오늘은 Putting Humans in a Scene: Learning Affordance in 3D Indoor Environments에 대한 간단하지 않은 리뷰이다.
3D Pose Synthesis
3D 장면에서의 데이터를 모으는 것은 꽤나 힘들기 때문에, 합성을 통해 실내 3D 데이터를 생성한다. 이때 정확성을 보장하기 위해 두 가지를 고려한다.
1. semantic plausibility: 사람의 포즈가 자연스러운가
2. physical correctness: 물리적으로 가능한가
첫 번째 조건을 위해 2D human pose generative model을 만들고, 이 모델에서 생성된 포즈를 카메라 파라미터에 따라 3D 장면에 매핑한다. 그 다음 두 번째 조건을 만족시키기 위해 새로운 방식을 적용한다.
이를 통해 150만장의 이미지를 생성했다고 한다.
Affordance Predictino in 2D Scene Images
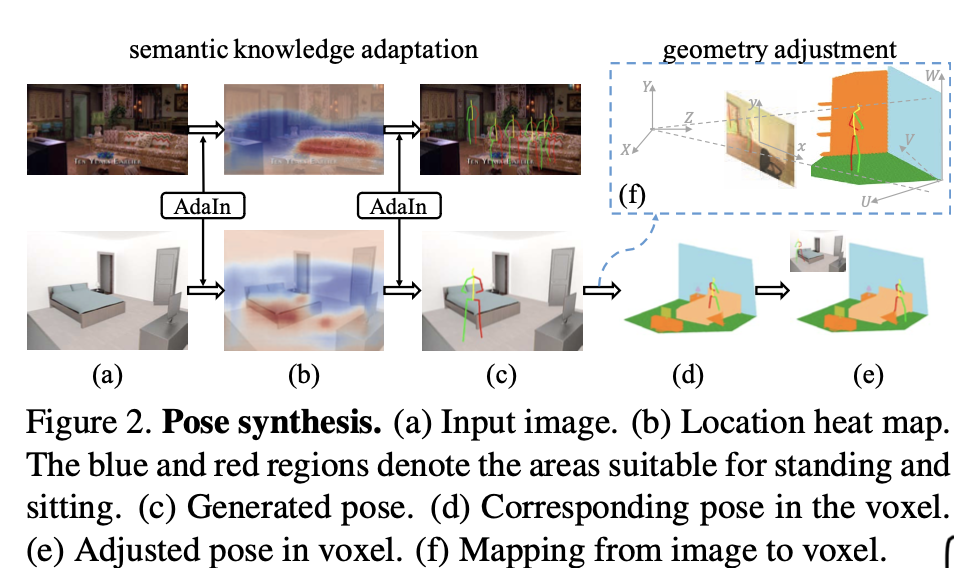
먼저 Binge Watching: Scaling Affordance Learning from Sitcoms 논문에서 사용된 데이터셋으로 pose prediction model을 학습시키고, 이 모델로 SUNCG(3D 합성 실내 이미지 데이터셋)에서 추론을 시행하여 포즈를 생성한다.
각 포즈의 위치는 포즈의 골반 위치로 설정하고, pose prediction model은 이미지를 입력으로 받아 pixel-wise probability map을 추론하는 것으로 포즈를 생성한다. 기존 시트콤 데이터셋은 포즈가 띄엄띄엄있기 때문에, 골반 위치 하나로 하기에는 데이터가 적어서 골반 위치 기준으로 정사각형의 패치만큼 augmentation함으로써 데이터를 늘렸다. 그래서 이 데이터로 학습을 진행하고, pose prediction model은 이미지를 입력으로 받아서 의 히트맵을 출력으로 내놓는다. 이때 31은 기존의 포즈 클러스터 30개 + 배경 1개 해서 classification을 수행하는 것이다.
하지만 생성해야 되는 포즈는 3D이기 때문에 기존 시트콤 데이터셋의 2D 포즈를 Human3.6 dataset의 포즈로 매핑하는 작업을 거친다. 이때 Domain adaption도 적용한다. (Appendix 참고)
Mapping Poses into 3D Scenes
3D world로 매핑을 할 때는 depth와 카메라 파라미터가 필요하다.


