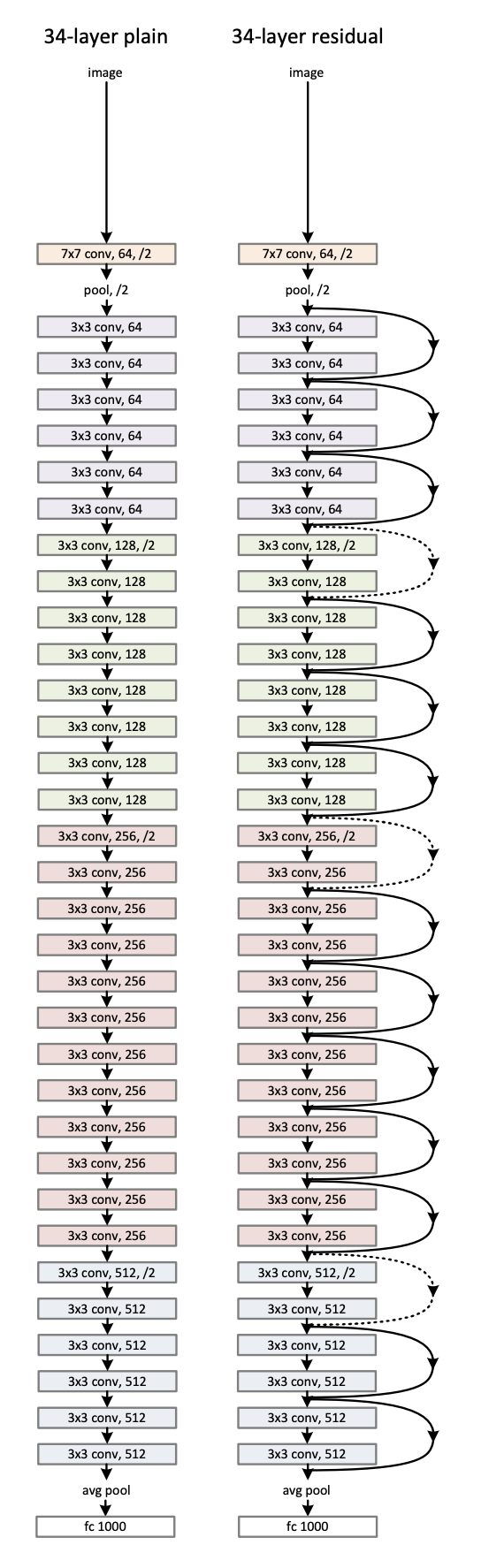
위의 두 개의 아키텍처를 비교하였다.
Experiments
ImageNet Classification
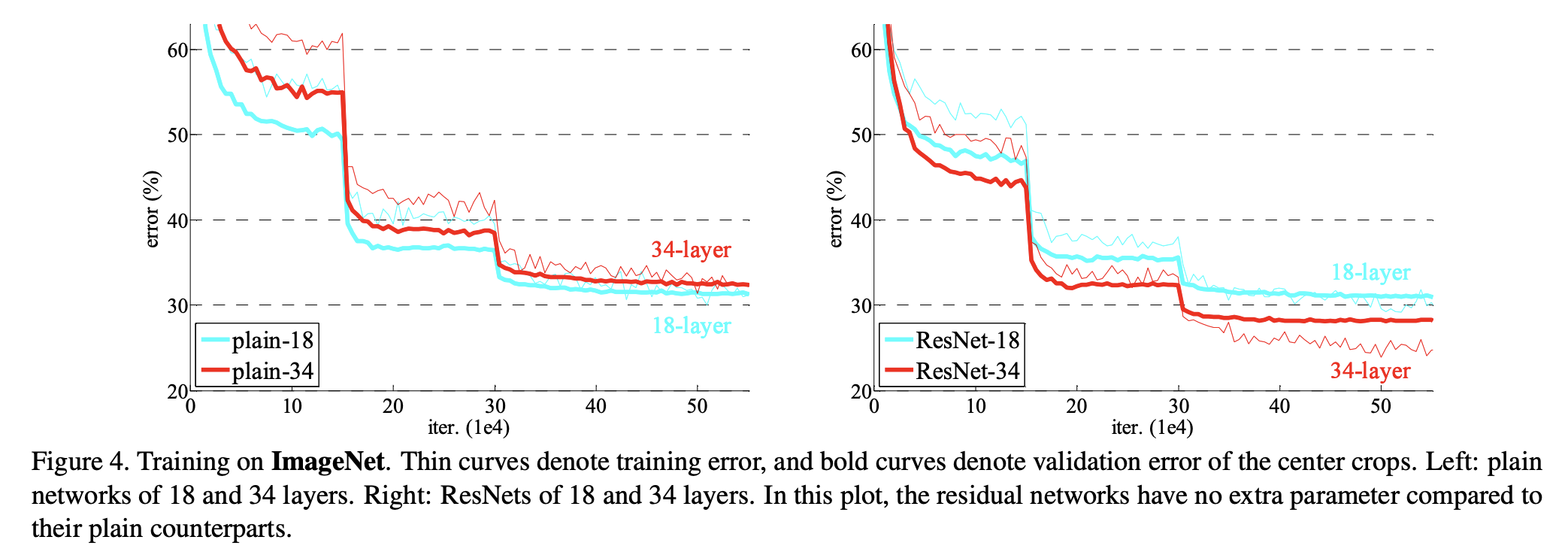
그래프를 보면 알 수 있듯, plian은 깊이가 깊은 것이 error가 더 높은 반면, ResNet은 깊이가 깊은 것이 error가 더 낮고, plain보다 더 빨리 수렴하는 것을 확인할 수 있다.
