오늘은 Scene-aware Human Pose Generation using Transformer에 대한 간단하지 않은 리뷰이다.
Method
이미지와 위치가 주어지면, 위치를 중심으로 하는 직사각형 안에 합리적인 포즈를 생성한다. 포즈 Keypoint는 16개(이전 논문은 17개인데 하나는 어디갔는지 모르겠다)로 구성되어져 있고, K개의 포즈 템플릿과 이미지가 서로 상호작용하면서 affordance pose를 생성한다.
Pose Template Construction
먼저, 학습 데이터에서 대표 포즈를 뽑기 위해 k-means clustering을 진행한다. 먼저 포즈를 normalize하고, 클러스터링을 할 때는 거리 함수는 euclidean distance를 사용하고, K=14로 지정한다.
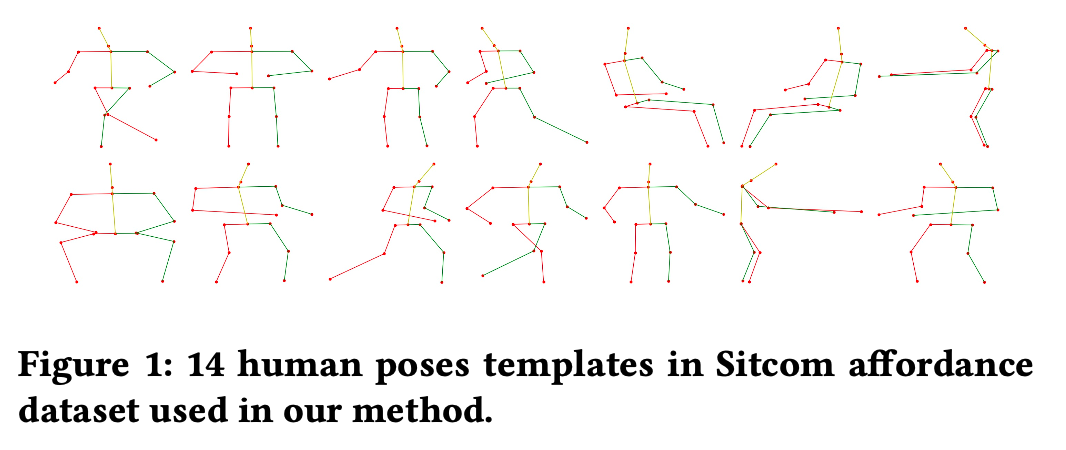
뽑은 포즈는 위와 같다.
포즈를 normalize할 때는 먼저 박스의 중심을 (0, 0)으로 정의하고, 길이는 1이 되도록 하여 각 포즈의 keypoint 좌표가 -0.5에서 0.5 사이의 값을 가지도록 normalize한다.
Scene Image Preparation
이미지는 여러 정보를 모델에 넣어주기 위해서, 3가지의 형태로 준비한다.
1. global한 feature를 담는 전체 이미지
2. local한 context를 담는, 이미지 높이만큼의 길이를 한 변으로 가지는 정사각형 패치
3. 2번의 이미지에서 좀 더 high-resolution 정보를 담는, 이미지 높이의 반만큼의 길이를 한변으로 가지는 정사각형 패치
이 이미지 3개를 224x224로 리사이즈하여 사용하였고, 각각의 샘플의 label은 pose class, scale, normalized pose로 이루어져 있다. 이때 scale은 포즈의 실제 높이와 너비를 원래 이미지의 높이로 나눈 값이다.
