오늘은 Densely Connected Convolutional Networks (DenseNet)에 대한 간단한 리뷰이다.
DenseNets
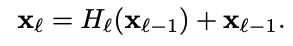
ResNet의 경우 residual network가 위와 같은 구조를 가지고 있다. 따라서 역전파를 할 때 gradient를 이전 레이어로 효과적으로 전달할 수 있었는데, summation으로 이루어져 있기 때문에, information flow가 지연될 수도 있다.
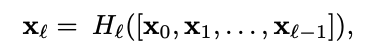
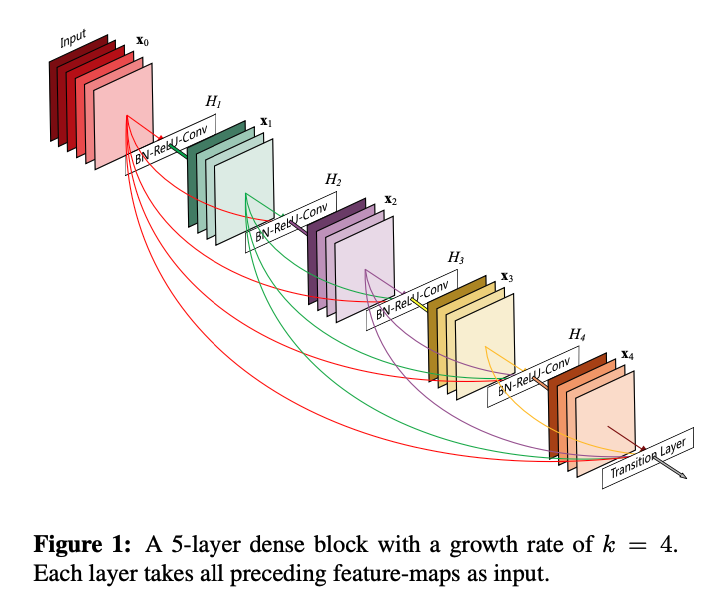
따라서 이전 레이어의 모든 feature map을 concat하여 레이어에 집어 넣는 구조를 사용했다.
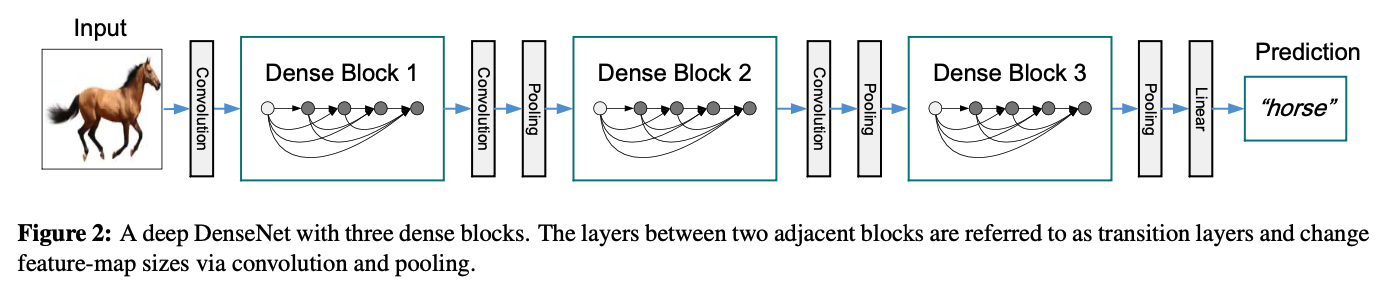
concat을 위해서는 feature map의 사이즈가 변하지 않아야 하는데, cnn에서는 down-sampling이 중요하기 때문에 dense blocks 사이에 transition layer라고 하는 convolution과 pooling을 넣어줘서 down-sampling을 할 수 있도록 하였다.
Growth rate
위에 나온 H 함수가 생성하는 feature map의 개수를 k라고 할 때, 이것을 하이퍼 파라미터로 두어 growth rate라고 이름 붙였다. 기존의 모델과는 다르게, k=12 등의 작은 값으로 두어도 좋은 성능을 보여줬다고 한다. 이전의 모든 feature map을 보기 때문에 feature map의 개수가 크지 않아도 괜찮은 성능이 나온다고 한다.
