[논문 리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN)
인공지능
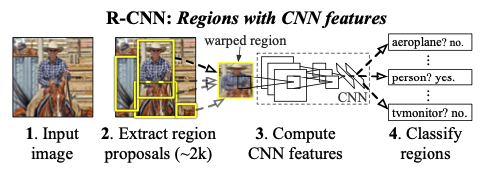
오늘은 Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN)에 대한 간단한 리뷰이다.
Object detection with R-CNN
Module design
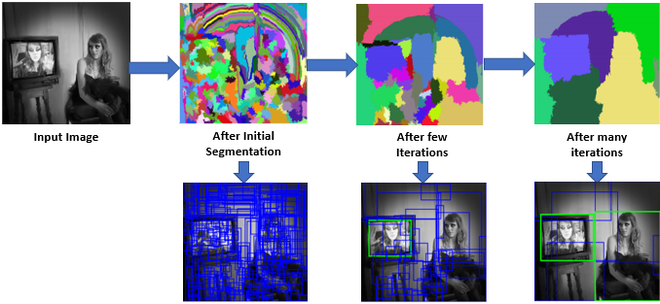
Region proposals의 경우 다양한 방법들이 존재하는데, selective search를 사용했다고 한다.

Feature Extraction의 경우, 각각의 region proposal마다 4096 차원의 벡터를 extract한다. 또한 물체에 딱 맞게 자르기보다는 어느 정도 픽셀의 여유를 뒀다고 한다. 논문에는 16픽셀을 사용하였다.
Test-time detection
test time에는 seletive search를 진행하여 약 2000개의 region proposals를 뽑은 후, 이미지 크기를 조정한 후에 feature를 뽑느다. 또한 각각의 class마다 SVM을 사용해서 score를 낸다. 다음 greedy non-maximum suppression을 통해 필요없는 region proposal을 지우는 작업을 거친다.
CNN의 파라미터가 공유되고 feature vector의 차원이 작기 때문에 효율적이고 추론도 빠르다고 한다.
Training
먼저 CNN을 큰 데이터셋에 pretrain하였다. ILSVRC2012 classification 데이터를 사용했기 때문에 image classification 능력을 학습시킨 것이다. 그 다음 detection이라는 새로운 도메인에서 fine-tuning시켰다. object classifier는 SVM을 사용한다.
Results on PASCAL VOC 2010-12
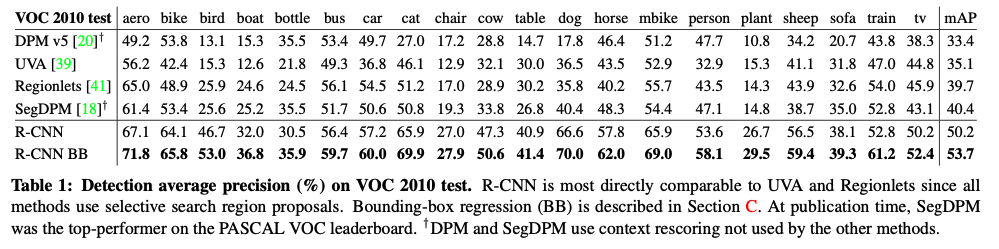
성능은 위와 같다.
Results on ILSVRC2013 detection
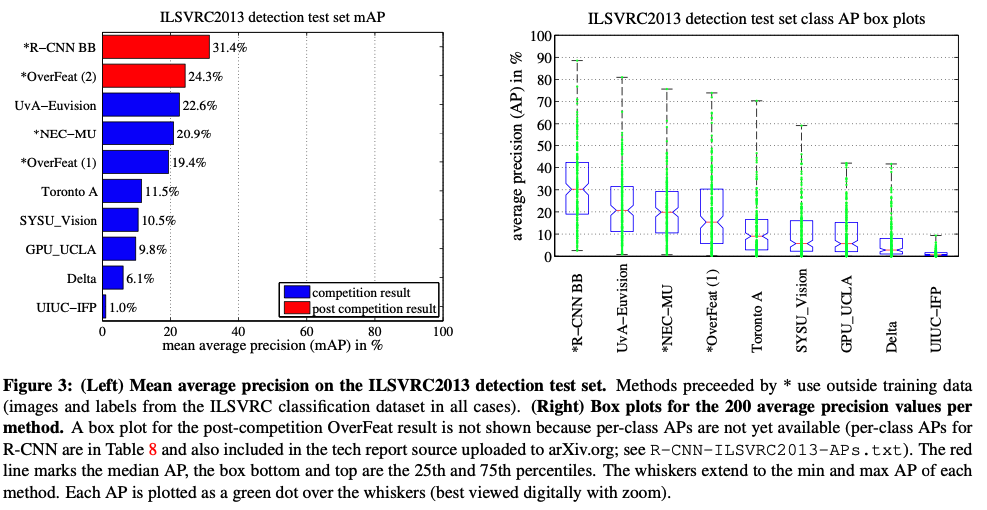
성능은 위와 같다.
Visualization, ablation, and modes of error
Visualizing learned features

