
오늘은 Rethinking Atrous Convolution for Semantic Image Segmentation (DeepLab v3)에 대한 간단한 리뷰이다.
Methods
Atrous Convolution for Dense Feature Extraction
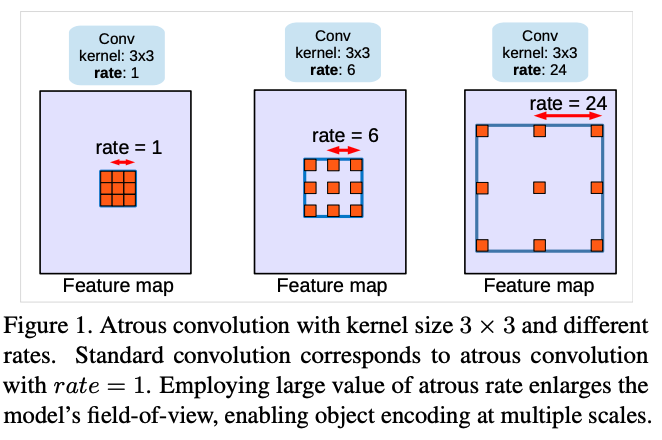
이전 버전에도 나왔던 atrous convolution에 관한 이야기이다.
Going Deeper with Atrous Convolution
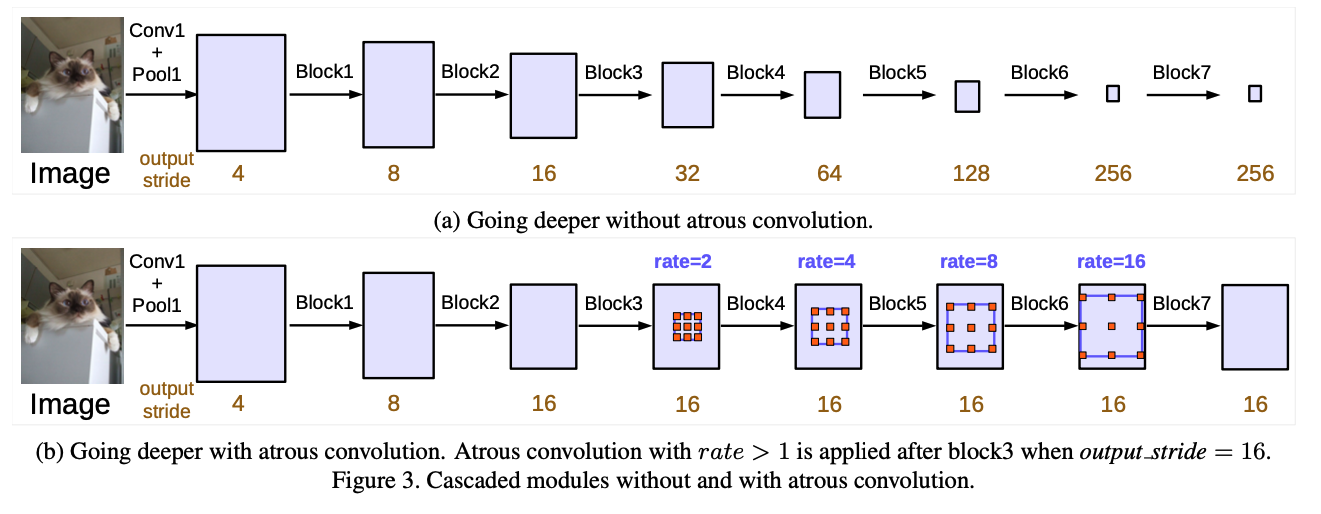
resnet의 블럭에서는 long range information을 잡기 위해 전체 이미지가 작은 크기의 feature map으로 압축되지만, segmentation에서는 그것이 성능에 별로 좋지 않다고 생각하여, atrous convolution을 적용하여 압축되지 않도록 하였다.
또한 위의 사진에서 block4에서 block7까지 각각의 다른 atrous rate를 적용하여 multi-grid 형태로 실험하였다.
