[논문 리뷰] DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLab v2)
인공지능

오늘은 DeepLab: Semantic Image Segmentation with
Deep Convolutional Nets, Atrous Convolution,
and Fully Connected CRFs (DeepLab v2)에 대한 간단한 리뷰이다.
Method
Atrous Convloution for Dense Feature Extraction and Field-of-View Enlargement
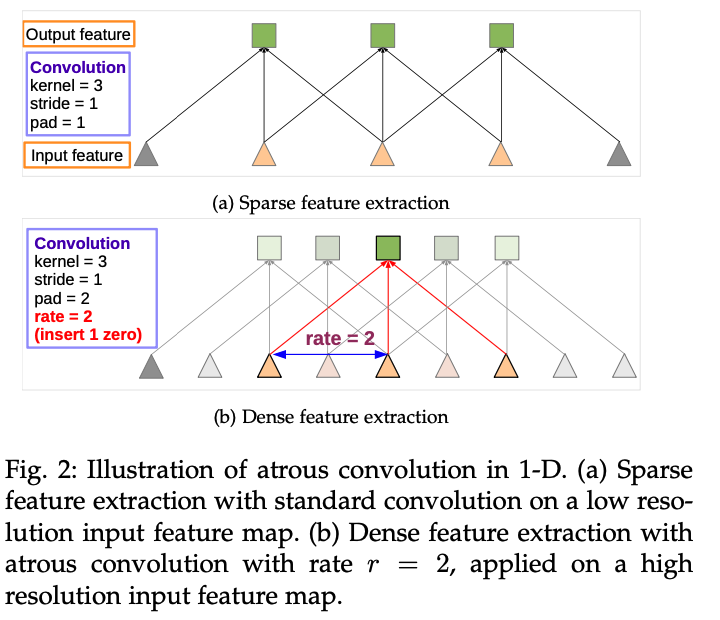
deeplab v1에서도 사용됐던 atrous convolution을 사용하여 feature extraction을 진행한다.
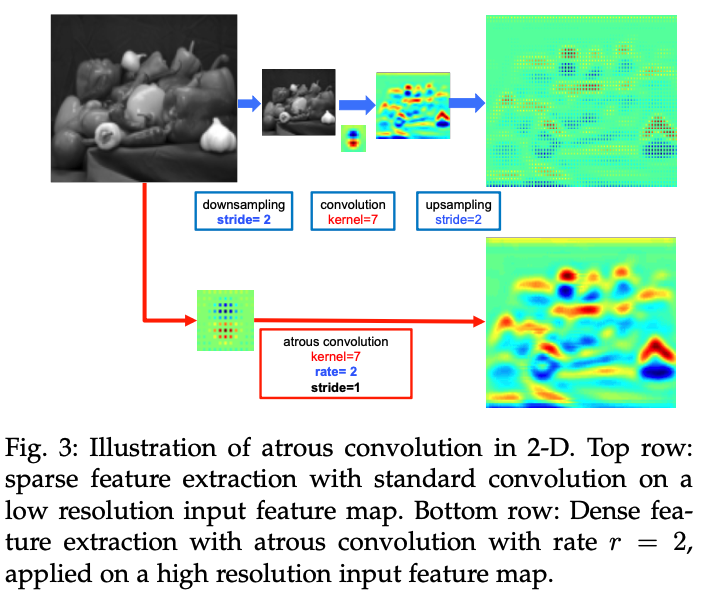
filter 사이에다가 0을 추가하여 conv를 할 때 dense한 feature가 만들어질 수 있도록 한다. 다만 r=2로 잡으면 연산량이 많아지기 때문에, r=4로 잡고 이후 bilinear interpolation을 통해 원본 이미지와 동일한 사이즈의 feature map을 만든다. 추가적인 파라미터가 필요없기 때문에, 학습 속도과 빨라지는 효과가 있다.
Multiscale Image Representations using Atrous Spatial Pyramid Pooling
multiscale로 추론을 진행하면 성능이 더 높아지기 때문에, 두 가지 방법을 시도한다.
첫 번째 방법은 기존에 많이 사용하던 방법으로, 다양한 크기의 이미지에서 score map을 뽑아내 bilinearly interpolation을 통하여 사이즈를 맞추고, fuse하는 방식이다. 성능이 증가하긴 하지만, 연산량이 많다는 단점이 있다.