필터가 학습한 것에 대한 visualization이다. 굉장히 일관성있는 모습을 볼 수 있다.
Ablation studies
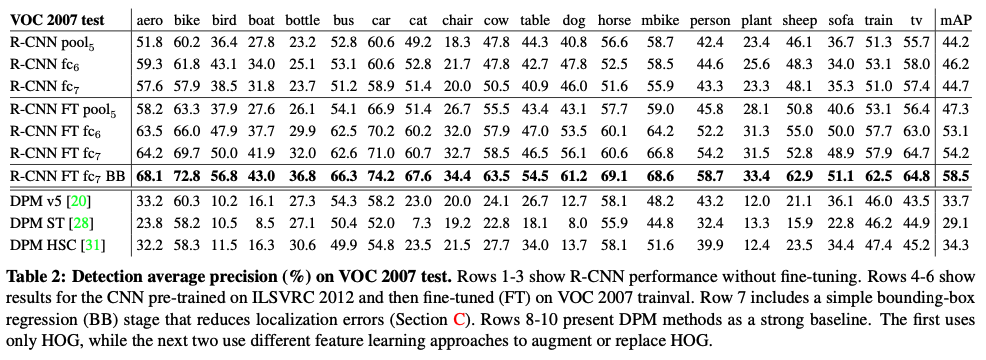
fc7보다 fc6이 성능이 더 높게 나왔고, fine tuing을 하니까 성능이 더 증가하는 모습을 보였다.
Network architectures

network architecture에 따른 성능 변화이다. T-Net은 우리가 알고 있는 AlexNet이고, O-Net은 VGG이다. classification 성능이 더 좋은 VGG가 더 높은 성능을 보여주고 있다. 논문에서는 성능이 좋은데 추론 시간이 VGG가 AlexNet보다 7배 더 길게 걸렸다고 한다.
Bounding-box regression

오류를 줄이기 위해, 간단한 bounding-box regression을 추가하여서 학습시켰다. 이 모델은 pool5의 feature를 받아서 선형 함수를 거쳐 box를 regression한다.
The ILSVRC2013 detection dataset
Region proposals
selective search는 이미지의 크기에 따라 region proposals의 개수가 달라진다는 단점이 있어서, 각각의 이미지의 너비가 500 pixel이 되도록 리사이즈한 후에 selective search를 적용했다.
Ablation study
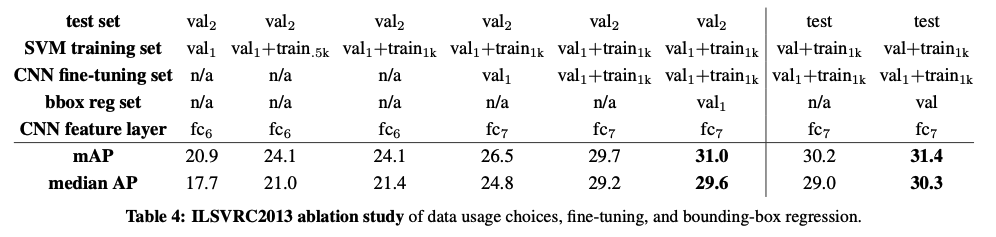
각각의 변경사항에 따른 성능 변화이다.
Semantic segmentation


Semantic segmentation에 대해서도 실험을 진행했다고 한다.
후기
논문이 추가 자료랑 사진이 많아서 21페이지나 됐는데 그래서 그런가 굉장히 벅찼다. 리뷰도 간단하게만 적어두었다. 그래도 여기서 시작된 개념이 fast r-cnn, faster r-cnn에서도 쓰이는 게 있다보니 굉장히 중요한 논문인 것 같다. 여러 데이터셋에서 실험을 해보면서 문제를 찾고, 개선해나가는 과정이 재밌었고, 그랬기 때문에 당대 기준으로 괜찮은 성능을 달성하였다. 다음 논문도 기대가 된다.