Atrous Spatial Pyramid Pooling
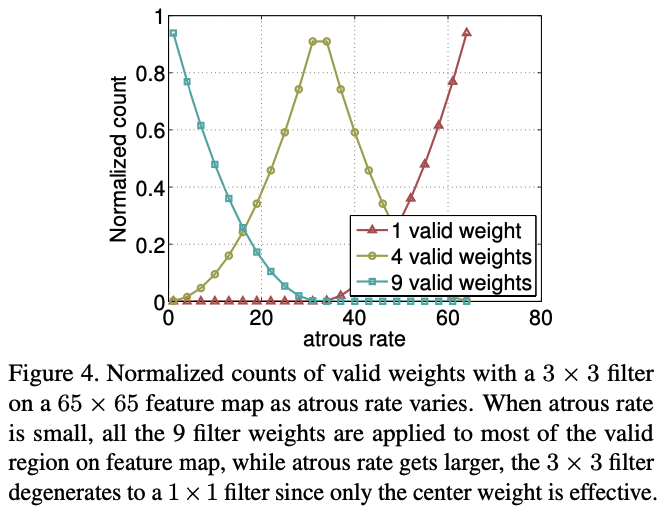
v2에서 적용되었던 Atrous Spatial Pyramid Pooling(ASPP)는 multi-scale information을 효율적으로 찾는다는 장점이 있었으나, atrous rate가 커질수록 유효한 weight가 적어지는 것을 발견했다.
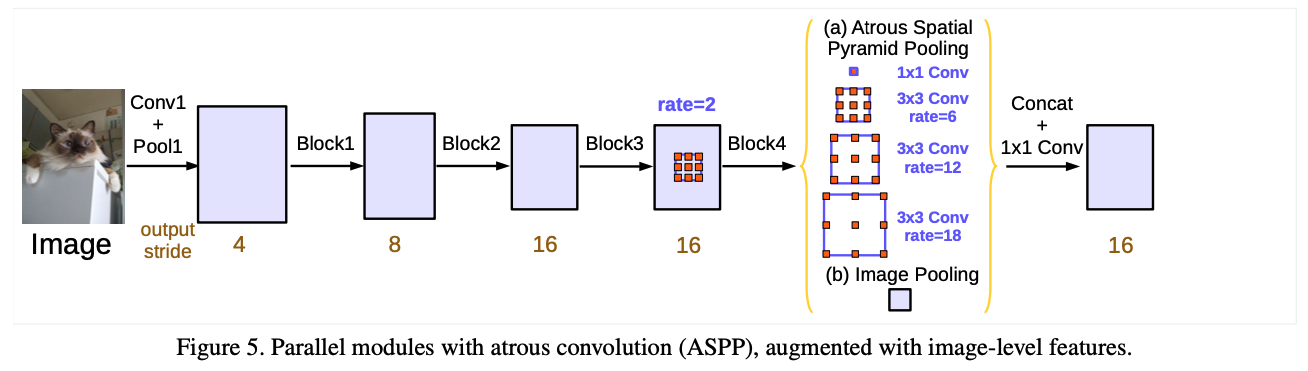
그래서 마지막 feature map에 global average pooling을 적용한 것을 추가로 넣어주고, ASPP를 진행하여 concat과 1x1 conv를 태운 후에 최종 결과물로 사용하였다.
Experimental Evaluation

resnet-50의 마지막 block의 output_stride의 효과를 측정하였더니, output_stride가 8일 때 가장 높은 성능을 보여줬다.
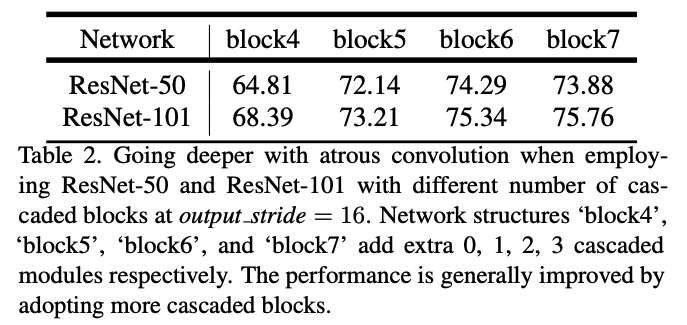
ResNet-50과 ResNet-101과의 비교, 그리고 cascaded block의 개수에 따른 성능 비교이다. ResNet-101을 사용할 때, 그리고 cascaded block을 많이 쓸 때 더 좋은 성능을 보여주고 있다.
