
K2 컴파일러로 가는 길
The road to K2 compiler
24년도 5월, Kotlin 2.0.0의 릴리즈가 출시되었고 이는 K2컴파일러를 지원한다. 기존 컴파일러의 프론트엔드, 백엔드 그리고 K2에서 제공할 New fronted에 대해 설명한다.
What is Compiler?
컴파일러는 소스 코드를 낮은 수준의 기계언어로 변환하는 블랙박스이다.
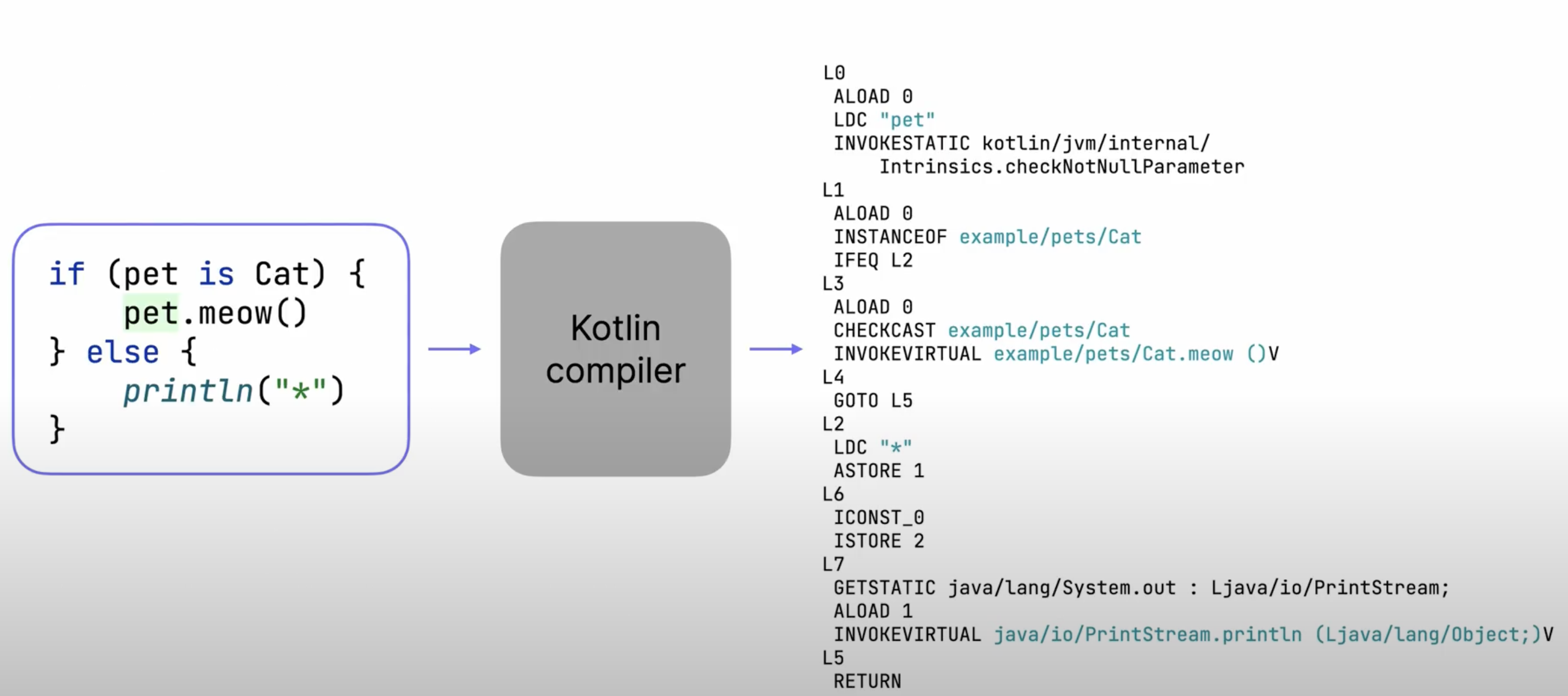
Kotlin의 간단한
if문은 복잡한 자바 바이트코드의goto문으로 변경되게 된다.