Bottleneck layers
기존의 모델에서 사용되던 bottleneck layer도 도입하였다. bottleneck layer를 사용한 모델은 DenseNet-B라고 이름 붙였다.
Compression
transition layer에서 feature map의 개수를 줄여줌으로서 모델의 compactness를 증가시켰다. 이것을 사용한 모델은 DenseNet-C라고 이름 붙였다.
Experiments
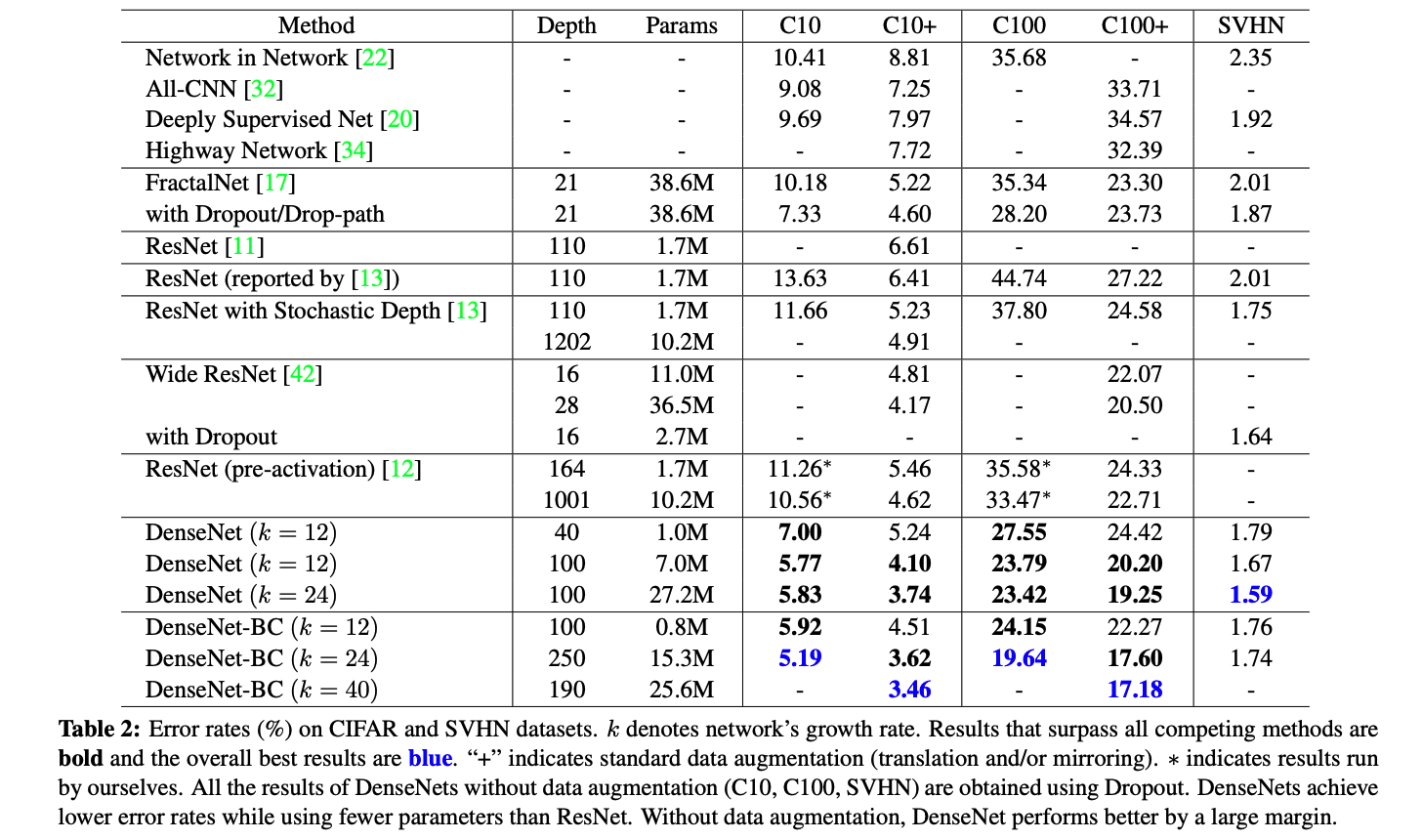
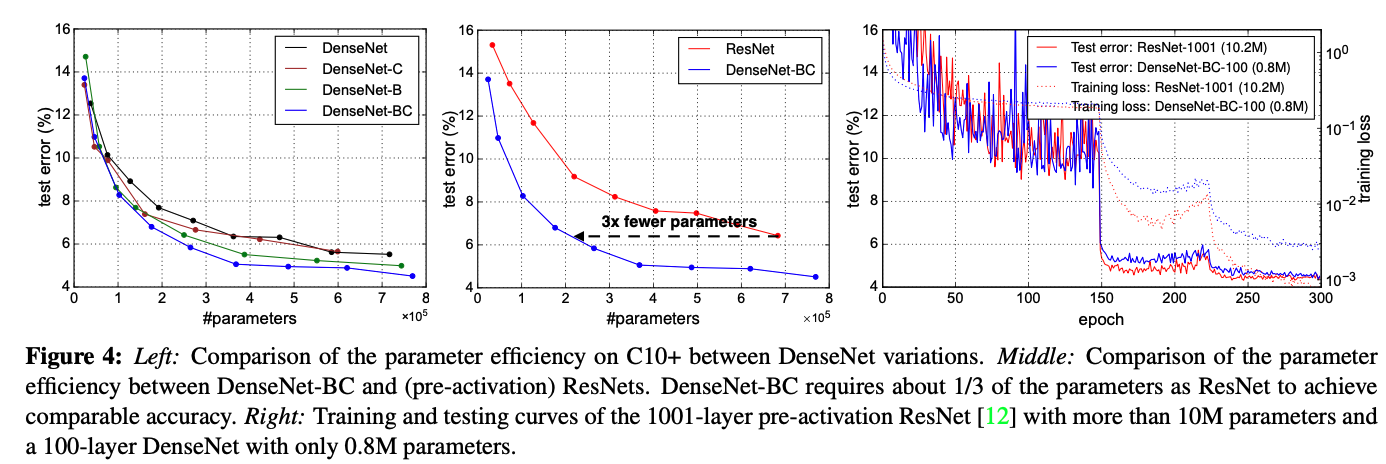