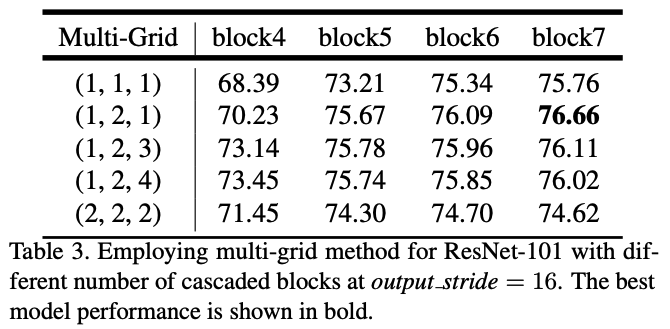
multi-grid도 실험을 했을 때 단순히 두 배가 된다고 좋은 것이 아님을 확인하였고, 최종적으로 (1, 2,1)일 때 가장 높은 성능을 보여 이것을 활용한다.

ASPP를 적용했을 때도 성능이 증가했고, 이때의 multi-grid는 (1, 2, 4)일 때 가장 높은 성능을 보여줬다.
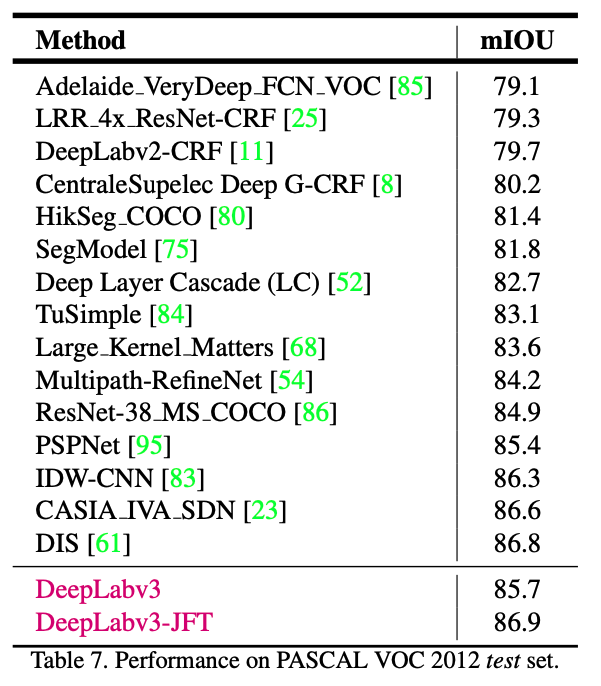
다른 모델과의 비교표이다.
v2 논문과 유사하게 다른 segmentation task에 대해서도 실험한 결과가 논문에 있다.
후기
DeepLab 시리즈의 마지막 논문이다. Rethinking Atrous Convolution for Semantic Image Segmentation라는 제목에 걸맞게, atrous convolution에 대해 집중적으로 개선하여 성능을 향상시켰다. deeplab 시리즈를 읽으면서 느낀 것은, 같은 cnn이라고 해서 모든 task에서 좋은 성능을 보여주는 것은 아니기 때문에, task를 잘 이해하고 그에 걸맞는 방법론을 적용해야 한다는 것이다. segmentation task에서는 dense한 정보가 필요하고, 약간의 정보 손실이 성능에 많은 영향을 미칠 수 있기 때문에 atrous convolution이라는 방법론이 사용된 것 같다.
이번주에는 segmentation task에 대해 좀 다뤄봤는데, 다음주는 아마도 r-cnn으로 시작하는 object detection task를 다룰 것 같다. 다른 것으로 바뀔 수도 있긴 한데, 아무튼 열심히 논문 읽어서 많은 인사이트를 얻어가야겠다.