위 사진에서 코틀린 컴파일러는 Kotlin 코드를 JVM 바이트 코드로 변환한다. 그러나 여기서 JVM 바이트 코드는 낮은 수준의 기계언어가 아니다. (이는 JVM에 의해 이해 기계 언어로 변환된다)
즉 컴파일러의 정의는 타겟 언어로의 변환이라해도 좋다.
코틀린 컴파일러는 자바 바이트코드로만 변환되는 것이 아니다.
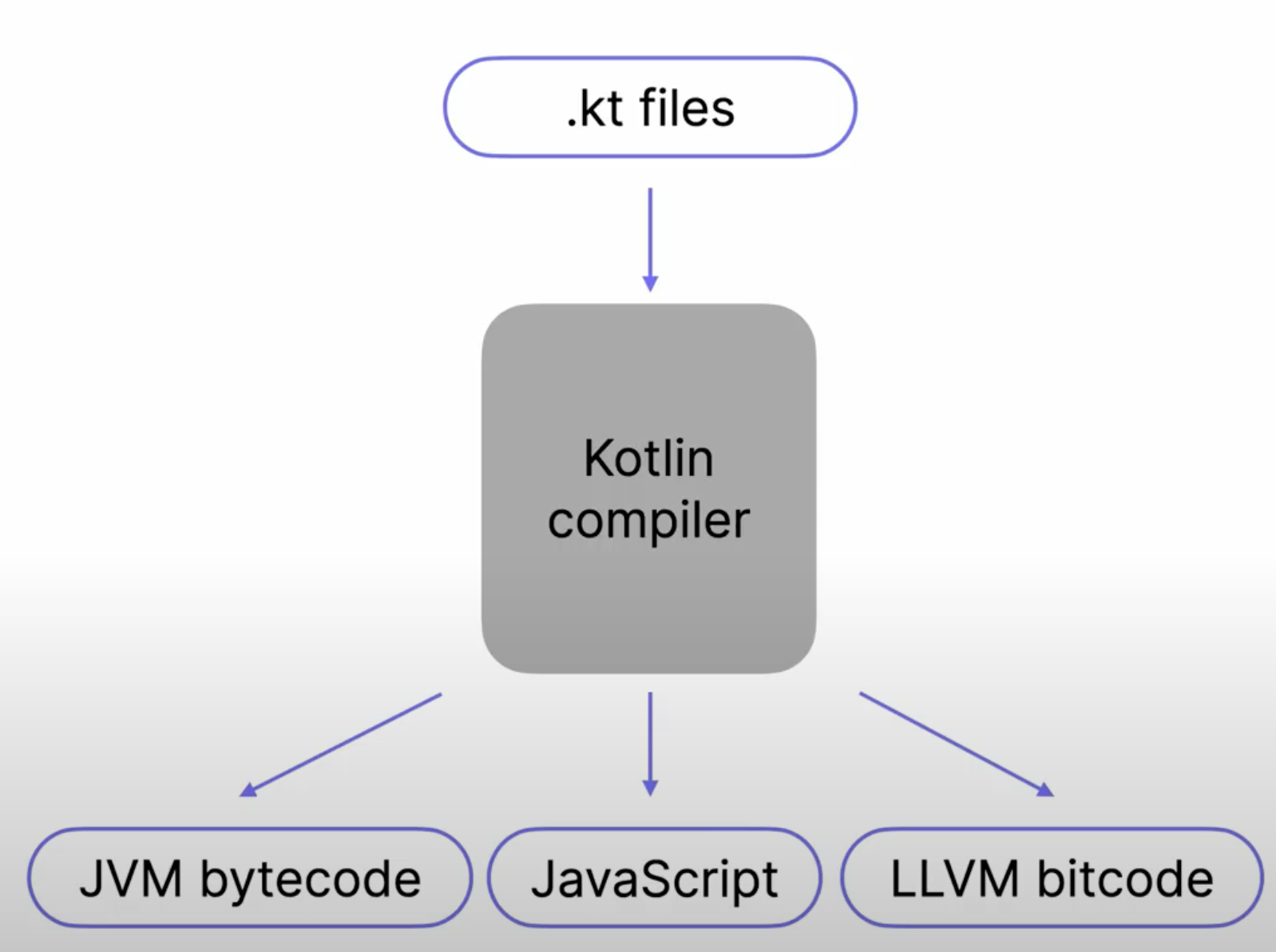
- JVM bytecode
- JavaScript
- LLVM bitcode
등 개발자가 작성한 고급언어를 여러 환경에서 실행될 수 있도록 다양한 형태를 지원한다.
