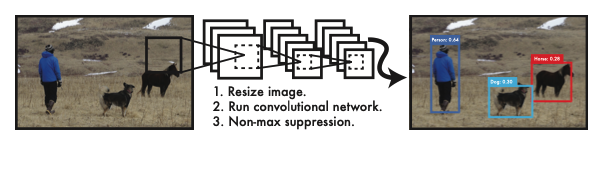
오늘은 You Only Look Once: Unified, Real-Time Object Detection (YOLO v1)에 대한 간단한 리뷰이다.
Unified Detection
bounding box를 예측하기 위해서 전체 이미지의 feautre를 사용하고, 동시에 객체의 클래스까지 예측하여 end-to-end training이 가능하고 속도가 빠르다.
먼저, 이미지를 SxS의 grid로 나눈다. 이때 객체의 중심이 grid cell에 놓이게 되면, 그 grid cell은 'responsible하게 된다. 이후 각각의 grid cell은 B개의 bounding box와 각 박스의 confidence score를 예측한다. 이때 confidence score는 로 정의된다.또한 C개의 conditional class probabilities를 예측한다. 이때에는 bounding box의 개수에 상관없이 한 세트의 class probabilities를 한 grid cellak마다 예측하게 된다.
Network Design

모델의 구조는 위와 같고, 아웃풋으로 클래스 확률과 bounding box의 좌표를 내뱉는다. 이 아키텍쳐는 GoogLeNet에서 영향을 받았다고 한다. 또한 이 구조에서 layer를 몇 개 제외시켜 속도가 빨라진 Fast YOLO도 같이 실험한다.
Training
먼저 앞단의 conv layer들을 ImageNet에 pre-train한다. 이후 conv layer와 fc layer를 덧붙여서 object detection을 위한 모델로 만들고, 학습을 진행한다.
먼저 박스 좌표 예측과 객체가 없는 box에 대한 confidence score 예측에 대한 loss를 하이퍼파라미터를 통해 조정했고, 큰 박스와 작은 박스가 유사한 loss를 가지는 것을 막기 위해 square root를 취해줌으로써 둘의 차이를 벌렸다.
또한 YOLO는 한 grid cell에 대해서 여러 개의 bounding box를 예측하는데, 학습할 때는 ground truth와 가장 높은 IoU를 가지는 predictor를 resonposible하다고 정의하고, 이것을 loss에 반영한다.

위의 사진이 loss 함수이다.
Inference
98개의 bounding box와 class probabilities를 예측하고, 같은 물체에 대해 여러 번 추론되는 것은 NMS를 통해 소거했다.
Comparison to Other Detection Systems
당대에 사용됐던 Object detection 모델과의 비교가 작성되어 있다. 요약하자면 YOLO는 bounding box regression과 classification을 하나로 합쳤고, selective search를 사용하지 않기 때문에 예측해야 하는 bounding box 개수가 적다. 이에 따라서 속도가 매우 빠르다.
Experiments
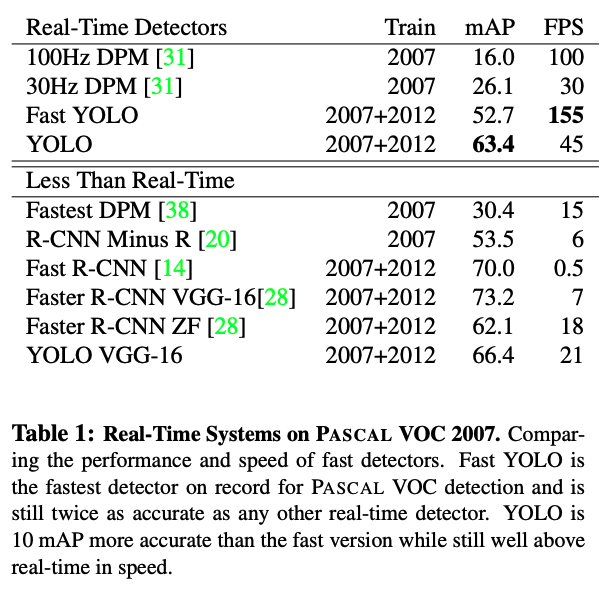
준수한 성능과 미친듯한 FPS를 보여주고 있다.
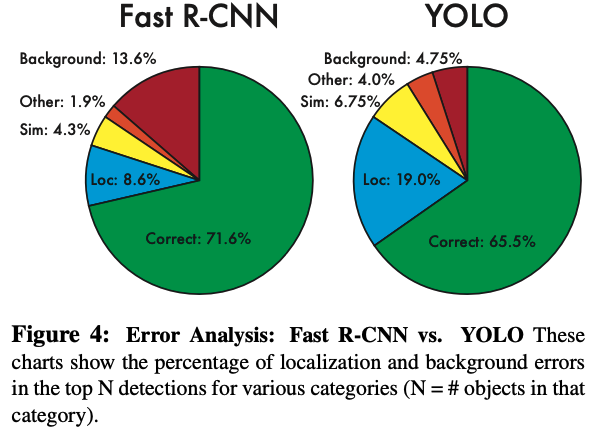
Fast R-CNN과 비교했을 때 localization error는 YOLO가 더 크지만, 실제로 객체가 없는데 있다고 예측하는 오류는 YOLO가 더 작은 것을 확인할 수 있다.
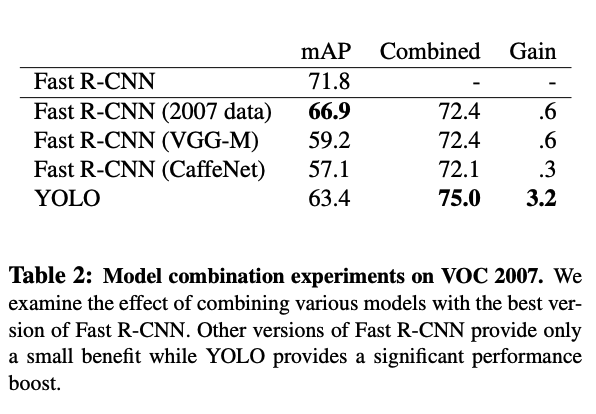
또한 YOLO와 Fast R-CNN을 합쳐서 둘의 단점을 상호보안하도록 구성했을 때도 좋은 성능을 달성할 수 있었다.
후기
속도의 YOLO이다. 이전 기법과는 달리, selective search를 사용하지 않았고, bouding box regression과 classification이 한 모델에 붙어 있어서 end-to-end 학습이 가능하고 속도도 빠른 점이 특징인 모델이었다. 지금 시점으로는 v9까지 나온 걸로 아는데, 기회가 되면 모든 버전을 읽어보고 싶다.