Network Architecture
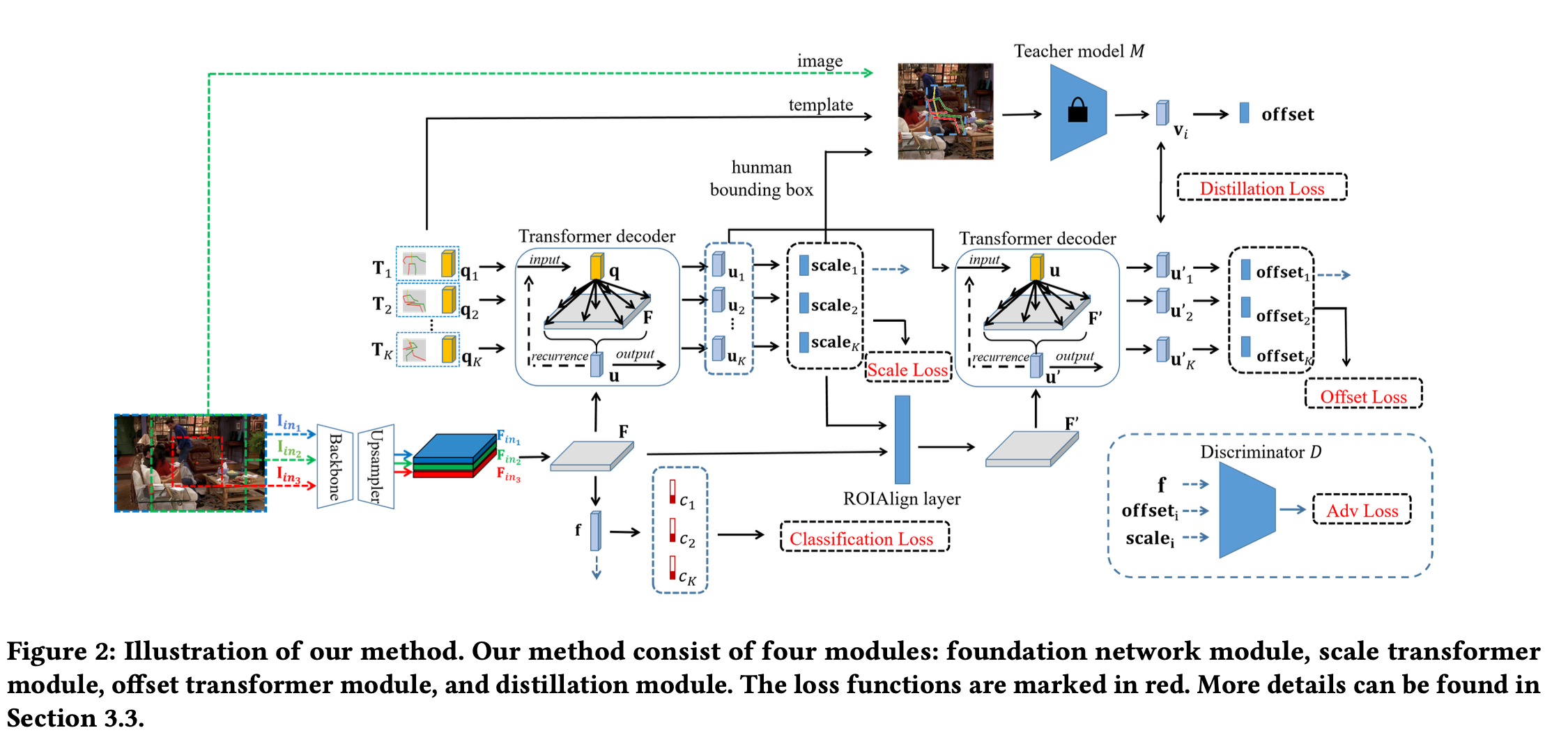
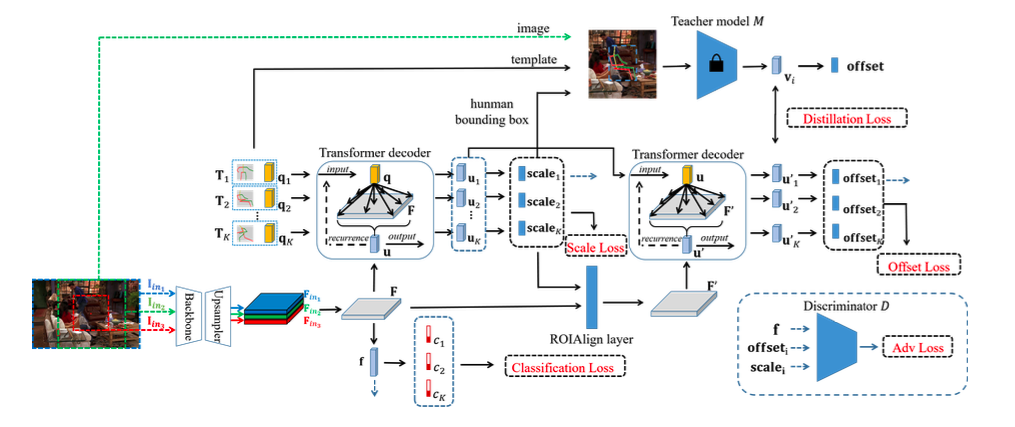
모델은 4개의 모듈로 구성되어 있다.