여기서 특이한 점은 JavaScript는 기계언어가 아닌, 개발자가 직접 작성하는 고급언어으로도의 변환도 지원한다는 것이다.
따라서 코틀린 컴파일러는 JVM, JS 및 네이티브(LLVM)으로 3가지 플랫폼으로의 변환을 지원한다는 것만 알고 있으면 될 것 같다.
Compilder 내부를 톺아보자.
컴파일러라는 블랙박스의 내부를 세분화하는 일반적인 방법은 프론트엔드와 백엔드로 나누는 것이다.
어플리케이션 개발의 프론트와 백엔드와는 다른 의미를 가진다.
대표적인 역할로는 아래와 같이 표현할 수 있다.
- 프론트엔드
- 소스코드의 구문, 어휘, 의미를 분석한다.
- 코드 유효성 검사(컴파일 에러가 발생)
- 백엔드에서 바이트코드를 생성하기 위한 syntax tree와 sementic info를 빌드한다.
- 백엔드
- 바이트 코드를 생성한다.
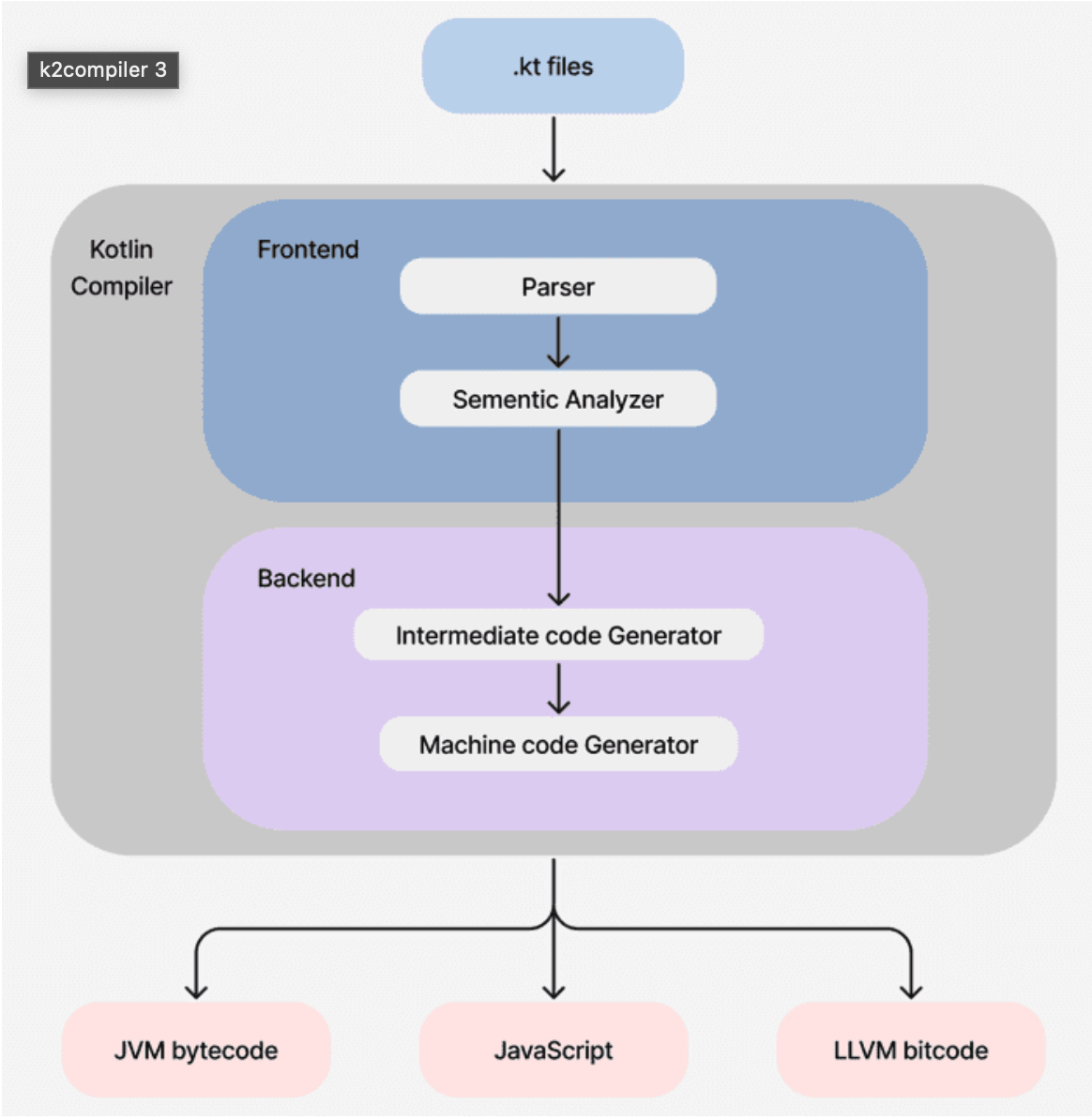
컴파일러의 Kotlin 2.0.0이전, 즉 K2컴파일러 이전의 코틀린 컴파일러는 위와 같은 형태로 작성되게 된다.