CIFAR와 SVHN dataset에 대해서 실험한 결과이다. 정확도가 괜찮으며, 파라미터의 효율성 또한 증가하였다. 또한 파라미터가 효율적으로 사용되고 있기 때문에, 오버피팅이 될 가능성도 낮아졌다.
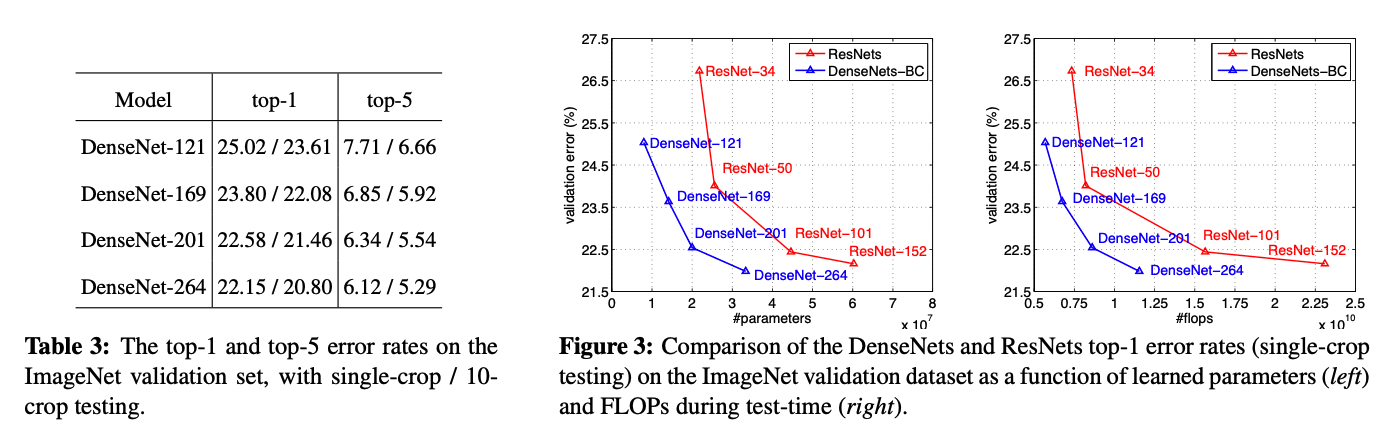
ImageNet dataset에 대해서 ResNet과의 성능 비교표이다. ResNet보다 성능이 좋은 것을 확인할 수 있다. 학습을 할 때, ResNet의 하이퍼파라미터를 그대로 사용했다고 하는데, 이는 하이퍼파라미터 튜닝을 할 경우, 성능이 더 좋아질 수 있다는 점을 시사한다.
