오늘은 Neural Machine Translation by Jointly Learning to Align and Translate (Attention)에 대한 간단한 리뷰이다.
Learning to Align and Translate
Decoder: General Description
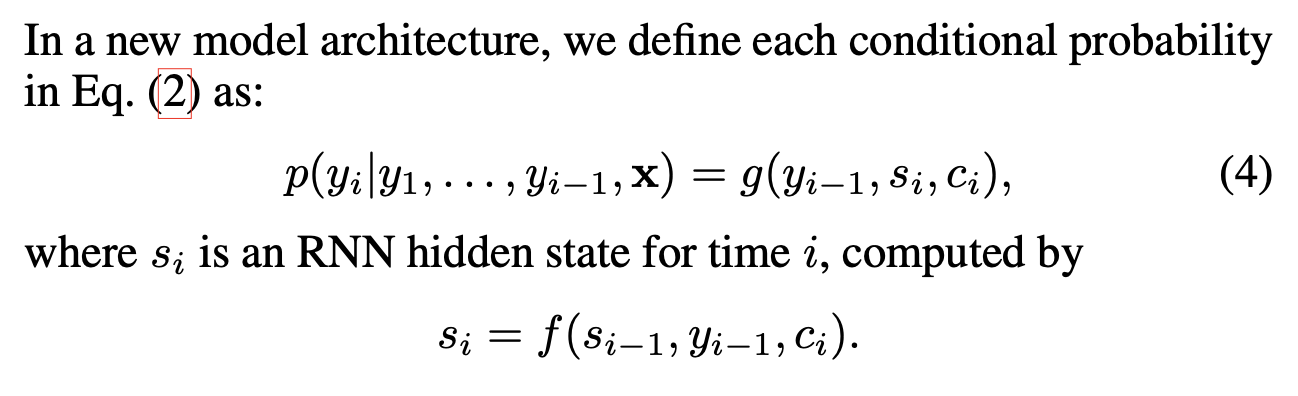
새로운 모델에서는, 위와 같은 조건부 확률을 정의한다. 기존의 RNN에서 사용됐던 확률과 달리, context vector가 추가되어 있다.

context vector는 위와 같이 정의된다. 여기서 h는 인풋 sequence의 각각의 element들을 매핑한 것이다. 그래서 해석하자면, hidden state s와 인풋의 임베딩 h를 가지고 e를 만들고, 각각의 e를 softmax에 태워서 확률값으로 변환한다. 이 확률값을 기반으로 인풋의 임베딩 h의 각각에 가중치를 주어 context vector를 만드는 것이다.
이러한 과정이 모두 neural network를 통해 이뤄지기 때문에, backprop을 통한 학습이 가능하고, decoder 입장에서는 alignment score를 기반으로 집중할 element를 골라내어 추론을 수행할 수 있게 된다.
Encoder: Bidirectional RNN for Annotating Sequences
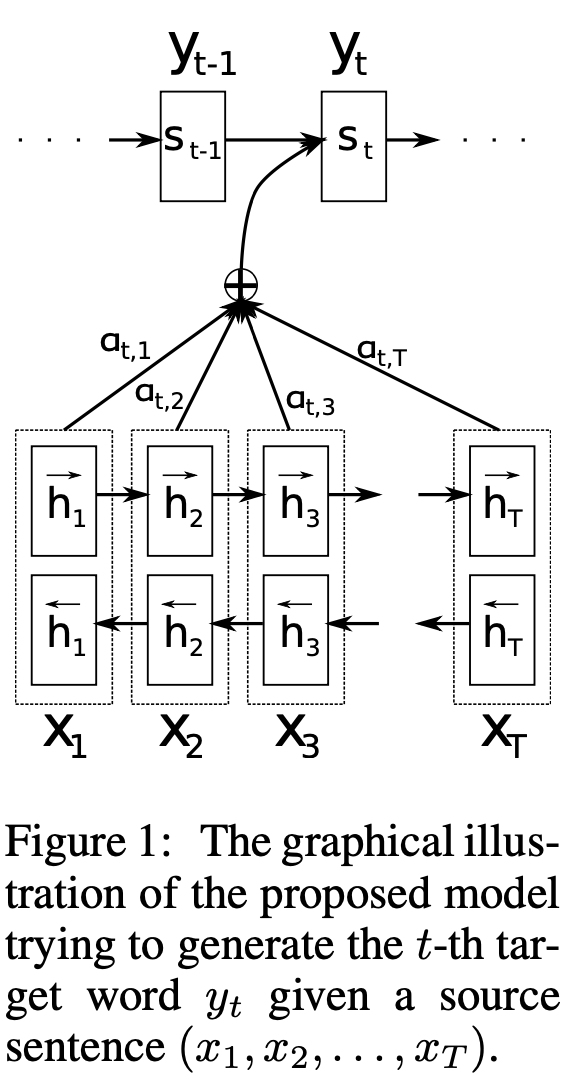
Bidirectional RNN을 적용하여, 앞에서부터 RNN을 적용한 임베딩들과, 뒤에서부터 RNN을 적용한 임베딩을 concat함으로써 단어의 앞쪽과 뒤쪽의 정보를 모두 담을 수 있도록 하였다.
