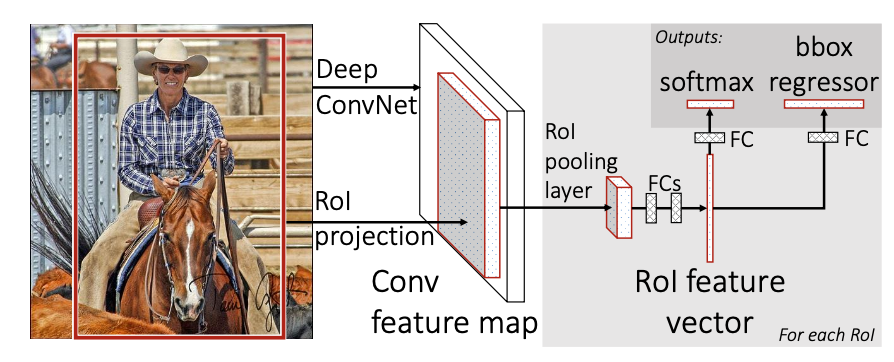
오늘은 Fast R-CNN에 대한 간단한 리뷰이다.
Fast R-CNN architecture and training
Fast R-CNN은 전체 이미지와 object proposals를 input으로 받는다. 먼저 전체 이미지에 대해 feature map을 뽑아내고, 이 feature map에서 각각의 object proposals에 대해 ROI Pooling을 통해 고정된 길이의 feature vector를 뽑아낸다. 이 vector를 활용해 classification과 bouding box regression을 수행한다.
The ROI pooling layer
ROI pooling layer는 roi의 feature map을 고정된 크기의 feature map으로 변환하기 위해 max pooling을 사용한다. h x w의 ROI window가 있다고 했을 때, 이것을 H x W의 고정된 크기의 윈도우로 분할하고, 각각의 subwindow에서 max 값을 취함으로써 이뤄진다.
Initializing from pre-trained networks
R-CNN과 같이 ImageNet에 pre-trained된 모델로 학습을 시작한다.
Fine-tuning for detection
먼저 N개의 이미지를 뽑고, R/N개의 ROI를 각각의 이미지에서 뽑는 hierarchical한 sampling 방식을 통해 기존 R-CNN이나 SPPNet이 갖고 있던 비효율성 문제를 해결하려고 했다.
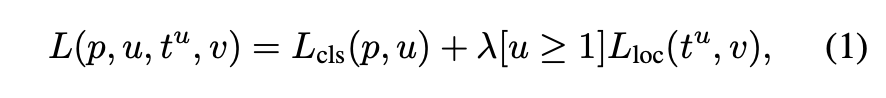
또한 위와 같은 multi-task loss를 사용하였다.
Fast R-CNN detection
Truncated SVD for faster detection
ROI가 많기 때문에 fc layer의 연산이 많아 속도가 느려지는 단점이 있다.
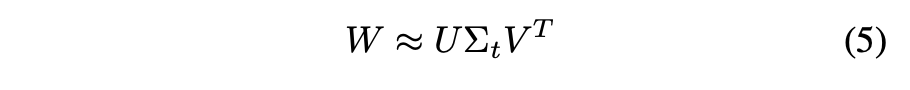
그래서 u x v weight matrix W를 위와 같이 truncated SVD하여 적용하면 파라미터 개수가 에서 로 줄어들어 layer를 압축할 수 있다.