따라서 위와 같은 방법을 사용해 depth를 추정한다. 자세한 것은 Appendix에 나와 있다고 한다.
Affordance Constraint in the 3D World
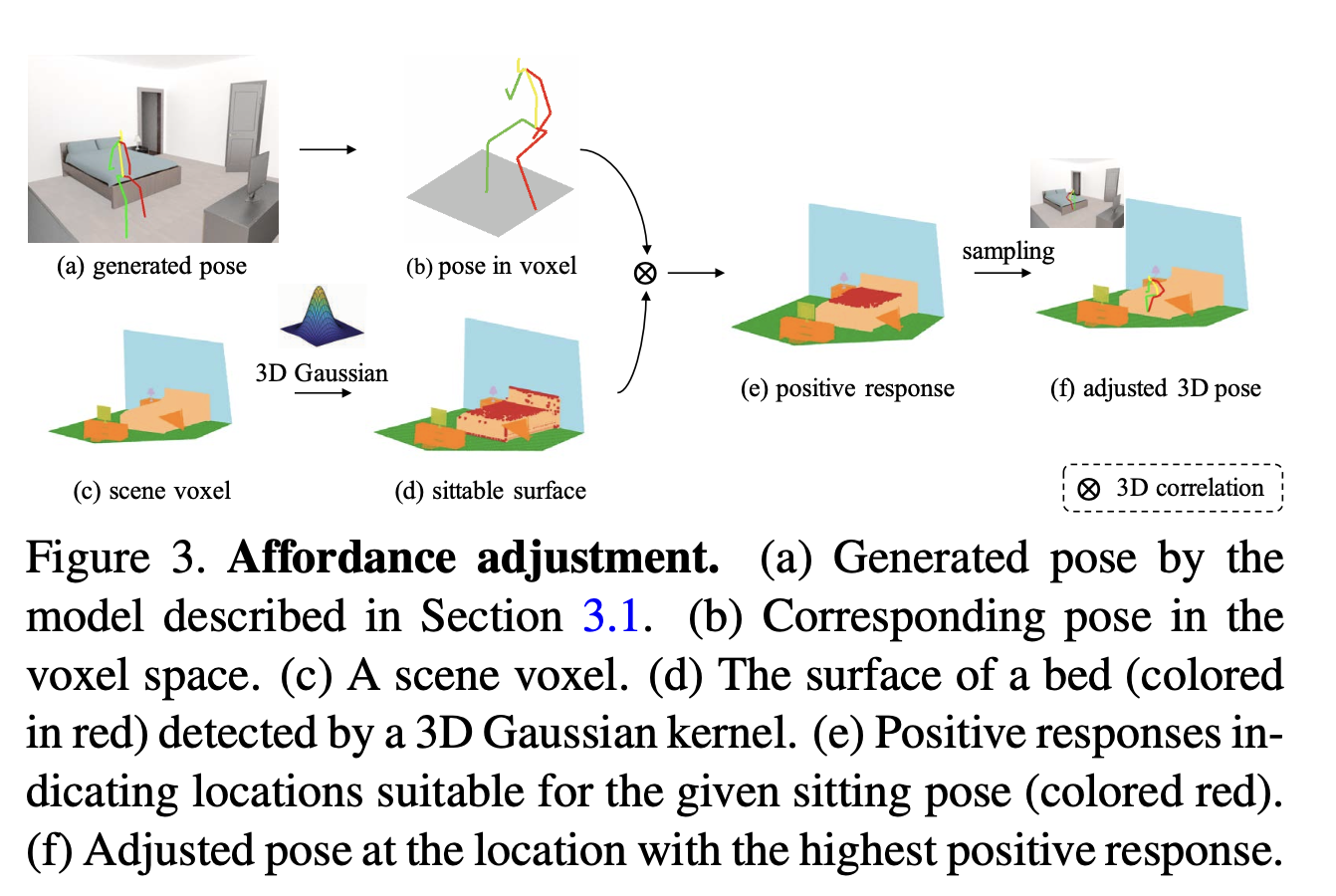
생성된 포즈는 아무리 3D에 매핑했다고 해도, 2D 포즈에서 시작했기 때문에 물리적으로 이상할 수도 있다. 그래서 free space constarint와 support constraint를 넣어 보정을 해준다.
Free space constraint

free space constraint는 어떤 사람의 몸 부위도 어떤 객체와 intersect할 수 없다는 것이다. 이것을 만족하기 위해서, 위와 같은 식을 구성하여 threshold보다 낮으면 만족하는 것으로 판단한다.
또한 서있는 것과 앉아있는 것은 어쩔 수 없는 접촉이기 때문에, 이것들은 예외로 처리한다.
Support constraint
support constraint는 사람의 포즈가 물체의 표면에 의해 지지되어 있어야 한다는 것이다. 예를 들면 바닥 위에 서있거나, 침대 위에 앉아있거나 하는 것들이다. 이러한 장소를 찾기 위해 두 가지 correlation을 적용하는데, 첫 번째는 이미지와 3D Gaussisan kernel 사이에 적용하여 affordable object의 표면을 찾는 것이다. 이후 사람이 있을 만한 표면들만 걸러내고, 두 번째 correlation으로 사람의 포즈와 물체의 표면 사이를 고려하여 아래와 같은 식을 만든다.