- intermediate code Generator & Optimizer은 선택 단계이다.(2.0.0이전) -> 이후 설명
Frontend - Parser
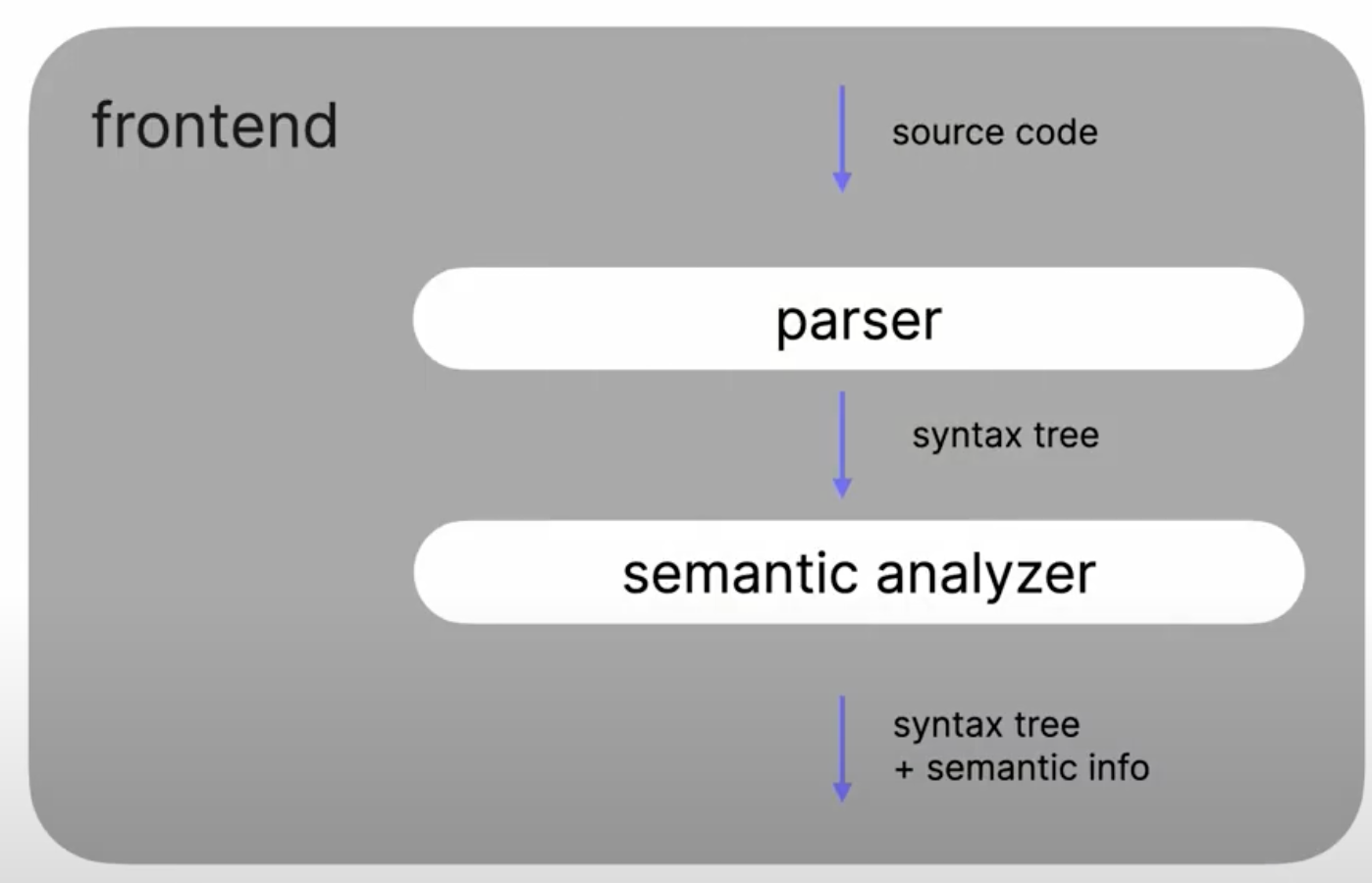
파서는 소스 코드인 Kotlin 파일그룹을 인풋으로 받으며, 소스 코드의 유효성을 체크하고, 문법이 맞으면 구문트리를 빌드한다.
if (pet is Cat) {
pet.meow()
} else {
println("*")
}컴파일러는 위와 같은 코틀린 언어를 이해하기보단 그대로 받아쓰기하듯 문법트리로 변환한다.
