본 포스트는 LG Aimers 활동에 참여하며 온라인 AI 교육을 정리한 내용입니다!
프로그램에 관심이 있으시다면 https://www.lgaimers.ai/ 를 참고해주세요!!
데이터 처리와 해석 유의점
데이터 처리 및 수집에서 윤리 이슈
1. 데이터에 대한 해석
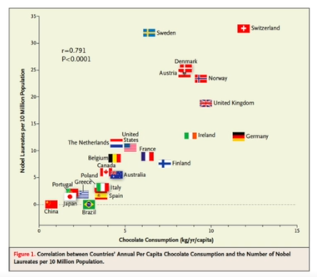
- 상관관계와 인과관계는 다르다.
데이터 전처리와 분석방법은 적절한가
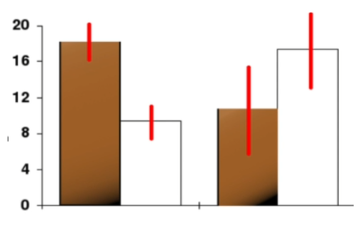
- Error bar 추가하기
- C와 D는 평균은 다르지만 오차범위가 크기 때문에 통계적으로 유의미하지 않다.
- Error bar는 시각적으로 가이드를 주고, 실제 데이터를 해석할 때는 적절한 통계 테스트를 찾아야한다.
- Outlier를 제거해야한다.
- 데이터 표준화하기
- EDA(Exploratory Data Analysis) 충분한 시간을 보내기
학습에 쓰는 데이터가 충분한가
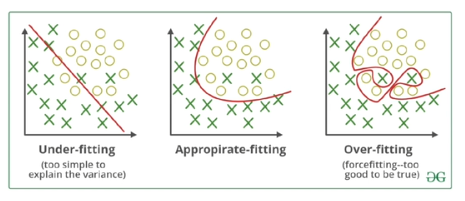
- 인공지능에 쓰이는 데이터는 일반적으로 million 단위의 데이터가 있어야한다.
- 충분한 데이터가 없다면 underfitting이 일어날 수 있다.
- overfitting / underfitting을 유의하여 데이터를 분석해야한다.
- 데이터가 시간에 따라 오차가 생겨도 유연하게 대처할 수 있어야한다.
- training data와 test data가 달라야한다.
Black box algorithm
- decision tree와 같이 설명을 할 수 있는 모델도 존재하지만 과정을 설명할 수 없는 모델도 존재하는데, 이를 "black box model"이라고 부른다.
- black box model과 같이 성능은 좋지만 설명력이 좋지 않은 모델보다 성능은 조금 떨어져도 설명력이 좋은 모델이 실제로 더 많이 사용된다.
- Saliency map, SHAP과 같이 post-hoc explainability를 제공하는 기술이 생긴다.
- High risk 결정에서는 설명력도 정확도 만큼이나 중요해진다.
Handling the Web data
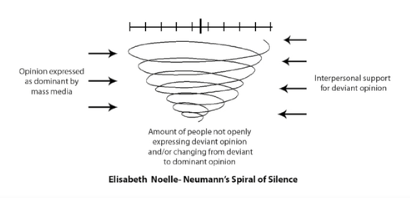
- 의견의 대표성 (Spiral of silence)
- 인터넷 상의 의견이 대표성 있는 의견이 아닐 수 있음을 인지해야 한다.
- 소셜 링크를 통한 빠른 정보 전파, 봇의 참여, 극단화 현상을 주의해야 한다.
- 오정보의 영향도 유의해야한다. 더욱 더 빠른 속도로 편향 현상이 전파될 수 있기 때문이다.
- infodemic : 사실 정보와 더불어 오정보의 양이 늘어 구분이 어려워지는 정보 과부화 현상
- 잊혀질 권리 : 사용된 정보가 기간이 지나도 계속하여 데이터가 남아있는 경우 문제가 된다.
- 검색을 했을 때 결과가 나오지 않게 하는 방식을 생각해봐야한다.
윤리에 대한 법적 제도
- GDPR : EU에서 개인 정보 보호 및 과다 광고에 노출, 혹은 혐오 표현의 노출을 규제하는 플랫폼을 단속하는 법 제도
- Digital Service Act에 대한 규제를 확인을 제대로 해봐야한다.
- 서비스를 넘어 윤리적인 가치에 대해 민감하게 알고 법 제도의 변화를 따라가야 한다.
AI and Ethical Decisions
- 인공지능 알고리즘으로 인한 부작용에 관해 생각해봐야한다.
- 잘못된 분류에 의해 발생하는 편향때문에 잘못된 결과를 내고 사회의 편향을 조장할 수 있기 때문에 유의해야한다.
- 채용, 챗봇 서비스, 판결문 등 여러 부적절한 판결이 있다.
- 알고리즘의 결과들이 우리의 윤리 규범과 잘 맞는지, 상충되지는 않는지 살펴볼 필요가 있다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.