1. image의 feature map을 생성하고, 각 포즈 템플릿의 compatibility score를 계산하는 foundation module
2. scale transformer module
3. offset transformer module
4. offset regression으로 학습된 distillation module
Foundation network module
foundation network module은 backbone network, upsampling network, classifier로 구성되어 있다.
backbone으로는 Resnet-18을 사용하고, 이것의 아웃풋이 7x7이기 때문에 fine-grained한 context를 담기에는 충분하지 않다고 생각해 upsampling network를 추가하였다. MaskFormer의 pixel decoder처럼, 점진적으로 upsampling을 하고 이 사이즈에 대응되는 backbone network의 feature map을 더해주는 방식이다. 이미지가 3개이기 때문에, feature map도 3개가 나오고, 이 3개의 feature map을 concat하고 1x1 conv layer를 태워 Cx28x28의 feature map()을 만든다. 이후 global average pooling을 태우고 fc layer에 태워 K개의 포즈 템플릿에 대한 binary compatibility score를 아웃풋으로 낸다.
Scale transformer module

foundation network module에서 나온 feature map 와 pose template이 주어지면, 포즈 템플릿과 이미지 사이의 관계를 학습하기 위해 위와 같이 식을 구성한다. 포즈 템플릿의 임베딩을 로 정의, 이것이 query로 들어가고, feature map이 key와 value로 들어간다. transformer module은 3개의 transformer decoder로 구성이 된다. 이후 각각의 에 MLP를 통해 각 포즈 템플릿에 대한 scale을 예측한다.
Offset transformer module

scale을 예측한 후에는, 좀 더 local한 부분을 보며 Offset을 예측해야 하기 때문에, feature map 에서 포즈를 감싸는 박스를 크롭해서 다시 리사이즈를 하여 feature map으로 사용한다. 이때 ROIAlign layer가 사용된다. 이후 앞의 scale transformer module에서 나온 벡터를 query로 하고, 리사이징된 feature map을 key와 vector로 하여 1개의 transformer decoder를 지나고, MLP를 사용해 좌표의 offset을 예측한다.
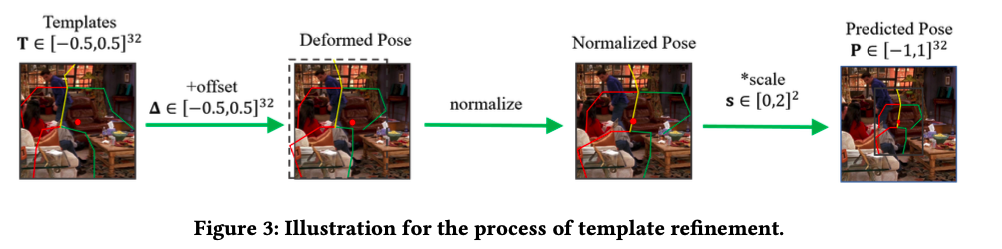
다음은 어떻게 실제 생성 포즈 아웃풋을 얻는지에 대한 설명이다. pose template은 가로 세로 모두 -0.5에서 0.5의 값을 가지도록 normalized 되어 있다. 이후 예측된 offset을 더해주고, 다시 input으로 주었던 위치가 박스의 중앙에 오도록 normalize해준다. 이후 예측된 scale을 곱해줌으로써 포즈를 생성한다.
