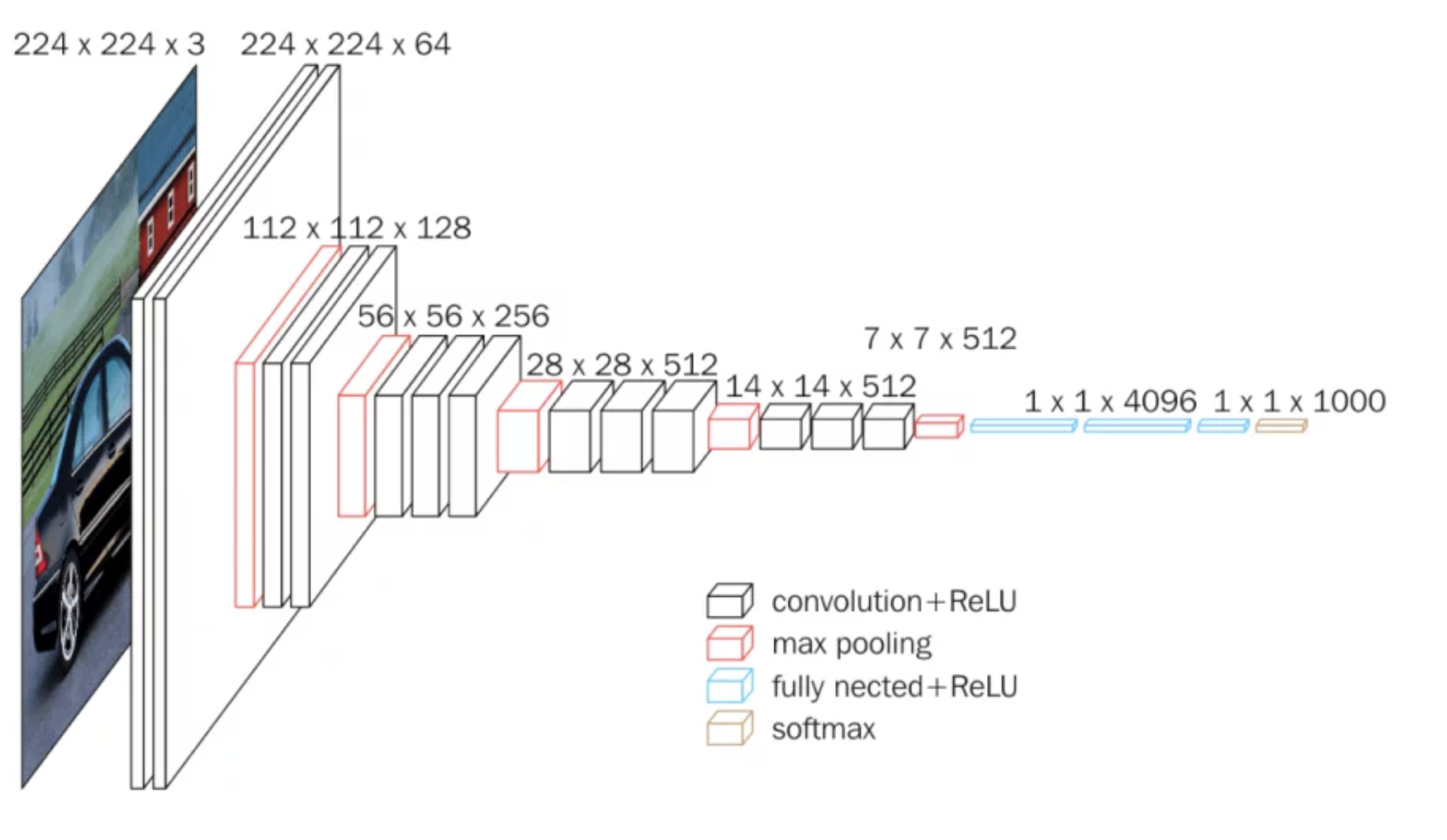
오늘은 Very Deep Convolutional Networks for Large-Scale Image Recognition (VGGNet)에 대한 간단한 리뷰이다.