위의 가 특정 threshold를 넘어야지만 적정한 포즈로 결정된다.
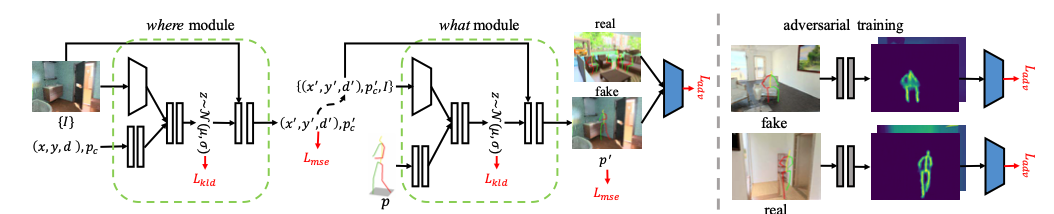
3D Affordance Generative Model
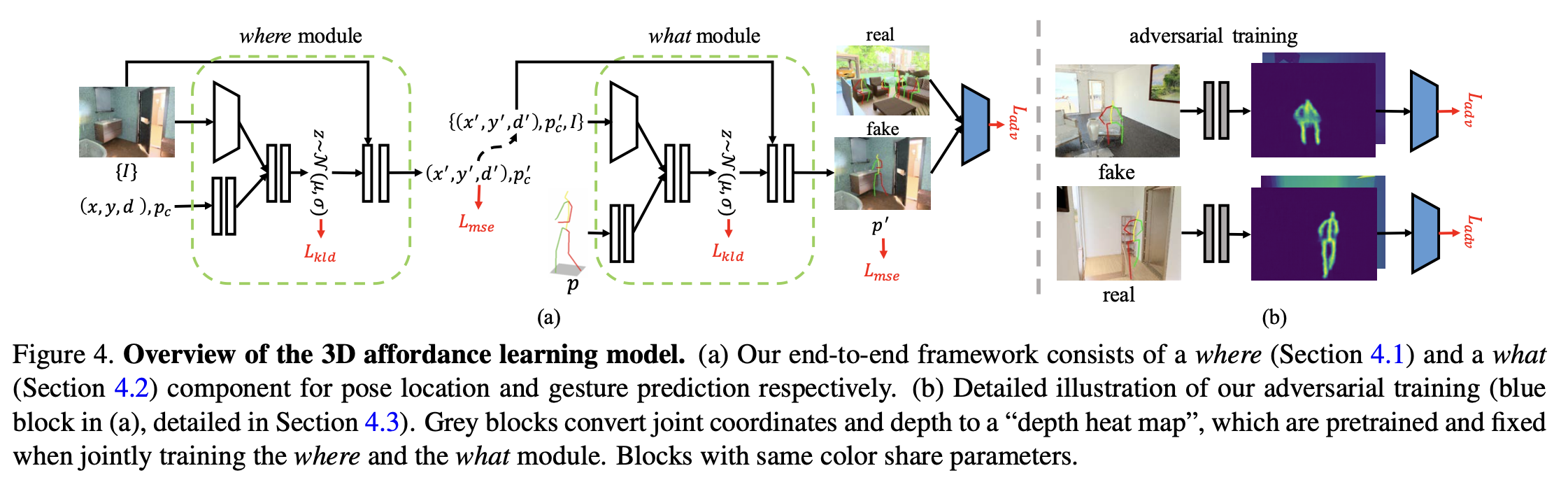
전체 구조는 위와 같다. 먼저 사람이 있을 만한 위치를 예측하고, 어떤 포즈가 어울릴지를 예측한다. 이후 따로 학습시킨 discriminator model을 활용해 더 현실적인 포즈를 생성할 수 있도록 한다.
위치를 예측하는 where module과 포즈를 예측하는 what module을 디자인할 때 두 가지를 고려했는데, 첫번째는 두 모델이 scene을 잘 이해하고 있어야 한다는 것이고, 그렇기 때문에 이미지를 input으로 받는 conditional VAE로 모델을 구성하였다. 두 번째는 두 모델이 3D 공간을 이해해서 물리적으로 가능한 포즈를 생성해야 하는데, 이를 위해 geometry-aware discriminator를 구성해서 학습에 반영함으로써 3D 환경에서의 geometric한 특성도 모델이 배워서 적절한 포즈를 생성할 수 있도록 하였다.
The Where Module: Pose Locations Prediction
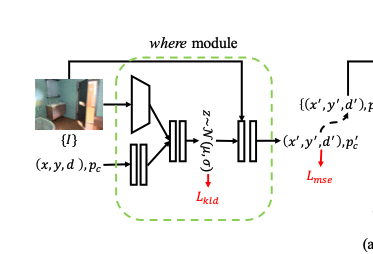
사람이 있을만한 위치와 depth, 그리고 포즈 클레스를 예측한다. 이전 연구에서는 one-hot vector로 포즈 클래스를 예측하지만, 본 논문에서는 클러스터 중심 간에도 비슷한 포즈가 있기 때문에 아예 포즈 자체를 예측하도록 하였다. 따라서 포즈가 3x17의 크기로 아웃풋이 나오게 된다.
The structure of the where module
encoder에서는 이미지의 특징을 뽑는데 resnet-18을 사용하고, 위치와 depth, pose class의 feature를 뽑는데 두 개의 fc layer를 사용한다. 각각의 feature는 concat되고 4개의 fc layer를 거쳐 확률분포의 평균과 분산을 에측한다. decoder는 latent vector와 encoder에서 사용한 image feature를 받아 위치와 depth, pose class를 예측한다. 이때 위치는 heat map으로 예측하여 Differentiable Spatial to Numerical Transform을 활용해 좌표로 바꿔줬다고 한다.
The objectives of the where module
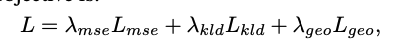
세 개의 Loss를 사용한다.
1. 위치, depth, pose class를 ground truth와 MSE
2. KLD
3. geometry loss: camera parameter를 활용해 포즈 위치에 관해서 Euclidean

