오늘은 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (SPP-Net)에 대한 간단한 리뷰이다.
Deep Networks with spatial pyramid pooling
Convolutional Layers and Feature Maps
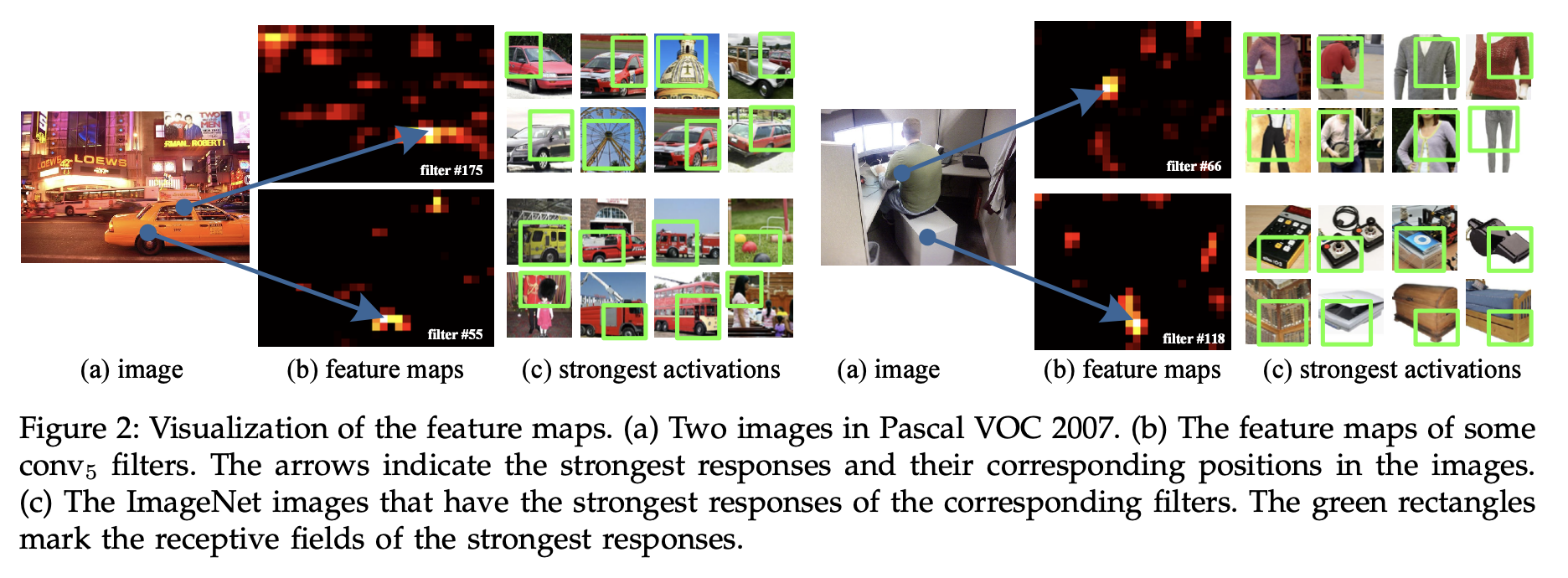
기존의 CNN 모델은 뒤쪽에 있는 fc layer 때문에 고정된 이미지 사이즈를 받아야 했다. conv layer는 feature map을 추출하는 역할을 하며, 위와 같이 이미지의 특징적인 부분을 뽑아내고, input의 사이즈에 구애받지 않는다.