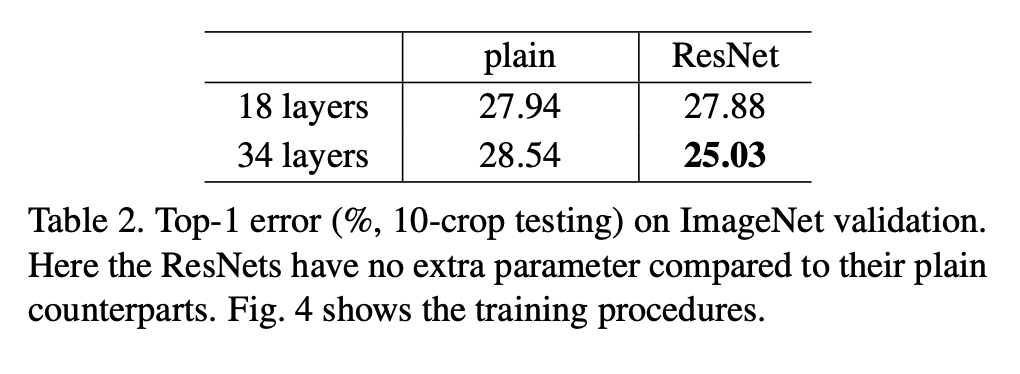
plain과 ResNet은 파라미터 개수 차이가 없음에도 불구하고, validation에서 ResNet이 더 좋은 성능을 보여주었다.
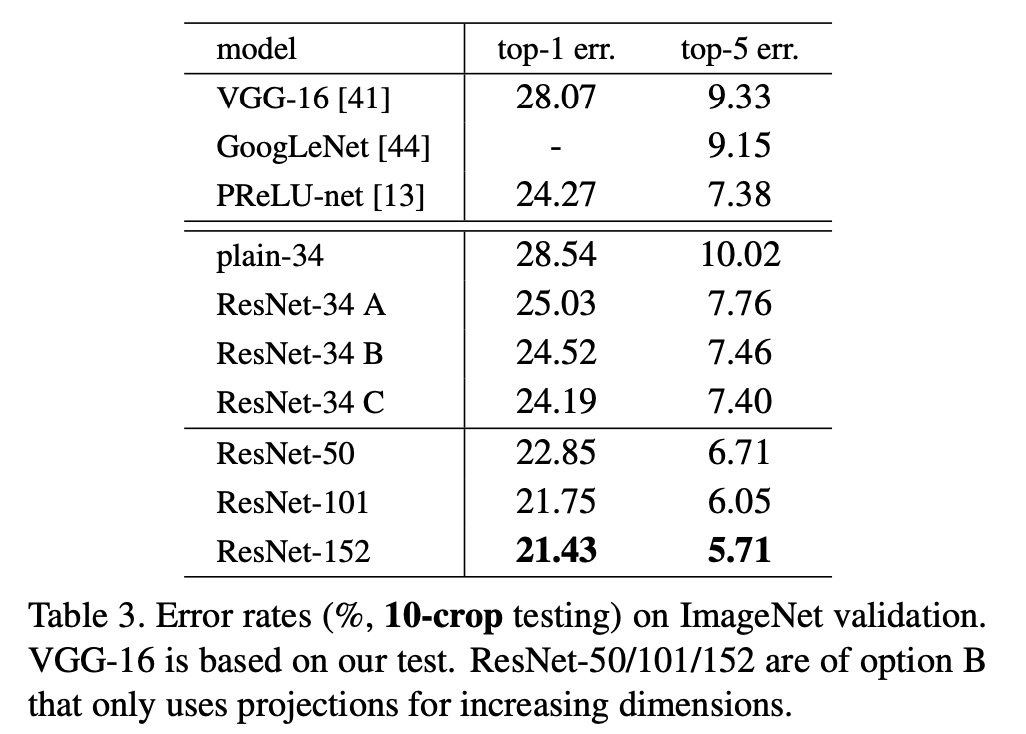
ResNet-34에서 A는 zero padding을 통하여, B는 차원 늘이는 것만 projection을 통하여, C는 모든 것을 projection을 통해 처리하였다.