Main results
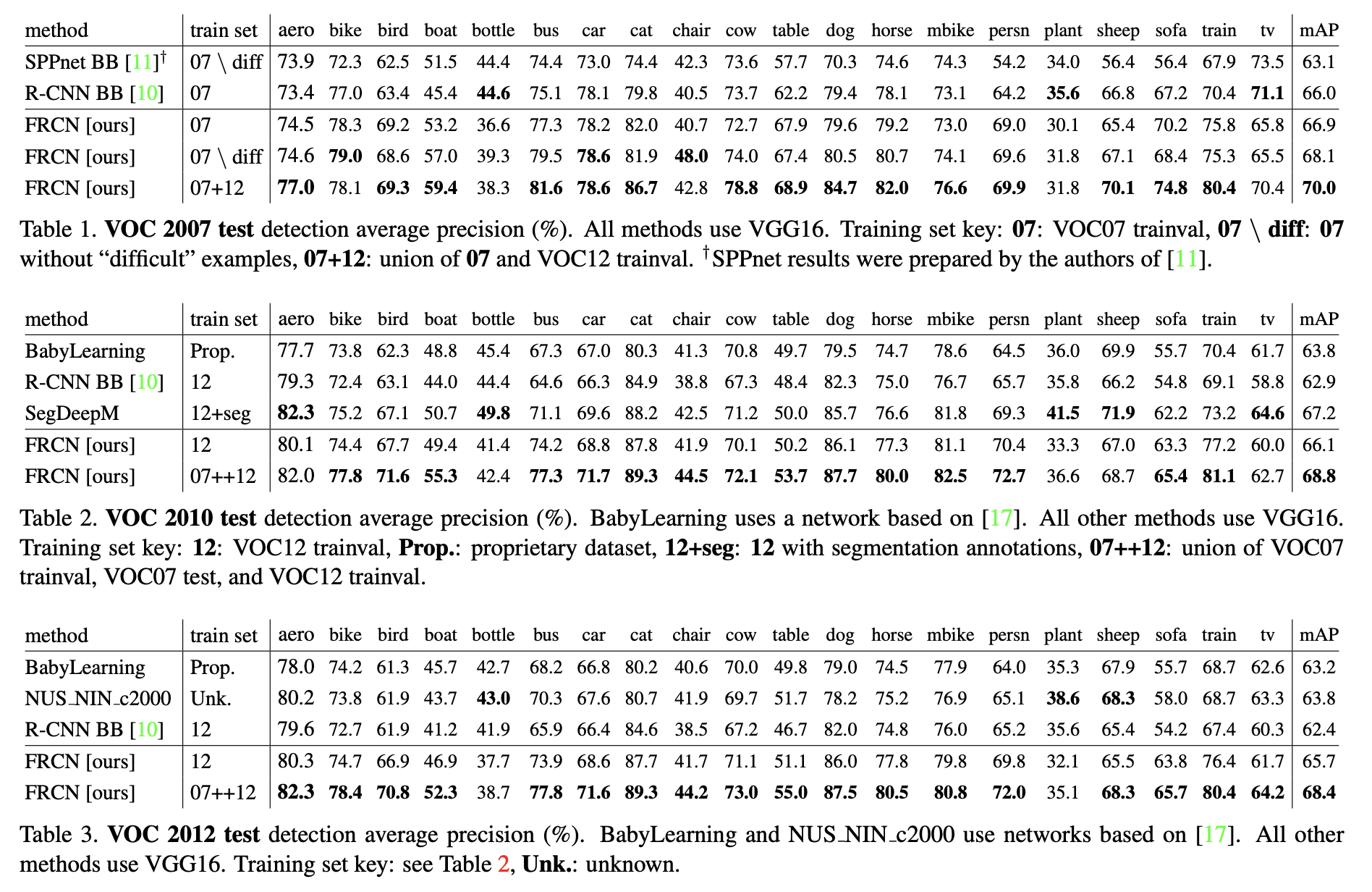
성능은 위와 같이 달성했다.