offset이 너무 커지면 이미지를 완전 넘어서기 때문에 offset의 범위는 -0.5에서 0.5의 값을 가진다. 또한 포즈 높이의 최댓값이 이미지 사이즈의 반이 안되기 때문에 scale은 0에서 2 사이의 값을 가지도록 하였다. 따라서 최종 생성된 포즈는 -1에서 1 사이의 좌표값을 가지게 된다.
Distillation module
offset prediction의 성능 향상을 위해 Distillation module을 구성하였다. teacher model을 만들어 학습에 반영함으로써 탐색 범위를 줄이고 학습 속도를 향상시켰다.
모델은 ResNet-18을 사용하였다. 학습할 때는, 먼저 ground truth scale로 human bounding box를 만들고, ground truth pose template을 박스에 맞춰서 heatmap을 생성한다. 다음, 히트맵과 이미지(원본 이미지의 높이를 한 변으로 가지는 정사각형 패치)를 concat해서 모델에 input으로 넣고, 아웃풋으로 offset vector를 예측하도록 하고 L2 loss를 사용해 학습을 진행한다.
이후 본 모델을 학습할 때는, keypoint heatmap은 그대로 생성하고 scale은 scale transformer module에서 나온 값을 활용한다. 이것들을 인풋으로 넣고 아웃풋으로 나온 feature vector를 offset transformer module에서 나온 vector와 L2 Loss를 계산하여 학습시킨다.
Training with Pose Mining
기존의 Sitcom dataset은 gt pose가 하나밖에 없기 때문에 gt pose template도 하나다. 하지만 상황에 따라 여러 포즈 템플릿이 정답일 수 있기 때문에, self-training을 거친다.
첫 번째 stage는, 각 포즈와 가장 가까운 템플릿을 gt pose template으로 삼고, 학습을 진행한다. 그 후, 만약 이 모델이 각 포즈 템플릿에 대한 compatibility score를 예측했을 때 0.7보다 크다면 그 포즈 또한 positive label로 삼는다. 첫 번째 stage에서 학습할 때 test classification accuracy가 감소하기 시작하면 다음 스테이지로 넘어가고, 더 이상 레이블이 바뀌지 않으면 학습을 중단한다.

Loss로는 위의 Loss를 적용하였다.
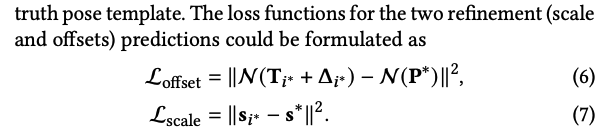
여러 포즈 템플릿이 정답일 수는 있지만, 데이터의 정답 포즈는 하나이기 때문에 scale과 offset에 대해서는 원래의 gt pose template에 대해서만 loss를 계산한다.
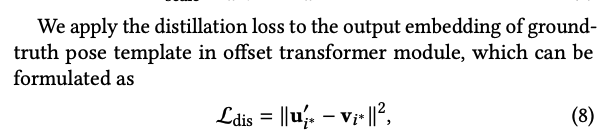
Distillation module을 활용한 학습에도 loss를 적용한다.

gt pose template 말고 다른 positive pose template에 대해서는 adversarial loss를 적용한다. discriminator는 포즈와 스케일, feature를 concat한 를 인풋으로 받고 인풋이 ground-truth template에서 온 것인지를 예측한다.