- 프로그램 구조를 검사하고 올바른지 확인한다. (괄호가 없거나, 오타등의 정보를 잡는다.)
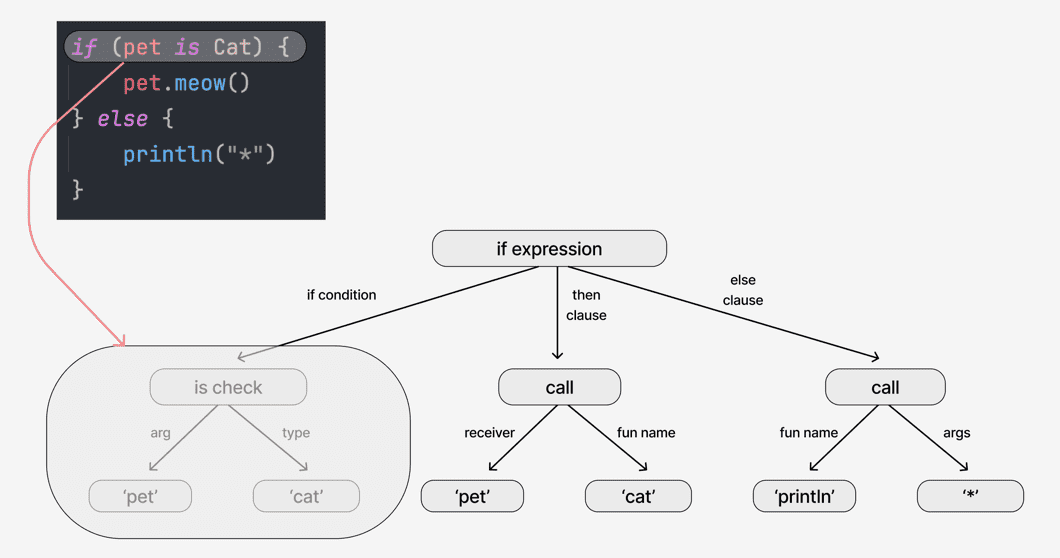
- 위와 같은 코드가 있을때, 다음과 같은 구문 트리(syntax tere)를 만들어낸다.
- 이러한 구문 트리를 PSI(Program structure interface)라고 부른다.
- 문법에 따라 구조만 생성하고, 의미는 부여하지 않는다.
- 문법에 따라 기본 문법 구조를 지정할 뿐, 'pet', 'cat'등의 각각의 노드에 무엇을 저장할 지는 구별하지 않는다.