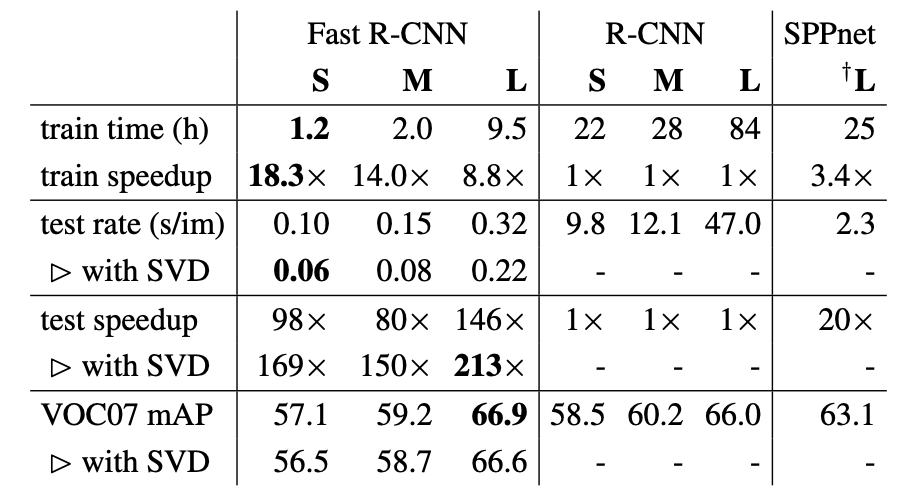
학습 시간, 추론 시간, 성능을 R-CNN, SPPnet와 비교한 결과이다.
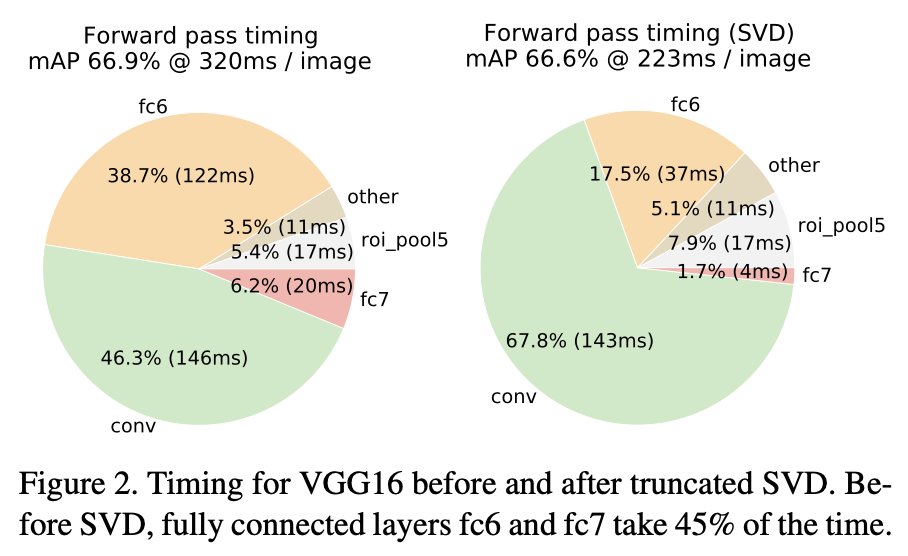
또한 SVD를 적용하니 fc layer가 차지하는 시간 비율이 많이 감소하였다.
Design evaluation
Does multi-task training help?

multi-task loss를 사용하고 bbox reg를 사용한 것이 좋은 성능을 보여줬다.
Scale invariance: to brute force or finesse?
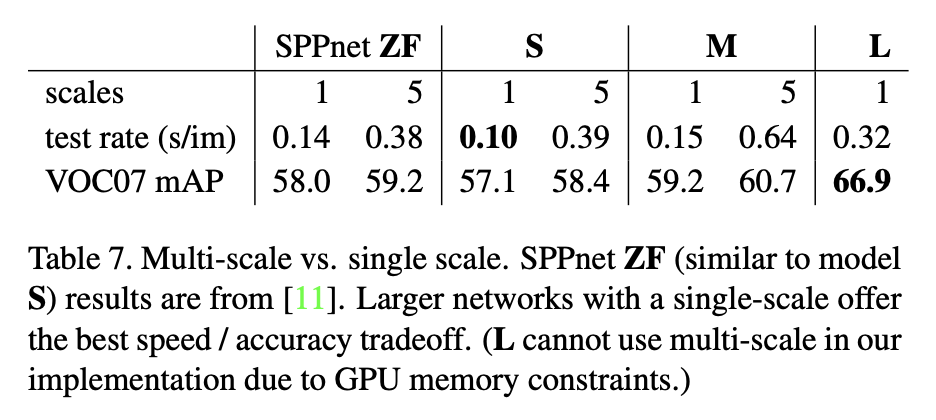
single scale과 multi scale은 약간의 성능 차이는 있지만, speed와의 trade off 관점에서는 single scale을 사용하는 것이 좋다고 한다.