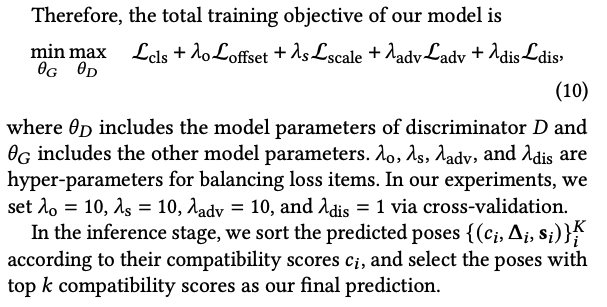
최종적으로는 위와 같이 loss가 구성된다. inference할 때는 compatibility score 순으로 정렬한 후, 가장 높은 k개의 포즈를 결과로 삼는다.
Experiments
Dataset
Sitcom dataset을 그대로 사용한다. test dataset으로는 Friends에서 나온 데이터를 사용한다.
Evaluation
세 가지 Metric을 사용하는데, PCK, MSE, 그리고 user study이다.
PCK는 pose estimation에서 사용하는 metric으로, 알맞게 예측된 포즈 keypoint 비율을 나타낸다. PCK@0.2를 사용했으며, 이는 keypoint가 적정 범위로 들어왔는지 판단하는 threshold가 torso diameter(왼쪽 엉덩이에서 오른쪽 어깨까지의 거리)의 20프로라는 것을 말한다.
MSE는 단순하게 예측된 포즈와 정답 포즈 사이의 거리이다. 이때 이미지의 높이로 나눈 정규화된 좌표로 계산을 한다.
user study는 50명의 평가자를 대상으로 어떤 포즈가 더 자연스러운가를 판단한다.
Implementation Details
backbone으로는 ResNet-18을 사용했고, transformer module은 MaskFormer것을 참고했다고 한다. 다른 파라미터들도 잘 나와있다.
Qualitative Analyses
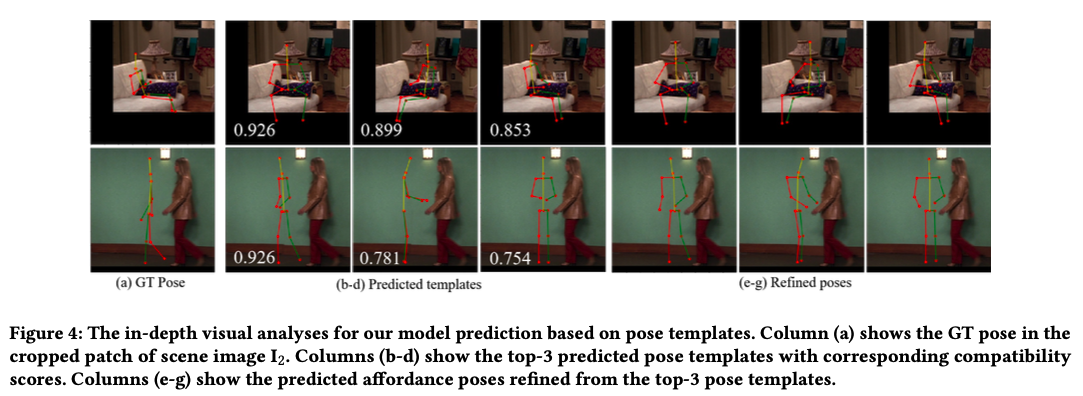
실제 추론 결과이다. 포즈 템플릿도 잘 선정했고, refinement도 잘 적용되었다.
Comparison with Prior Works
Baseline Setting
여러 비교군을 설정한다.
1. Pose Heatmap 모델
2. Pose Keypoint Regression 모델
3. VAE(Binge Watching에서 사용한 모델)
4. UniPose와 PPTR(pose estimation model)
5. PlaceNet과 GracoNet(object placement task에서 sota 모델)
image feature map을 뽑을 때는 다 똑같은 backbone을 사용했다고 한다.