Frontend - Semantic analyzer
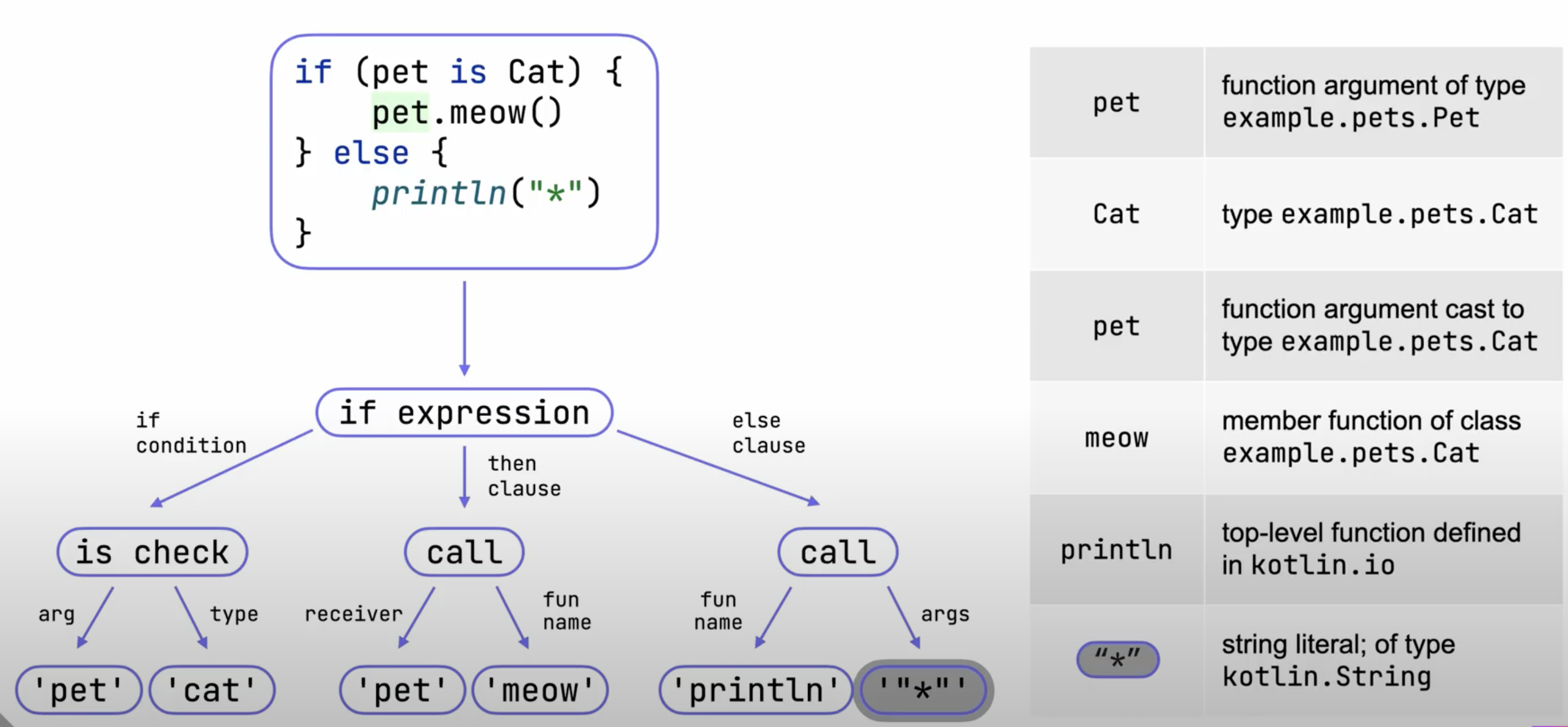
파서로부터 문법트리를 받아 의미정보를 추가한다.
의미정보란?(Sementic info)
코드에 사용된 함수, 변수, 타입에 대한 모든 세부 정보로, 함수의 출처는 어디인가?, 타입은 무엇인가?에 대한 답변이다.
-
함수, 변수, 타입에 대한 세부 정보에 대한 답을 찾는다
- 파라미터로 온 pet에 대한 출처를 추론한다.

- 파라미터로 온 pet에 대한 출처를 추론한다.
-
Semantic analyzer의 컴파일시간의 대부분은 위와 같은 변수에 대한 타입을 추론하는 과정이다.