where module의 추론 결과는 위와 같다. 빨간색이 서 있는 포즈, 초록색이 앉아 있는 포즈의 위치이다.
The What Module: Pose Gestures Prediction
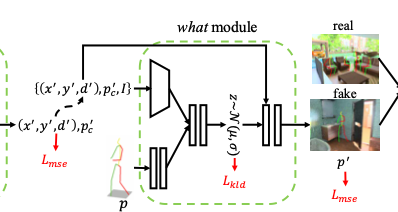
what module은 인풋으로 where module에서 예측했던 위치와 depth, 포즈 클래스와 이미지를 받아 각 pose keypoint의 정확한 좌표를 예측한다. 즉, 이미지의 context를 학습하는 것으로 볼 수 있다.
The structure and objectives of the what module
where module과 매우 유사하다. 인풋과 아웃풋이 달라졌고, loss는 똑같다.
The Geometry-Aware Discriminator
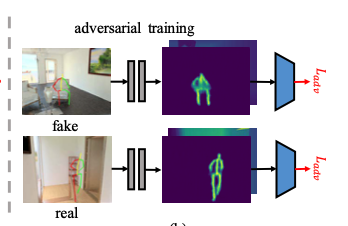
그 장면의 물리적인 법칙을 따르는 포즈를 생성하기 위해서 geometry-aware discriminator를 학습시킨다.
생성된 포즈와 이미지를 입력으로 받고 geometrically feasible한지 하지 않은지 분류하는 것을 학습한다. 이때 이산적인 좌표만 보고 판단하기에는 어려울 수 있기 때문에, 먼저 좌표를 depth heatmap으로 바꾸는 모델을 학습시킨다. 자세한 것은 appendix에 있다고 한다. 이후 이 heatmap을 인풋으로 받는 discriminator를 학습시킨다.