Quantitative Comparison
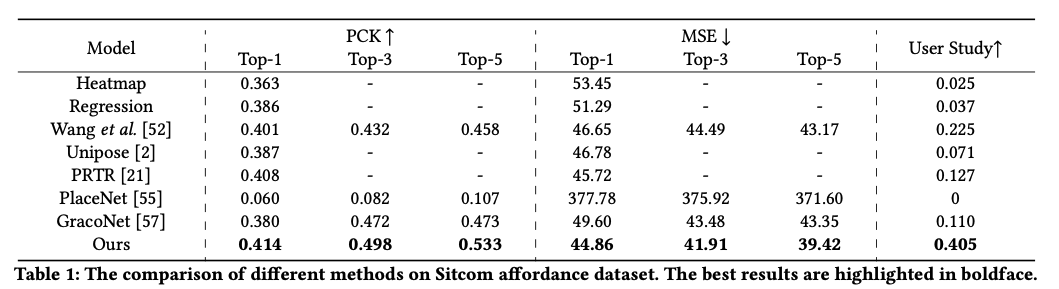
성능은 위와 같다.
Qualitative Comparison

실제 추론 결과 비교이다.
Pose Template Analyses

은 K-means로, 는 직접 선택한 것이다. K-means보다는 직접 보고 선택한 것이, 그리고 K가 너무 크거나 작으면 안 되고 적당한 것이 가장 성능이 잘 나왔고, 그것이 K=14이다.
Ablation Study
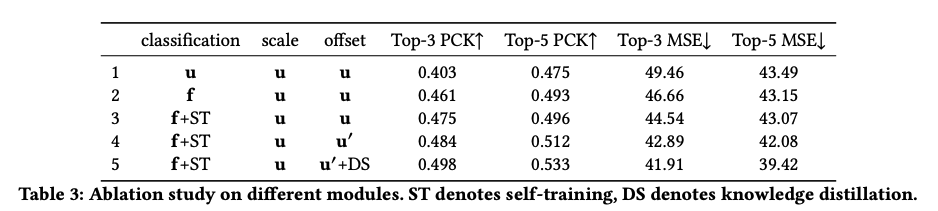
다양한 방법론을 적용한 ablation study이다. 는 transformer, 는 feature map, 는 self-training, 는 ROIAlingn layer, 는 distillation module이다.
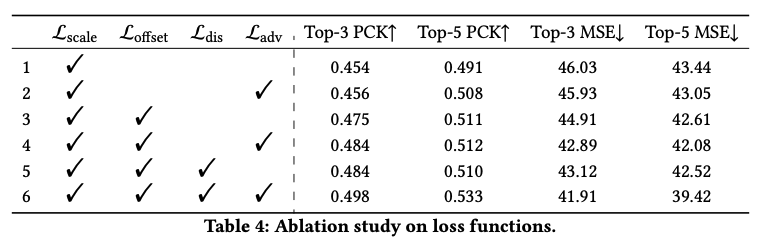
Loss에 대한 Ablation study이다.
Appendix에도 재밌는 것들이 많다.
Conclusion
transformer based end-to-end trainable framework를 제안했고, distilation module을 통해 offset 학습의 성능을 높였다.
후기
오늘은 Transformer 기반의 포즈 생성 모델을 다룬 논문을 읽어보았다. 첨에 봤을 때는 상당히 복잡해보였는데, 찬찬히 읽어보고 나니 조금은 실마리가 풀린 것 같다. 성능을 높이기 위해 다양한 방법론을 적용한 점이 인상깊었고, 그 부분들이 매우 재밌었다. self-training이나 distillation module을 적용한 점이 특히 그랬다. Binge Watching 논문과는 다르게 PCK와 MSE를 평가 지표에 반영하여 실제 포즈까지 예측을 잘하는지 확인해본 점도 좋았다.
아마 당분간은 띄엄띄엄 리뷰를 작성하거나 시험 기간 동안에는 아예 안할 수도 있긴 한데, 아무튼 시험 끝나고 다시 돌아와서 예전에 했던 것처럼 꼭 읽어봐야할 논문들을 리뷰할 예정이다.