The Spatial Pyramid Pooling Layer
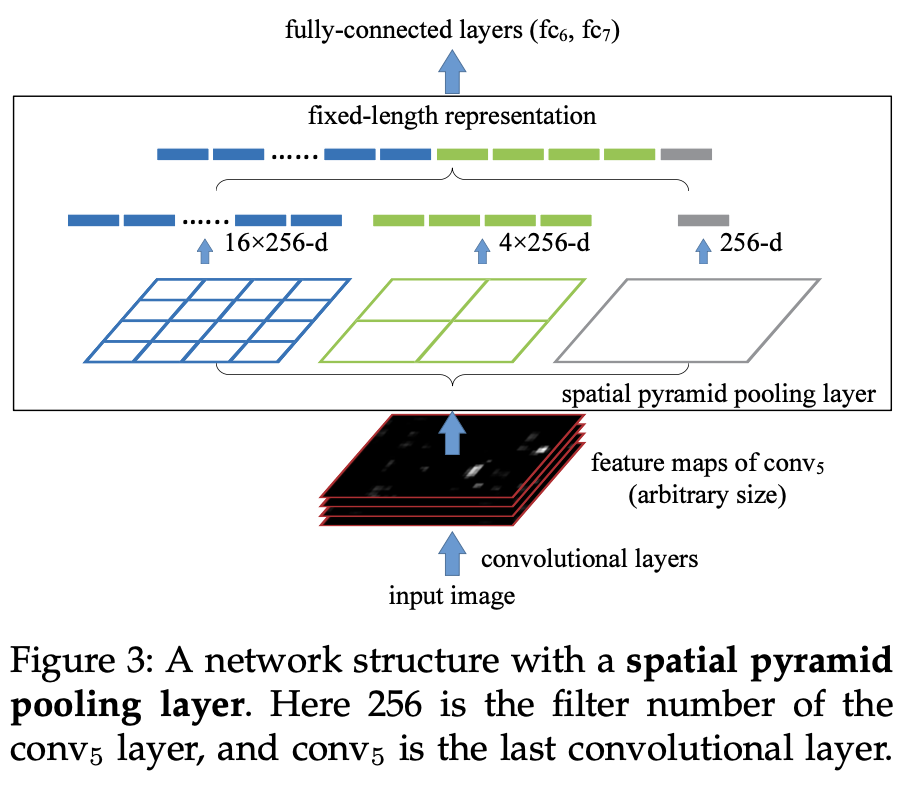
Spatial Pyramid Pooling을 제안하여 input size와 비율에 구애받지 않고 고정된 크기의 feature map을 뽑을 수 있게 한다. 이렇게 함으로써 사이즈가 다른 이미지를 같은 네트워크에 넣을 수 있게 되고, 이는 다양한 scale의 이미지를 보고 판별할 수 있게 되어 성능의 향상을 가져온다.
Training the Network
224x224와 180x180 두 크기의 이미지로 학습을 시켜 multi-size training을 진행하였다.
SPP-Net for Image Classification
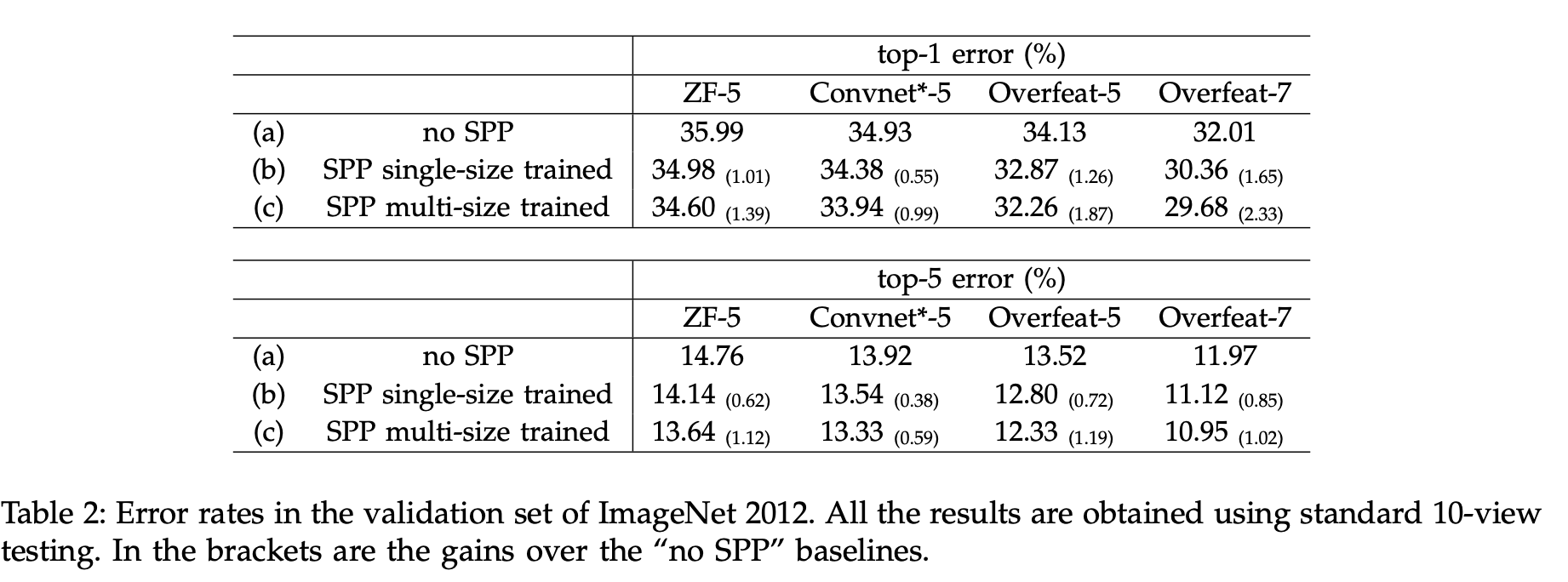
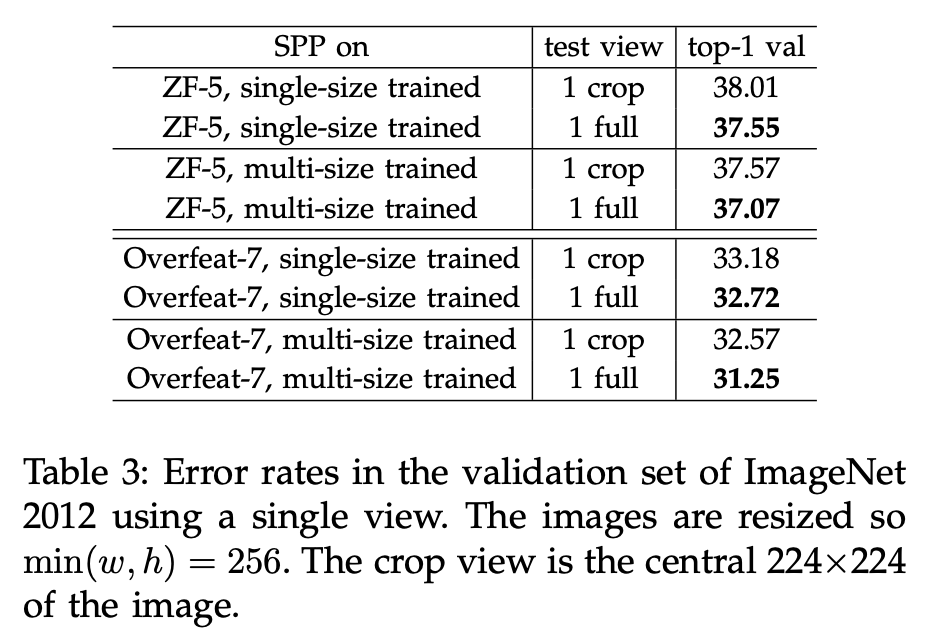
Image Classification task에서 학습시켜보면서, multi-level pooling과 multi-scale training, 그리고 full-image로 학습을 하는 것이 성능을 높여준다는 것을 확인하였다.
VOC 2007과 Caltech 101로 테스트한 결과도 나와 있다.
SPP-Net For Object Detection
Detection Algorithm
먼저 selective search를 통해 약 2000개의 candidate window를 뽑아낸다. 이후 전체 이미지에서 feature map을 뽑고, 각각의 candidate window에 해당하는 feature를 pooling 할 때 SPP를 사용한다. 이러면 12800 dimension의 feature가 candidate마다 만들어지는데, 이것을 fc layer에 태우고 난 후, SVM classifier를 통해 classification을 수행한다.