(썸네일 출처: https://neurohive.io/en/popular-networks/vgg16/)
Architecture
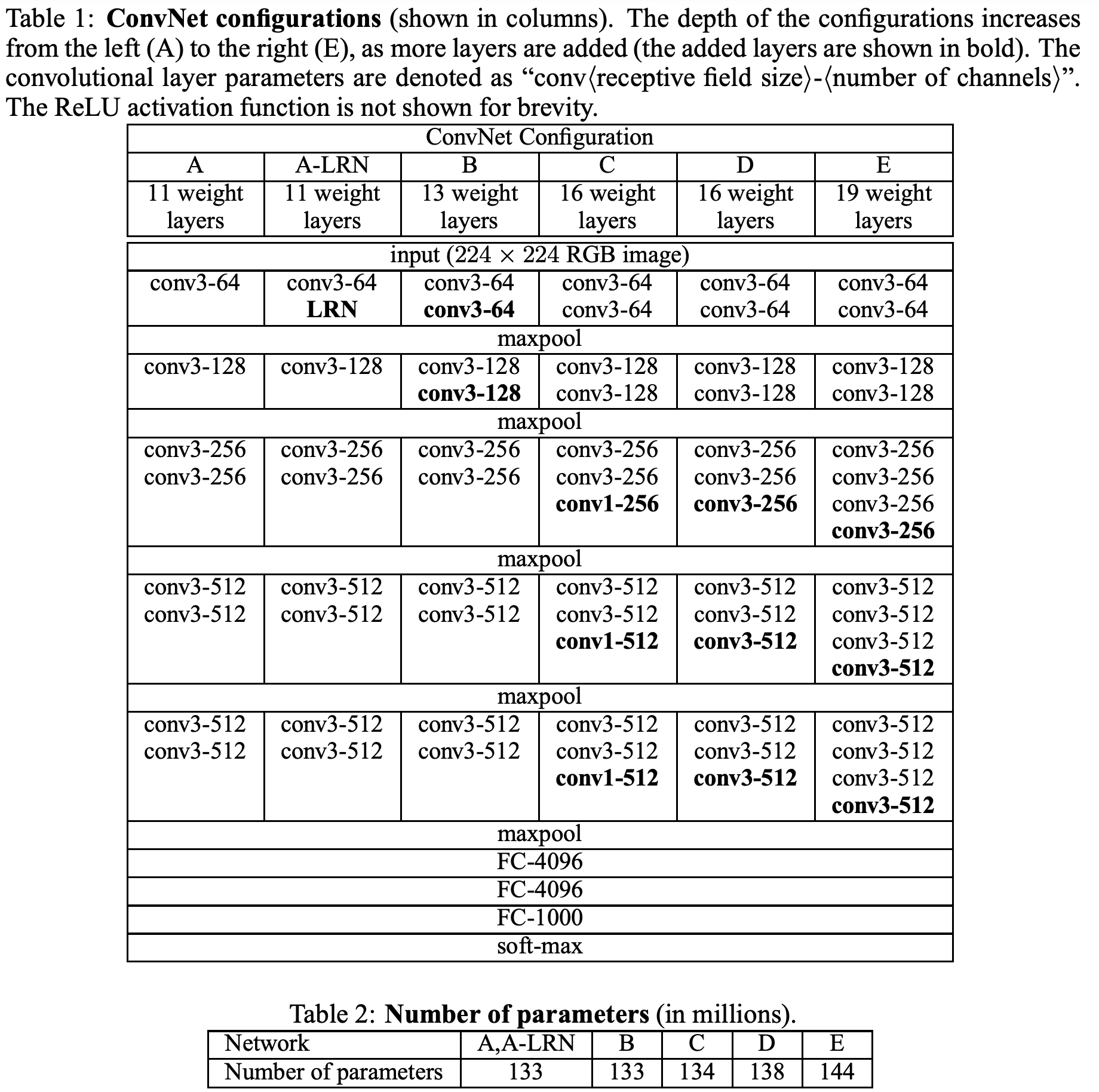
실험에서 사용한 여러 모델의 아키텍처와 파라미터 수이다. B -> E로 갈 수록 모델이 깊어지는 것을 확인할 수 있다.