Loss는 위와 같이 adversarial loss를 사용하였다.
Experiment Results
Dataset Synthesis and Evaluation Metrics
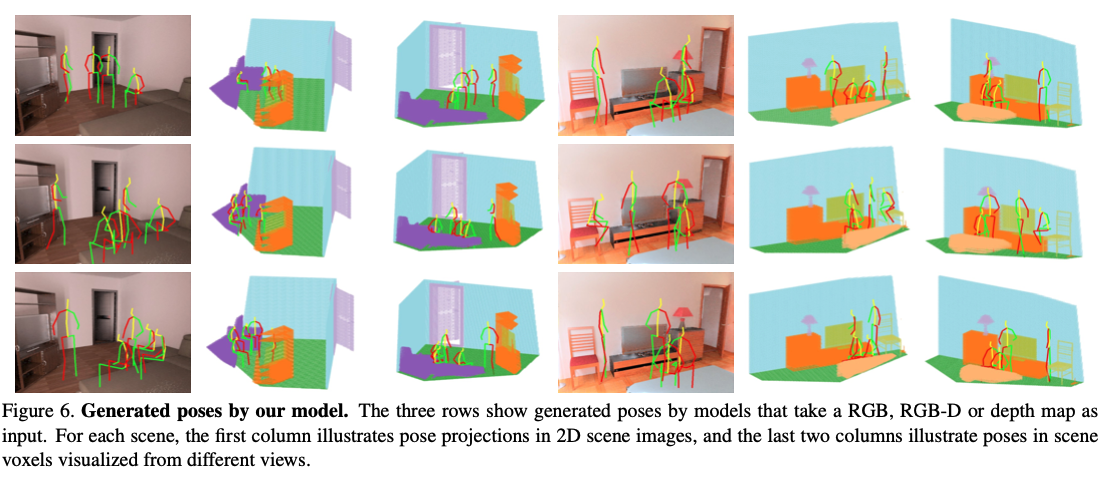
본 논문에서 구성한 방식으로 생성된 3D 데이터이다.
평가 기준은 두 가지이다.
첫 번째는 pose authenticity classifier를 학습시켜 생성된 포즈가 적절한지 판단하는 것이다. 이 모델은 생성된 데이터에서 positive sample을 얻고, negative sample을 임의로 만든다.

negative sample은 위와 같다. 이렇게 모델은 학습시켜서 포즈가 적절한지 판단하는 것이다. 데이터로 학습시키고 테스트했을 때 86프로의 정확도를 얻었고, 이제 평가에 사용될 준비가 되었다.

두 번째는 user study로, 어떤 포즈가 적절한지 사람들이 선택하게 하는 것이다.
마지막으로, 생성된 포즈가 geometric rule을 해치지 않는지 확인하기 위해, 포즈가 일전에 언급되었던 free space constraint와 support constraint를 만족하는지 확인한다.
3D Affordance Prediction

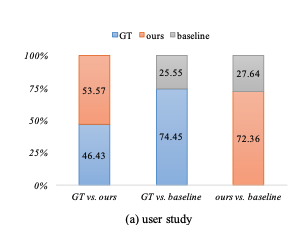
성능은 위와 같다.
Comparison with State-of-the-Art
이전 논문의 모델과 비교를 한다. 이를 위해 이전 논문의 모델을 생성된 데이터에 학습을 시킨다.
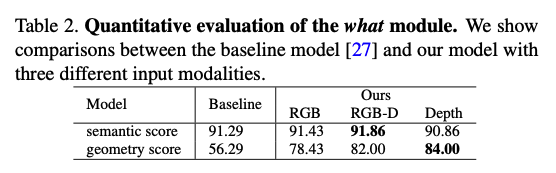
성능은 위와 같이 나왔다.

또한 본 논문의 모델에서 pose class를 떼고 학습시킨 후 inference를 했을 때, 위치에 따라 포즈의 크기와 모양이 달라지는 것을 확인할 수 있다. 즉, 3D의 환경을 잘 이해하고 있는 것이다.
Failure Cases

두 가지 종류의 실패 케이스가 있었는데, 첫 번째는 scene context를 잘 이해하지 못한 것이고, 두 번째는 geometric rule을 이해하지 못한 것이었다.
Conclusion
사람의 포즈가 어디에(where) 그리고 무슨 포즈가(what) 와야 하는지 실내 3D 공간에서 예측할 수 있는 모델을 제안하였다. 또한 2D 데이터인 시트콤 데이터셋에서 학습한 모델을 가지고 3D 데이터를 만드는 방법론을 제시하였다. 성능도 준수하다.
후기
오늘은 이전 논문에 이어서 Affordance learning 관련한 논문을 살펴보았다. 이번에는 3D 환경이다. 3D는 처음이라 이해가 쉽지 않았고, 지금도 잘 이해했는지는 모르겠지만, 3D도 3D만의 매력이 있는 것 같다. 2D 데이터로 학습한 모델로 3D 데이터를 직접 생성한 것이 매우 인상적이었고, adversarial loss를 사용하여 성능을 향상시킨 점도 재밌었다. 테스트할 때도 테스트를 위한 새로운 classification 모델을 학습시킨 것도 대단했다. 얻어가는 점이 많은 논문이었다.
다음 논문은 2D에서의 affordance learning이고 첫 번째 논문과 똑같은 task지만, transformer를 곁들인, 작년에 나온 따끈따끈한 논문이다.