Results
Quantitative Results
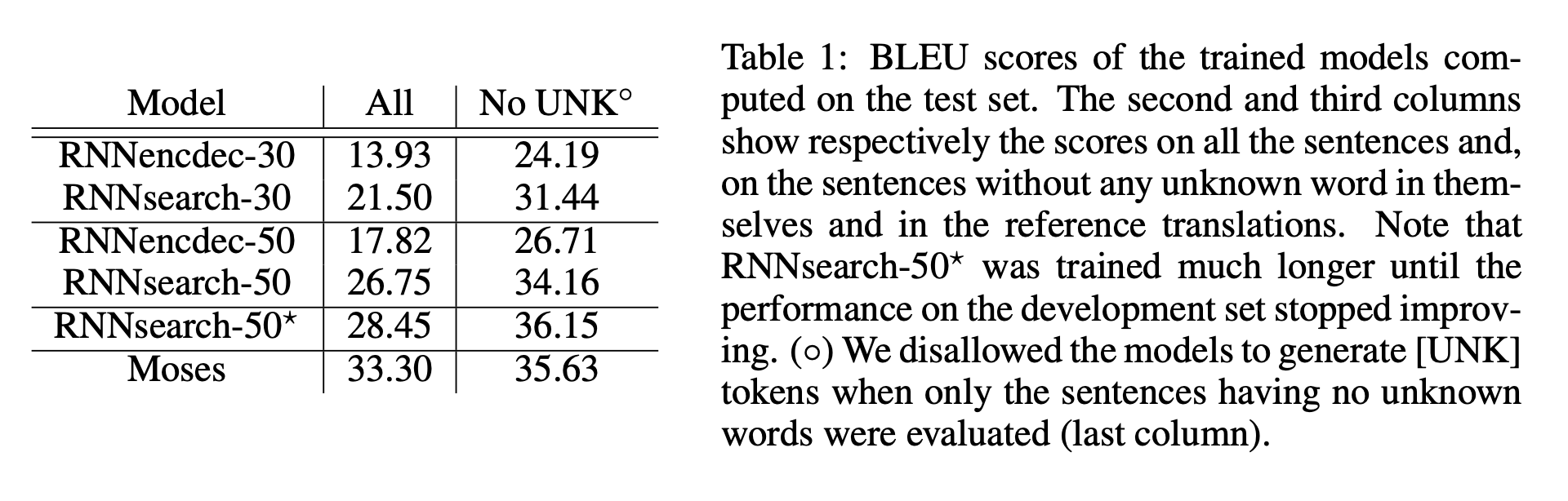
기존의 RNN encoder-decoder 구조보다 새로 제안한 구조가 더 좋은 성능을 보여주고 있다. 특히 문장의 길이가 길어졌을 때도 준수한 성능을 보여준다.
