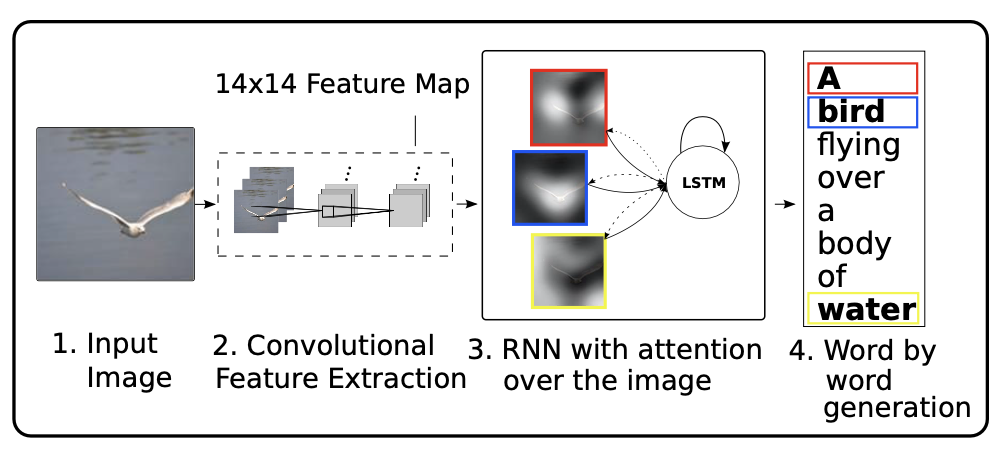
오늘은 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention에 대한 간단한 리뷰이다.
Image Caption Generation with Attention Mechanism
Model Details
Encoder: Convolutional Features
conv layer를 활용하여 이미지에서 feature vector를 뽑고, 이를 annotation vector라고 이름붙인다. 이전의 연구와 달리, 초기의 conv layer에서 vector를 뽑아서, 각각의 벡터가 이미지의 부분 부분에 잘 대응되도록 하였다.
Decoder: Long Short-Term Memory Network

LSTM의 구조를 가져와 사용하였고, annotation vector와 hidden state를 가지고 e를 계산, 이것을 softmax에 태워서 weight를 계산한다. 이후 context vector를 계산할 때 이 weight와 annotation vector를 활용한다.(Attention)
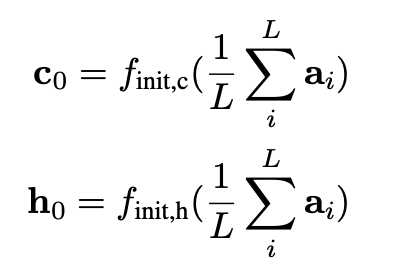
또한 LSTM 구조에서 사용되는 initial state와 initial hidden state는 위와 같이 계산된다.
Learning Stochastic “Hard” vs Deterministic “Soft” Attention

이 부분은 잘 설명해놓은 블로그 글이 있어 첨부합니다.
https://ahjeong.tistory.com/8
Experiments
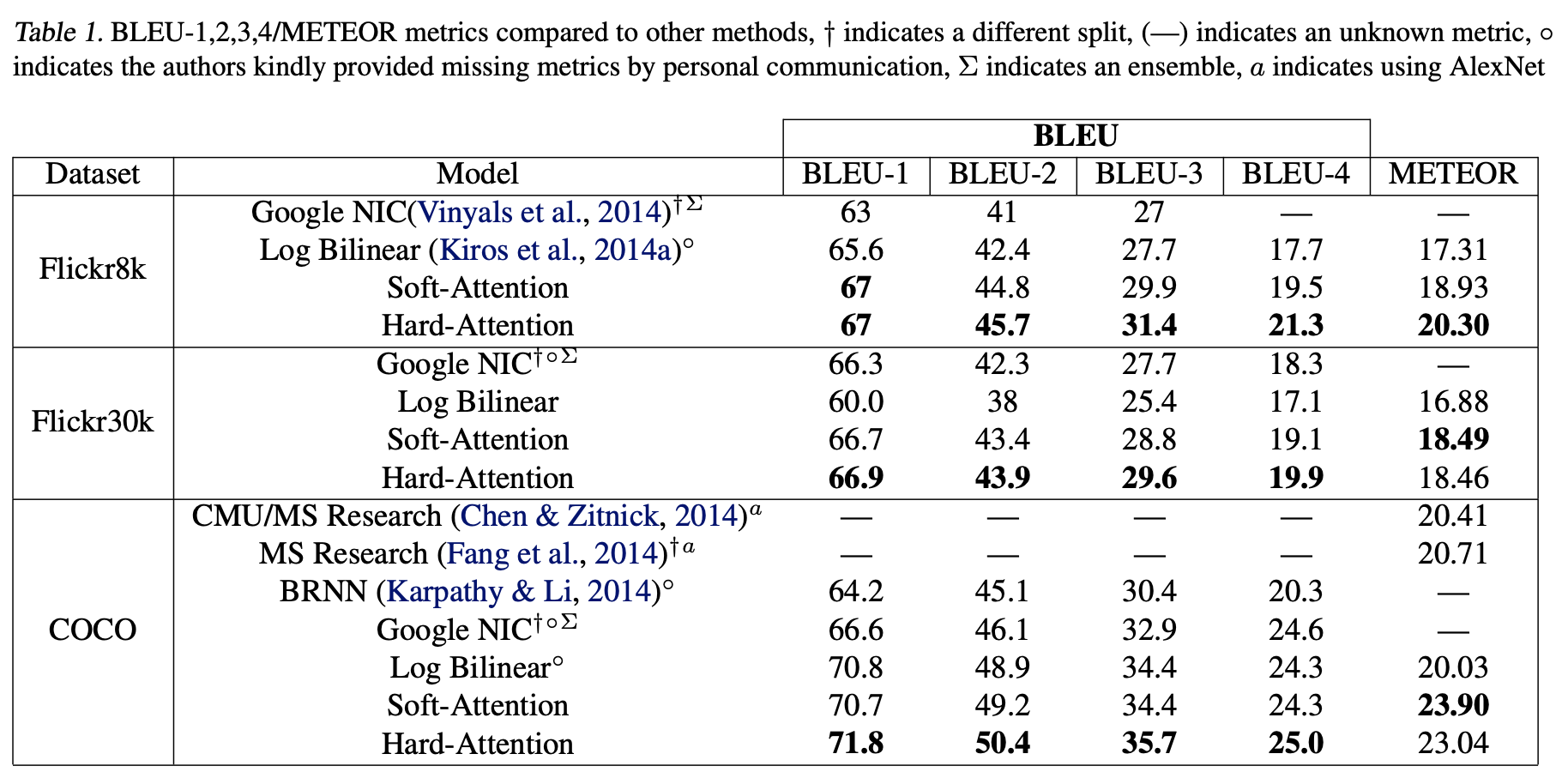
성능은 위와 같다.

Attention을 visualize한 것이다. 단어에 해당하는 object를 잘 포착하고 있다.
후기
오늘은 간단하게 Attention을 활용해 Image Captioning Task를 수행한 논문을 읽어보았다. Hard Attention과 Soft Attention을 논문만 보고는 이해하기 어려워서 다른 글을 찾아봤더니 쉽게 설명해놓은 글이 있어서 도움을 좀 받았다. 다음 논문은 매우 유명한 논문인 Attention is All you need 논문이다.