Classification Framework
학습과 평가 과정의 디테일들을 설명한다.
Training
사용했던 하이퍼파라미터를 소개하고 있다.
weight의 초기화 부분이 인상적인데, 위의 아키텍처에서 가장 얕은 모델인 A를 학습시키고, 이것보다 깊은 모델은 weight 초기화를 할 때 랜덤으로 하는 것이 아니라 A의 weight를 가져와 적용시키고 학습을 진행하였다.
이미지 사이즈에 대해서도 다양하게 실험했는데, 첫 번째 방식은 고정된 이미지 사이즈를 사용하는 것이다. 256x256과 384x384 이미지에 대해서 실험했으며, 후자의 사이즈는 전자에서 학습된 weight를 적용하여 더 적은 학습률로 학습했다.
두 번째 방식은 특정한 범위에서 랜덤으로 이미지 사이즈를 추출하여 적용하는 방식이다. 이미지 내에서 물체의 크기가 다 다를 것이기 때문에 이 방식이 유용할 것이라고 생각했다고 한다.
Testing
이미지 사이즈가 학습할 때와 같을 필요가 없다. 그 이유는 fc layer를 cnn으로 바꾸고 풀링을 통해 평균내면 되기 때문이다.
또한 여러 크롭을 추론한 뒤에 평균 내는 것이 계산량을 많이 잡아먹지만, 정확도가 좋아지는 효과가 있기 때문에 그 방법도 적용하였다.
Classification Experiment
Single-scale Evaluation
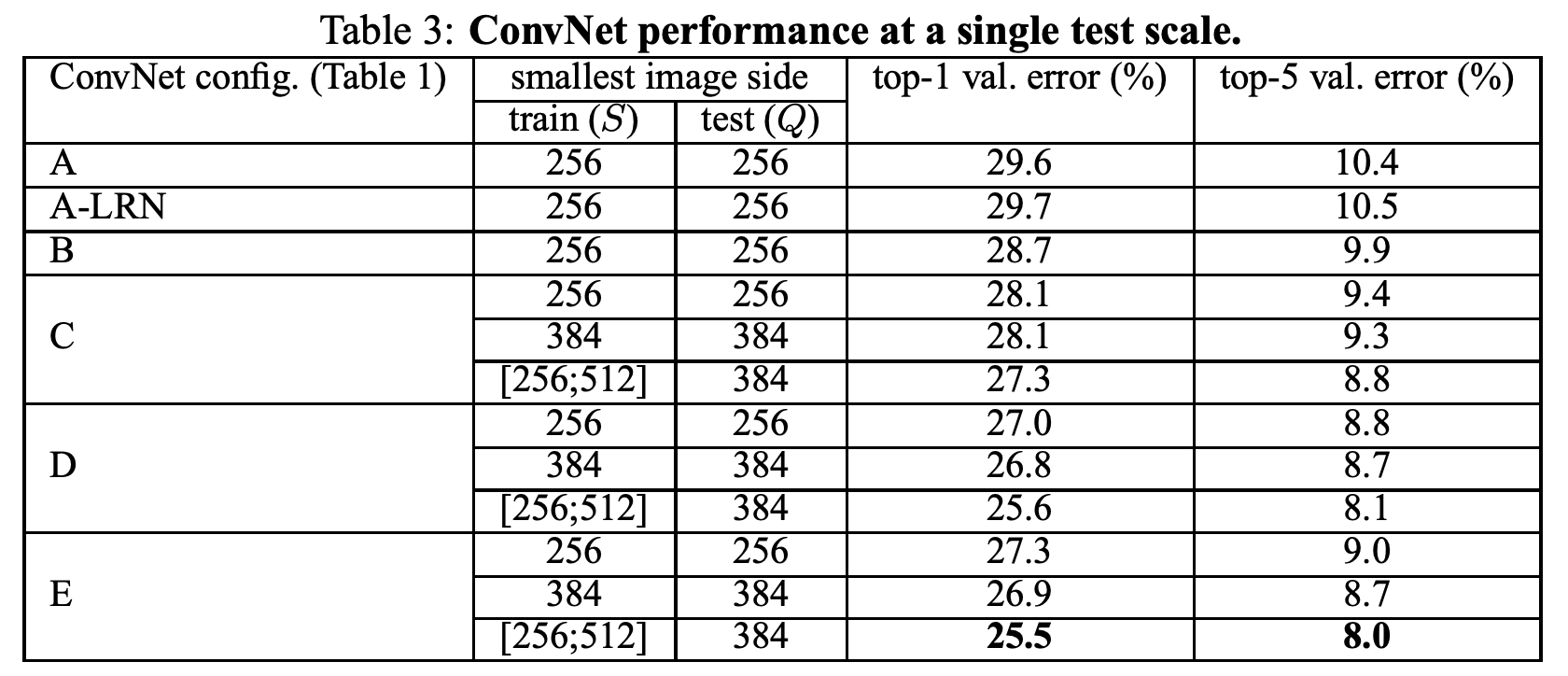
첫 번째로, AlexNet에서 적용했던 LRN은 효과가 없었다.
두 번째로, 모델의 깊이가 깊어질 수록 정확도가 올라가는 효과를 확인하였다.
마지막으로, training 과정에서 여러 사이즈를 적용하는 것이 test 과정에서 고정된 이미지를 사용하더라도 좋은 성능을 보여주는 것을 확인하였다.
Multi-scale Evaluation
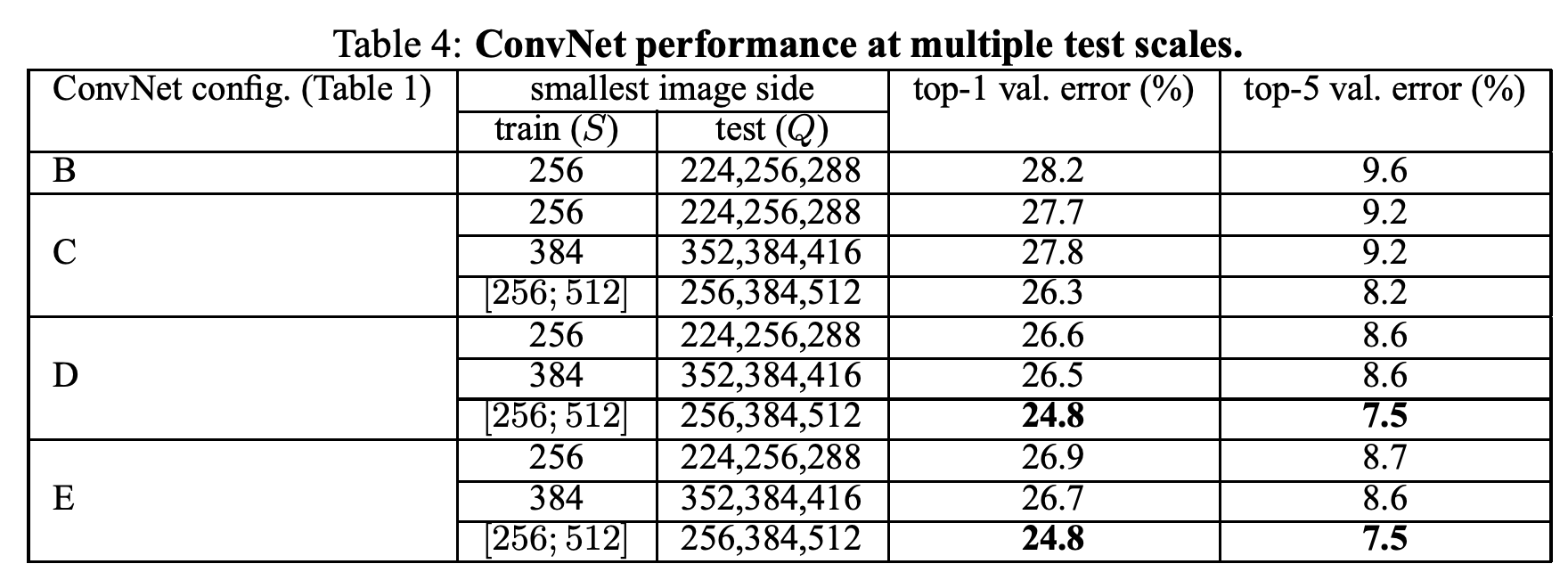
test 과정에서 여러 사이즈의 이미를 사용하는 것은 고정된 이미지를 사용하는 것보다 좋은 성능을 보여줬다.