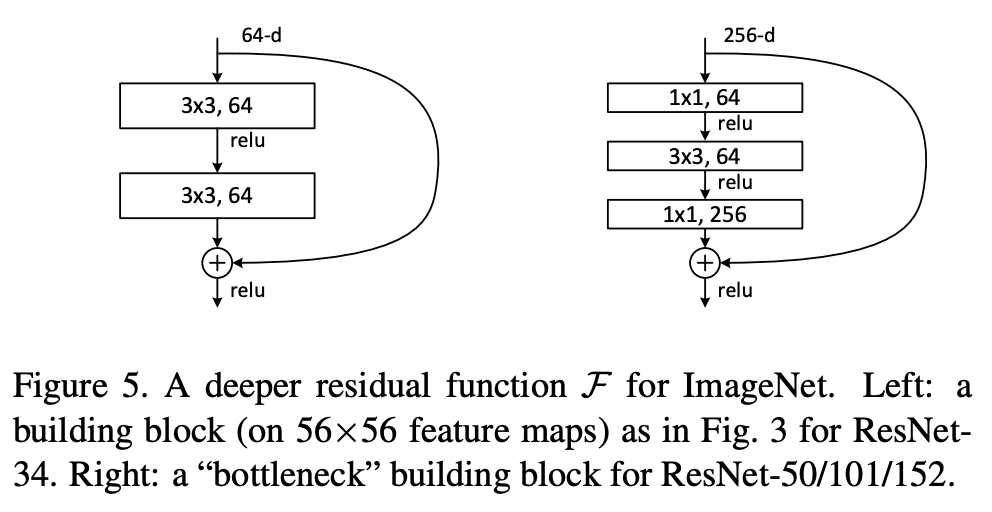
또한 오른쪽과 같은 bottleneck building block을 구성하여 ResNet에 적용하였다.
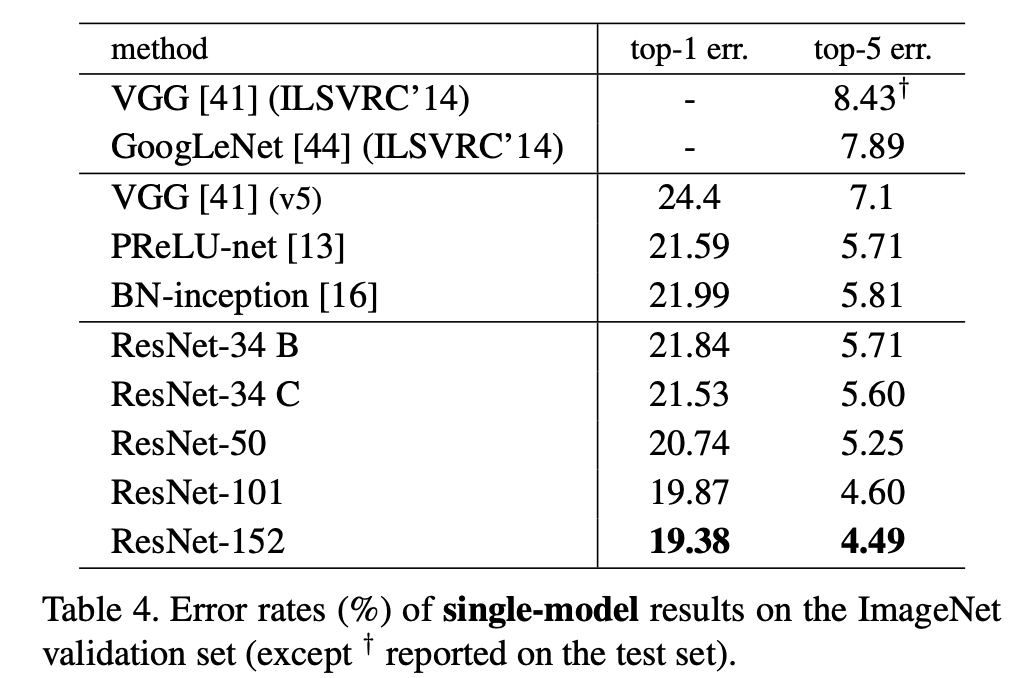
그 결과 층이 깊어질수록 정확도가 증가하는 효과를 확인할 수 있었다.