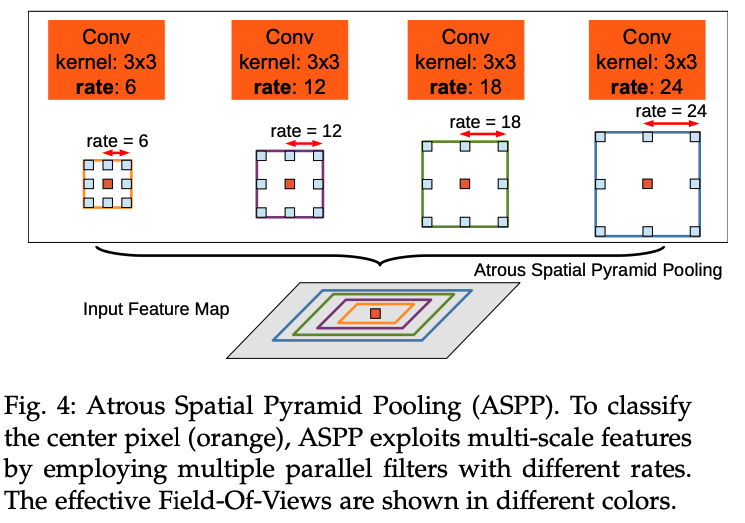
두 번째 방식은 R-CNN의 spaptial pyramid pooling에서 영감을 받은 것으로, 여러 rate의 atrous conv를 이용해 추론을 진행하는 방식이다. 이것을 atrous spatial pyramid pooling(ASPP)라고 이름붙였다.
Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
DeepLab v1에서 사용됐던 Fully-Connected CRF이다. 방식은 V1과 똑같은 것 같다.
Experimental Results
Learning rate policy
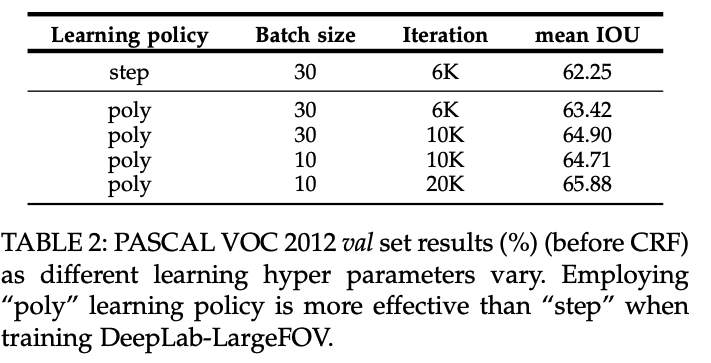
learning late를 조절할 때, step 방식보다 poly 방식이 더 좋은 성능을 보여줬다고 한다. step 방식은 고정된 step size로 learning rate를 줄이는 방식이고, poly는 가 계속 곱해지는 형태로 정의된다.
Atrous Spatial Pyramid Pooling
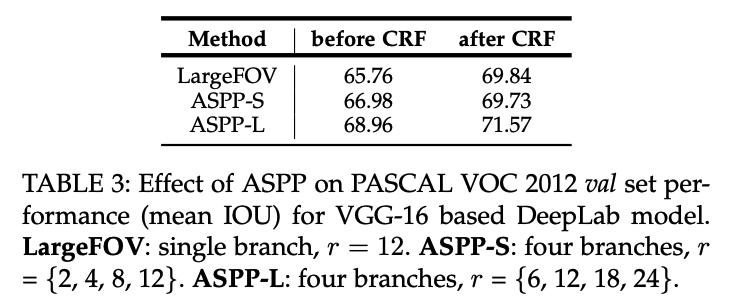
ASPP에서 각각의 r의 크기에 따른 성능 변화도 확인할 수 있다.
Deeper Networks and Multiscale Processing

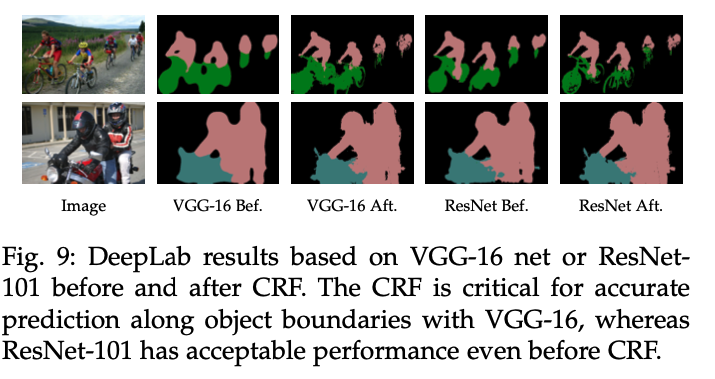
V1과 달리 backbone을 VGG-16이 아니라 ResNet-101을 사용했고, 그것이 성능이 더 좋았다고 한다.
다른 segmentation task(cityscapes, PASCAL-Person-Part 등)에서도 높은 성능을 보여준다.
후기
오늘은 DeepLab 시리즈의 두 번째 버전 논문을 읽어보았다. v1과 다른 점이라면, atrous spatial pyramid pooling의 도입, backbone을 VGG가 아니라 ResNet을 사용한 점을 꼽을 수 있겠다. object detection에서 사용된 spatial pyramid pooling 아이디어를 가져와 segmentation task에 적용하여 multi-scale로 이미지를 볼 수 있도록 한 점이 참신했다. 마지막 v3에서는 또 어떤 방법이 등장할 지 기대가 된다.