Detectino Results
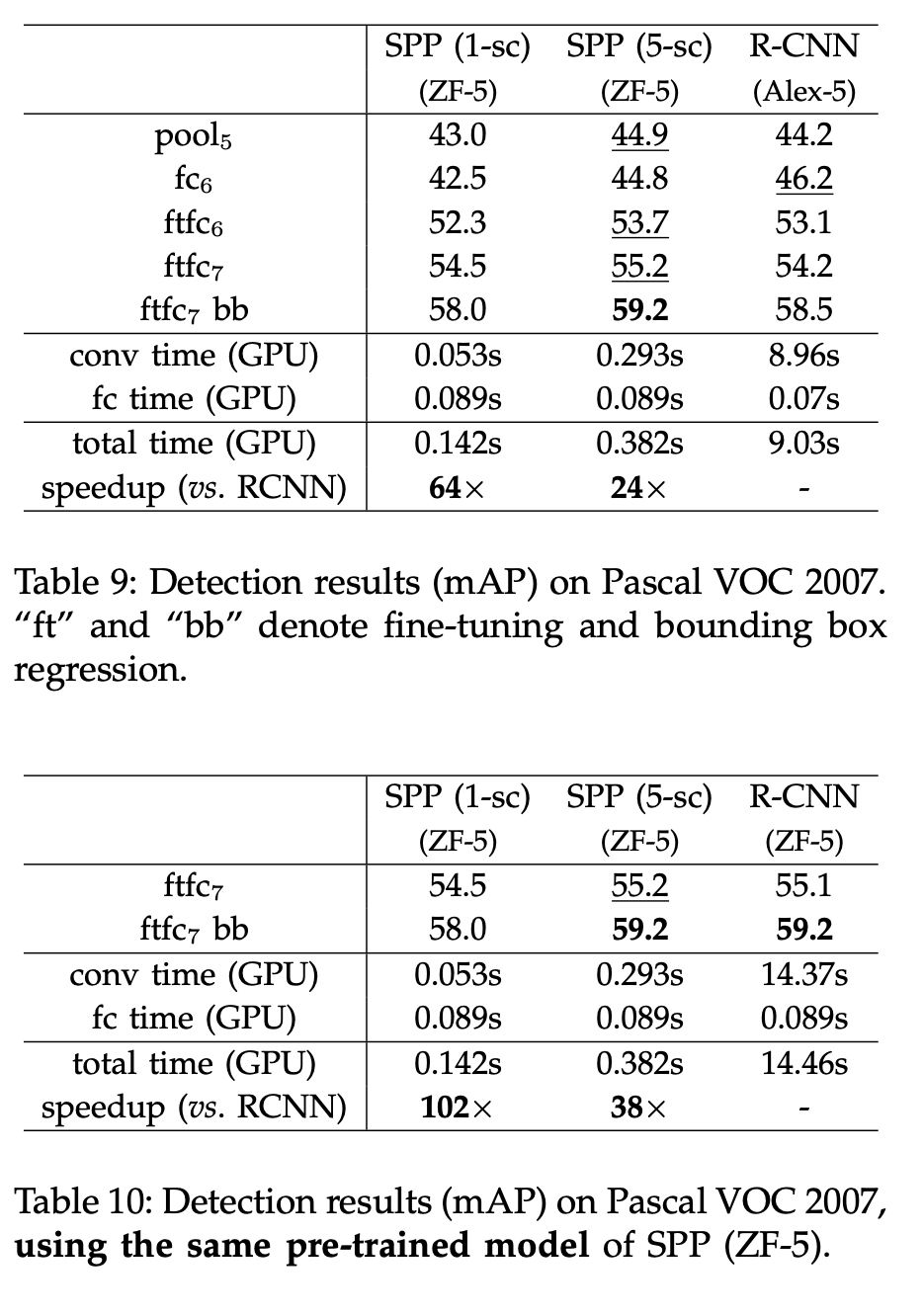
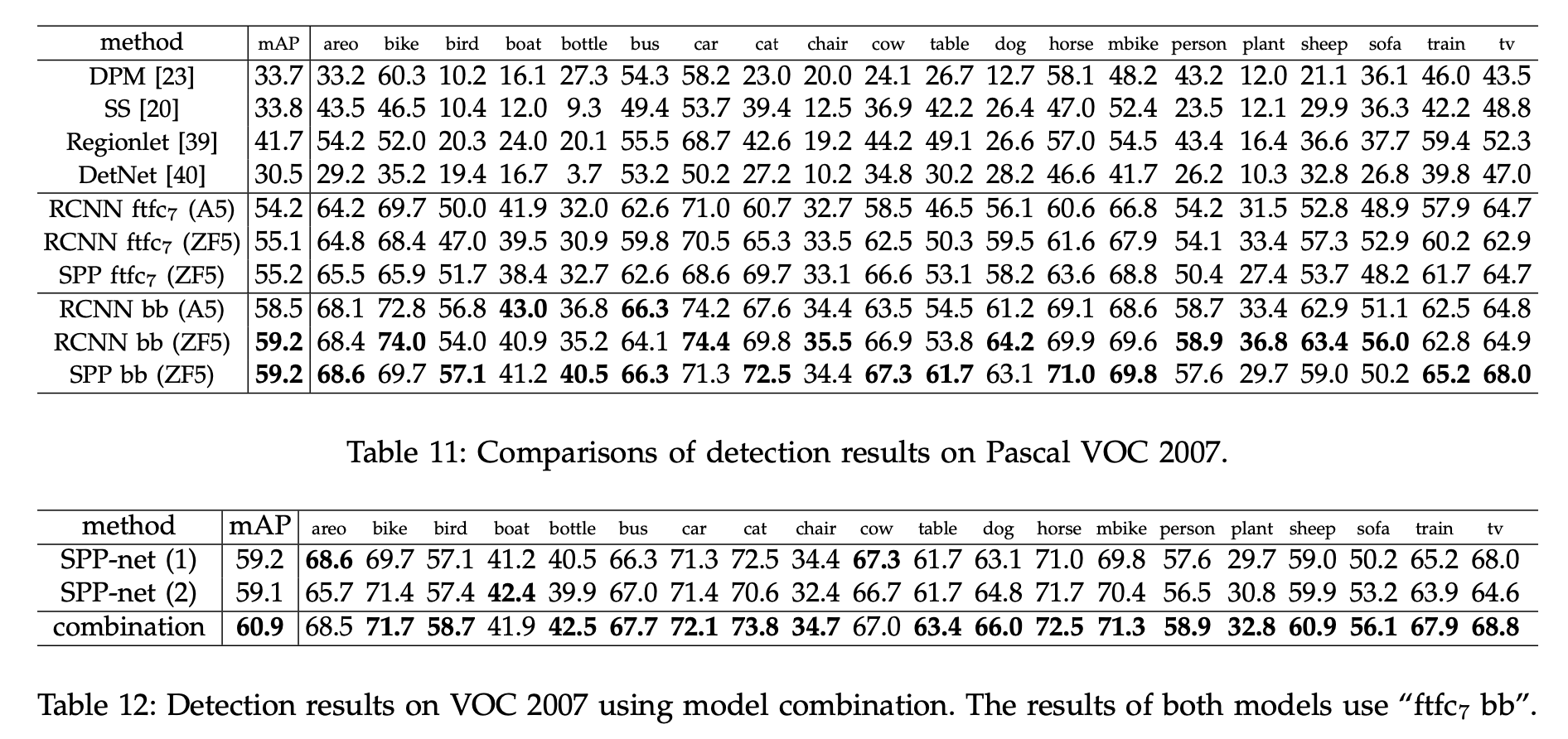
성능와 시간은 위와 같고, 다른 모델과 결합(pretrained ImageNet, bbox regression)을 했을 때도 성능이 향상된 것을 확인할 수 있다.
후기
오늘은 SPP-Net에 대해 알아보았다. 어째 가면 갈수록 리뷰가 짧아지는 느낌인데, 반성해야될 부분이다. 다양한 이미지 크기와 비율에도 동일한 아웃풋을 내는 Spatial Pyramid Pooling을 활용한 모델이었고, 성능이 SOTA 급은 아니지만 준수한 성능을 보여줬다. 구도 가이드 모델에도 이 구조가 사용되었던 것을 생각해보면, 여러모로 기여를 많이 한 논문 같다. 다음 모델은 YOLO가 될 것 같은데, 예전에 데모를 한 번 돌려봤을 때 미친듯이 빠른 추론을 보여줬어서 더 기대가 된다.