CIFAR-10 and Analysis
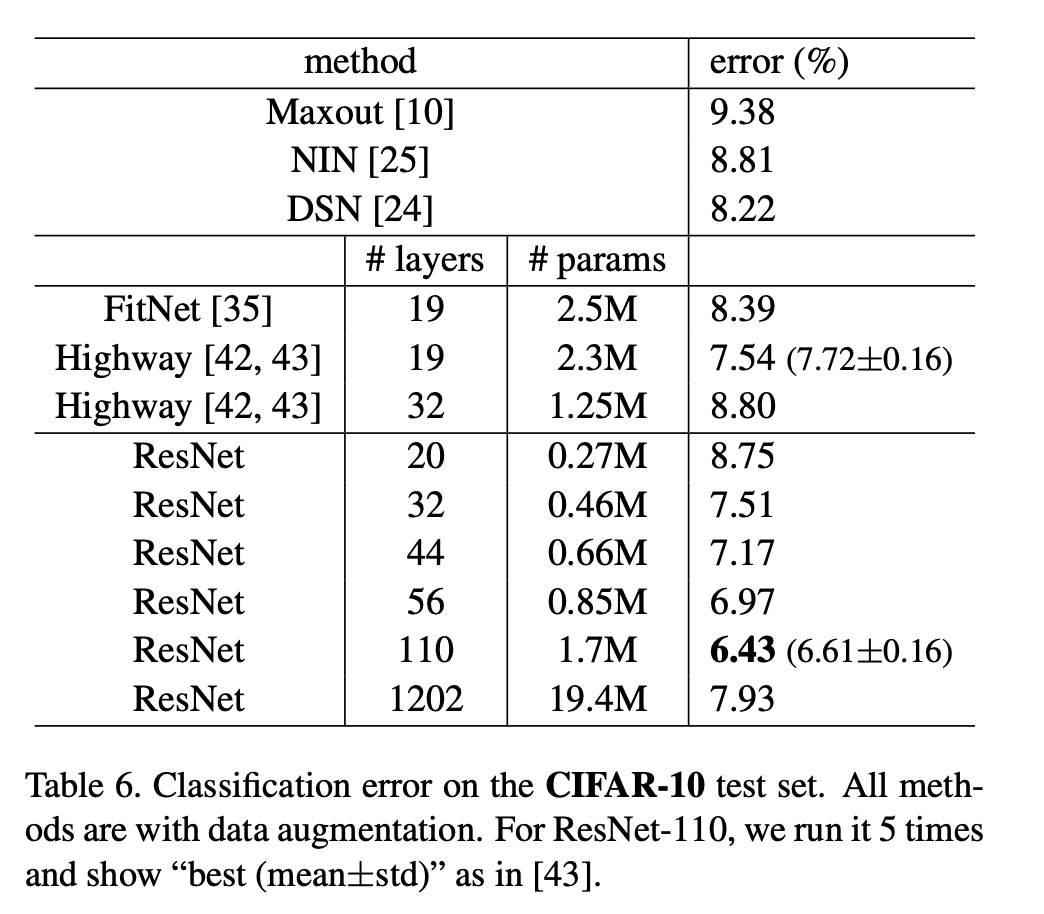
또다른 image classification dataset인 CIFAR-10에 대해서도 같은 방법론을 적용하여 보았다고 한다. 재밌는 것은 ResNet-110과 ResNet-1202가 비슷한 train error를 달성했는데도 성능은 ResNet-1202가 test error는 더 높다는 것이다. 저자는 이것이 오버피팅 때문일 것이라고 생각하는데, 그 이유는 이 실험을 할 때 모델의 일반화 능력을 증가시키는 dropout같은 방법론을 적용하지 않았기 때문이다. 따라서 적은 데이터셋으로 매우 깊은 모델을 학습시키려고 하다보니 오버피팅이 발생한 것 같다고 한다.
나머지
Object Detection task에서도 괜찮은 일반화 성능을 가져왔다고 한다.
후기
3월 7일 기준 인용수가 20만회에 달하는 ResNet 논문이다. 그것때문인지는 모르겠지만 논문이 매우 재밌었고, 1202개의 층을 쌓은 것을 보고 '이것이 진짜 광기구나' 라는 생각을 했다. 매우 간단한 테크닉인 identity mapping이 성능 향상을 가져오고, residual network가 요즘의 모델에서도 많이 쓰이는 것을 보면 어쩌면 복잡한 것만이 답은 아니라는 생각이 든다. 때로는 단순하고 근본적인 방식이 새로운 결과를 낳는 것 같다.