Discussion
Model compactness
이전의 feature map을 각 레이어가 모두 보기 때문에, feature reuse가 일어나 model compactness가 증가한다.
Implicit Deep Supervision
각각의 레이어들이 이전 레이어들의 feature를 받아온다. 따라서 classifier에서 시작된 역전파가 가장 마지막의 레이어에만 직접적으로 가는 것이 아닌, 초기의 레이어까지 전달되기 때문에 deep supervision과 유사한 효과가 있어서 이점을 가진다.
Stochastic vs deterministic connection
임의의 레이어를 버리는 stochastic depth의 방법론과 유사한 측면을 가져서 성능이 높아졌을 수도 있다.
Feature Reuse
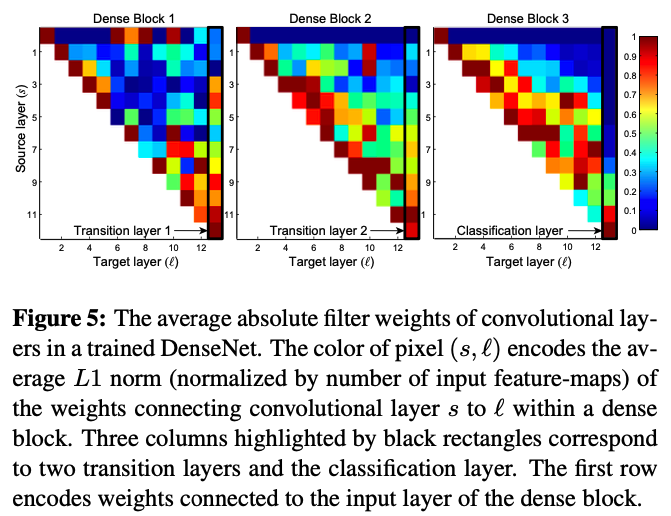
위의 figure를 보면, 모든 레이어들이 같은 block안의 weight에 관여하고 있는 것을 알 수 있다. transition layer 또한 weight를 이전의 dense block에 전하고 있고, 두 번째와 세 번째 dense block 같은 경우 transition layer에 적은 weight를 할당하고 있는데, 이는 transition layer가 불필요한 정보를 많이 뱉는다는 것을 나타내고, compression을 하는 DenseNet-BC가 성능이 잘 나오는 이유이기도 하다.
Conclusion
효율적인 파라미터를 통해 층을 늘리더라도 오버피팅이 잘 되지 않는 우수한 성능의 모델을 만들었고, 더 적은 파라미터와 계산량을 이용하지만 sota를 달성했다고 한다. 또한 identity mapping, deep supervision, diversified depth 등의 다양한 특징을 통합했고, 이는 더 compact하고 정확한 모델을 만드는데 기여했다. 다른 cv task에서도 좋은 성능을 낼 것으로 기대한다고 한다.
후기
DenseNet에 대해 알아봤는데, 이름만 들었을 때는 굉장히 파라미터도 많고 계산량도 많을 것 같았는데, 실제로는 매우 효율적인 모델이라 조금 놀랐다. summation이 아니라 concat이 더 좋은 성능을 보여준 것이 신기했고, 배울 점이 많은 논문이었다.