Do SVMs outperform softmax?
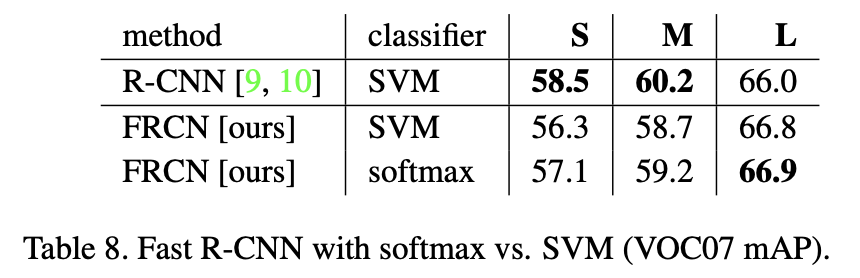
SVM이 softmax보다 약간 밀리는 경향을 보인다. 이는 R-CNN에서 사용했던 multi-stage training보다 fast R-CNN같은 one-shot training이 필수적이라는 것을 보여준다.
Are more proposals always better?
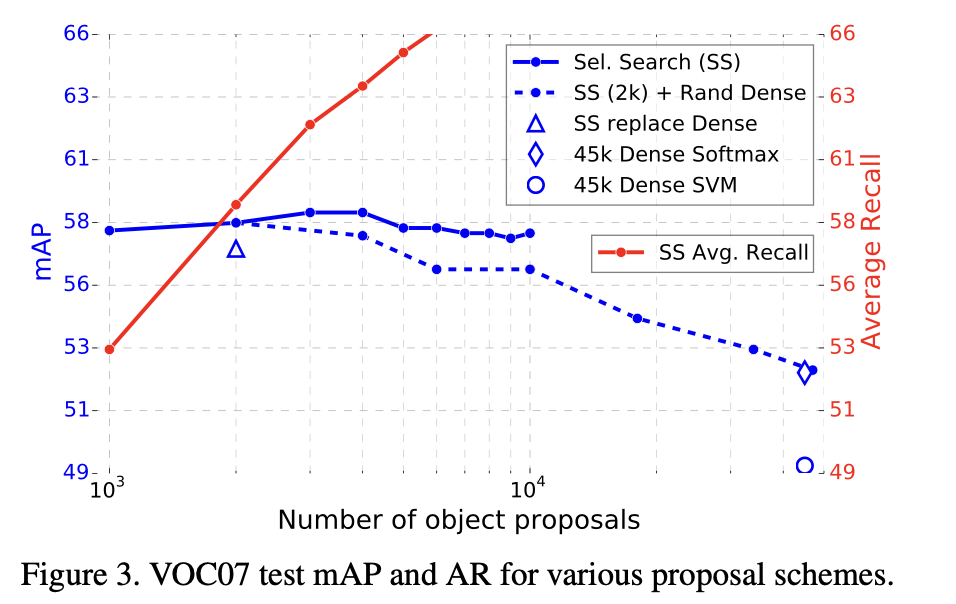
proposal이 많다고 해서 무조건 좋은 것은 아니라는 것을 확인할 수 있다.
후기
R-CNN의 다음 시리즈인 Fast R-CNN에 대해 알아보았다. ROI Pooling을 적용하고 SVM 대신 learnable한 classifier를 사용한 것이 특징이었다. Design evaluation에서 다양한 방법을 실험한 것이 재밌는 부분이었고, 실제 추론 사진도 있으면 좋았을 것 같은데 그건 좀 아쉽다. 다음 논문인 Faster R-CNN도 기대가 된다.