Qualitative Results
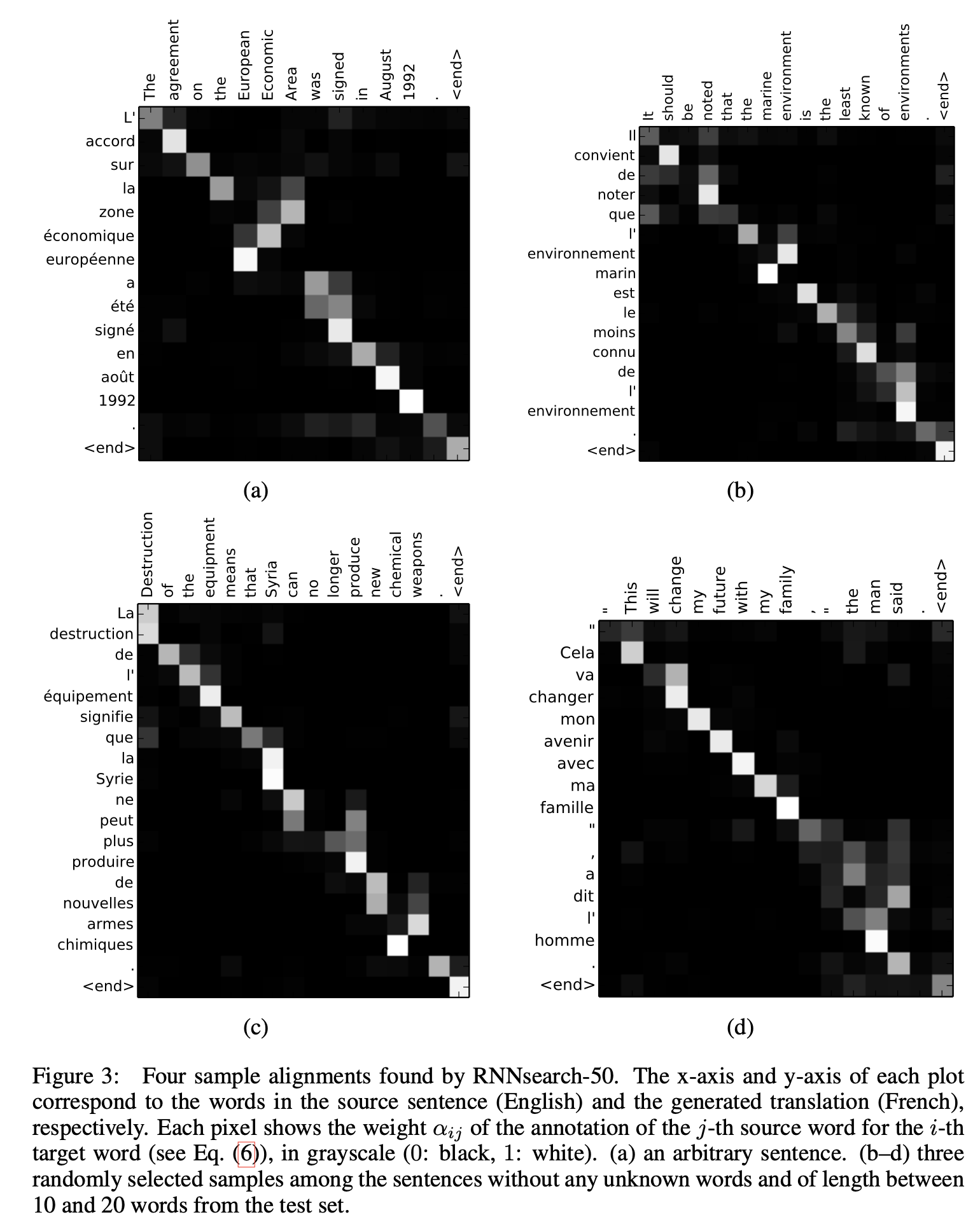
alignment score를 시각화한 것이다. 대각선의 형태로 잘 이루는 것을 확인할 수 있고, 영어와 프랑스어가 형용사와 명사의 순서가 다르다는데 그것도 반영하여 번역을 수행한 것을 확인할 수 있다.
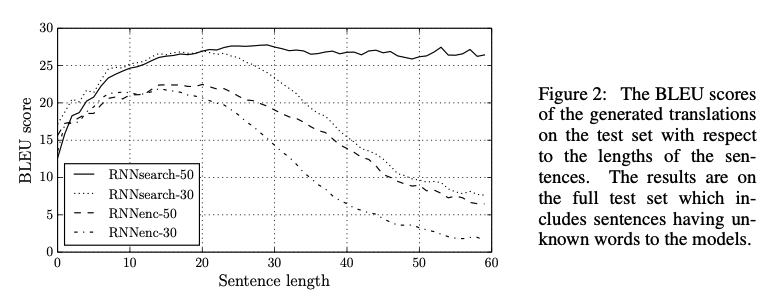
또한 길이가 긴 문장에 대해서도 성능이 감소하지 않고 유지하는 것을 확인할 수 있다.
후기
오늘은 Attention을 다룬 논문에 대해 읽어보았다. 처음에 Attention을 배웠을 때 굉장히 참신하다고 생각했었는데, 그걸 다룬 논문을 읽으니 감회가 새로웠다. 특히 alignment score를 시각화한 것도 보는 맛이 있었고, 길이가 긴 문장에 대해서도 성능이 떨어지지 않았다는 점이 인상깊었다. 다음 논문은 Attention을 활용하여 이미지 캡셔닝을 다룬 논문이다. 기대가 된다.
