오늘은 ImageNet Classification with Deep Convolutional
Neural Networks 논문에 대한 간단한 리뷰이다.
Dataset
ImageNet 데이터셋을 사용하였으며, 256x256으로 크기를 고정하여 사용하였다. 직사각형의 경우 더 짧은 변을 256으로 맞추고, 크롭을 하였다.
The Architecture
다섯 개의 convolutional layer와 세 개의 fc layer로 이루어져 있고, 색다른 방법을 몇 개 사용하였다.
ReLU Nonlinearity
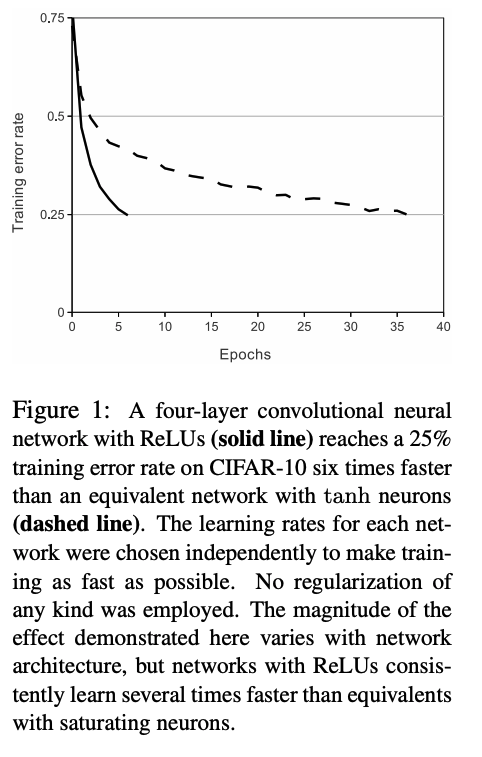
일반적으로는 비선형성을 위해 tanh 함수를 사용하지만, 이 논문에서는 ReLU 함수를 사용하였다.
ReLU를 사용하면서 tanh 함수보다 train error가 빨리 줄어드는 것을 발견하였다고 한다.
Training on Multiple GPUs
이때 당시 사용했던 GPU는 GTX 580으로, 3GB의 메모리를 가지고 있다. 최근에 나온 4090이 12GB인 것을 생각하면 악랄한 메모리이긴 하다. 적은 메모리를 해결하기 위해, 두 개의 GPU에 모델을 나눠서 학습을 진행했다고 한다.
Local Response Normalization(LRN)
ReLU 이후에 아래와 같은 Normalization을 적용했다고 한다.

Overlapping Pooling
이때 당시에는 Pooling을 할 때 서로 겹치지 않도록 했던 것 같다. AlexNet에서는 Stride의 크기를 줄임으로써 Pooling이 겹쳐지도록 구성했고, 오버피팅을 살짝 방지해주는 효과를 발견했다고 한다.
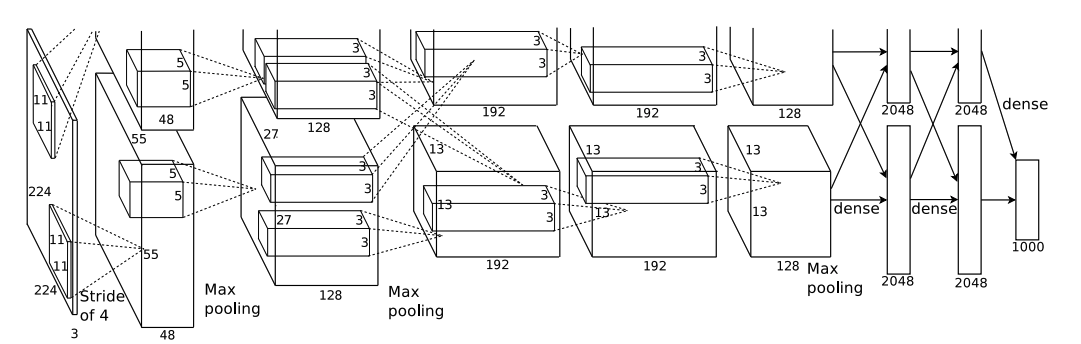