Multi-crop Evaluation
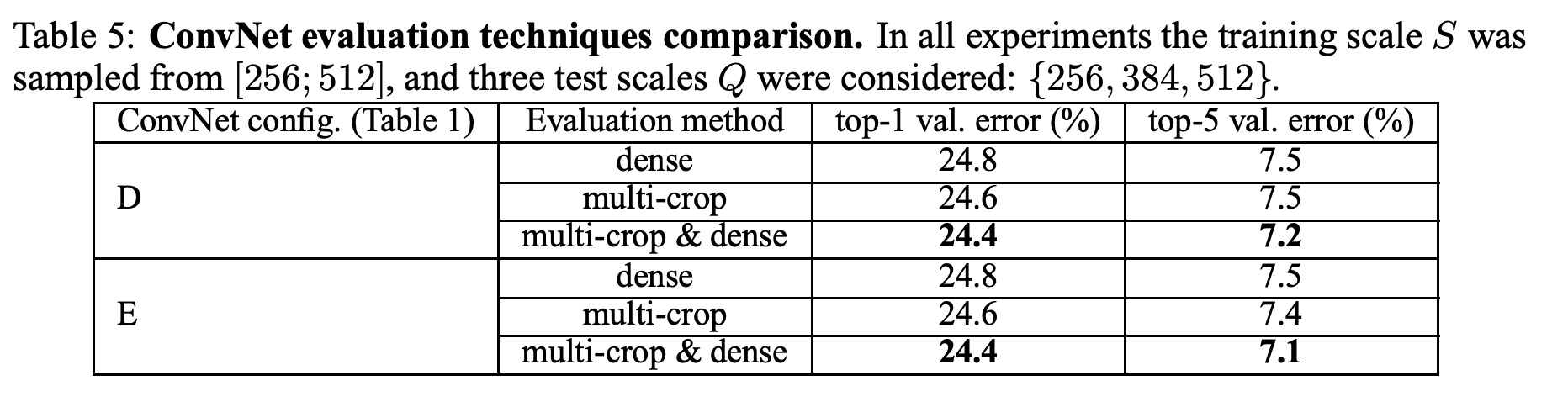
multi-crop 방식도 성능 향상을 보여줬다.
Convnet Fusion

익히 알려져 있듯, 여러 모델을 앙상블 하는 것도 기존 모델 대비 성능 향상을 보여줬다.
Conclusion
결국 모델의 깊이가 성능에 관련있다는 것을 말하고 싶었던 것 같다. 또한 appendix로 classification task말고도 다른 여러 task와 데이터셋에서도 같은 모델을 사용한 실험이 있는데, 기존의 복잡한 파이프라인과 거의 비슷하거나 능가하는 성능을 보여준다.
후기
오늘은 VGGNet에 대해 알아보았다. 모델의 깊이가 성능과 관련이 있다는 점을 잘 상기시켜주는 논문인 것 같다. 수업에서 배웠을 때는 몰랐는데 논문을 직접 읽으면서 시야가 약간은 넓어지는 느낌이다.