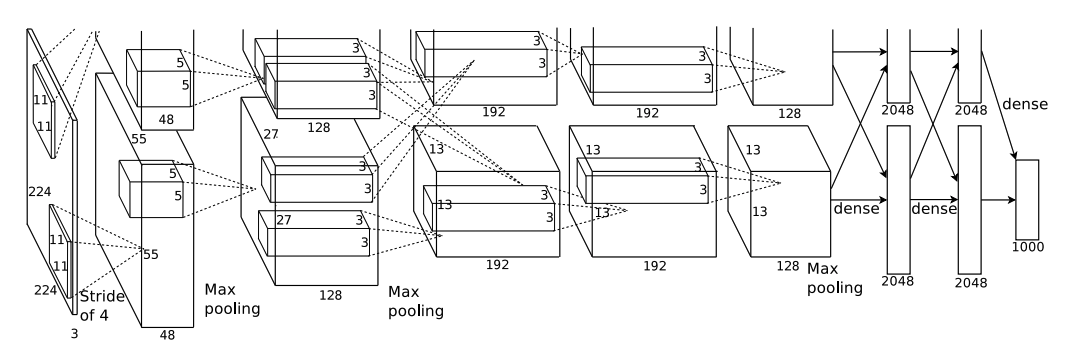
Overall Architecture
전반적인 아키텍처는 다음과 같다.
Reducing Overfitting
오버피팅을 방지하기 위한 방법론을 몇 가지 소개한다.
Data Augmentation
첫 번째 방법은, 256x256의 이미지에서 224x224 사이즈를 가진 랜덤 크롭 혹은 horizontal flip된 랜덤 크롭을 뽑아 학습시키는 것이다. 이렇게 학습시켜놓고, test할 때는 4개의 코너에서 크롭을 하고, 중앙에서 한 개를 크롭하여 softmax 아웃풋을 평균내어 최종 prediction으로 사용했다.
두 번째 방법은, training set 전체의 RGB 픽셀 값에 대하여 PCA를 진행하여 각 주성분을 random variable을 사용하여 랜덤하게 더해줌으로써 augmentation을 진행했다.
Dropout
현재에는 잘 알려져 있는 방법으로, 확률적으로 weight를 제외시켜서 일반화 성능을 높이는 방법이다.
Details of learning
학습 과정에서 사용된 하이퍼파라미터들과 sgd의 자세한 식 등이 나와있다.
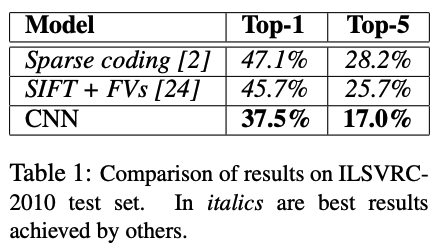
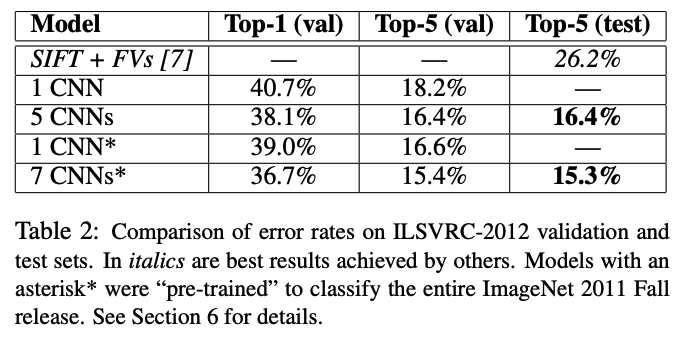
Results
후기
첫 논문으로 AlexNet을 선정해봤는데, 생각보다 재밌었다. 특히 새로운 augmentation 방법인 pca color augmentation을 알 수 있었고, 그때 당시의 환경이 어땠는지도 알 수 있는 귀중한 시간이었다. 논문 리뷰를 이런 식으로 하는 게 맞는지 모르겠는데, 여러 개 해보면서 최적의 방법을 찾아가야겠다.