-
이는 파서와 달리 -> 파라미터의 개수가 안맞거나, 타입이 맞지않거나, 함수를 참조하지 못하거나 등이면 에러를 발생.
if (pet is Cat) {
pet.meow(1) // Error: Too many arguments
} else {
pet.mmeow() // Error: Unresolved reference
}- 파서가 만들어낸 모든 노드에 대한 정보를 찾아, 의미를 추가한다.
- 각 노드에 대한 의미는 맵(Binding Context)에 저장된다
- 아래 그림처럼 생성된 Syntax tree Sementic Info(=binding context)를 백엔드에 넘겨준다
프론트엔드는 초기 구조에 구조와 의미를 더하는 것이다. 이 정보를 활용하여 백엔드에서 타겟코드를 생성하도록 한다.
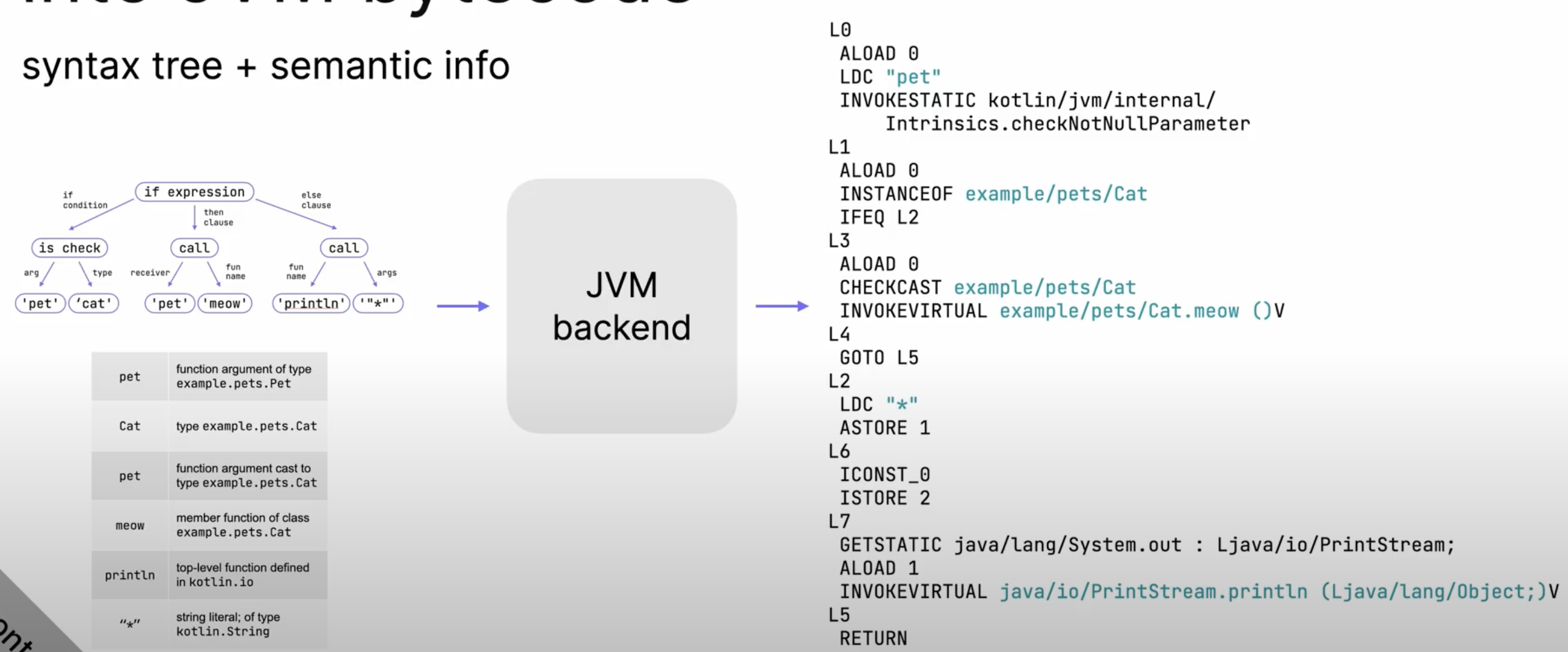
Backend
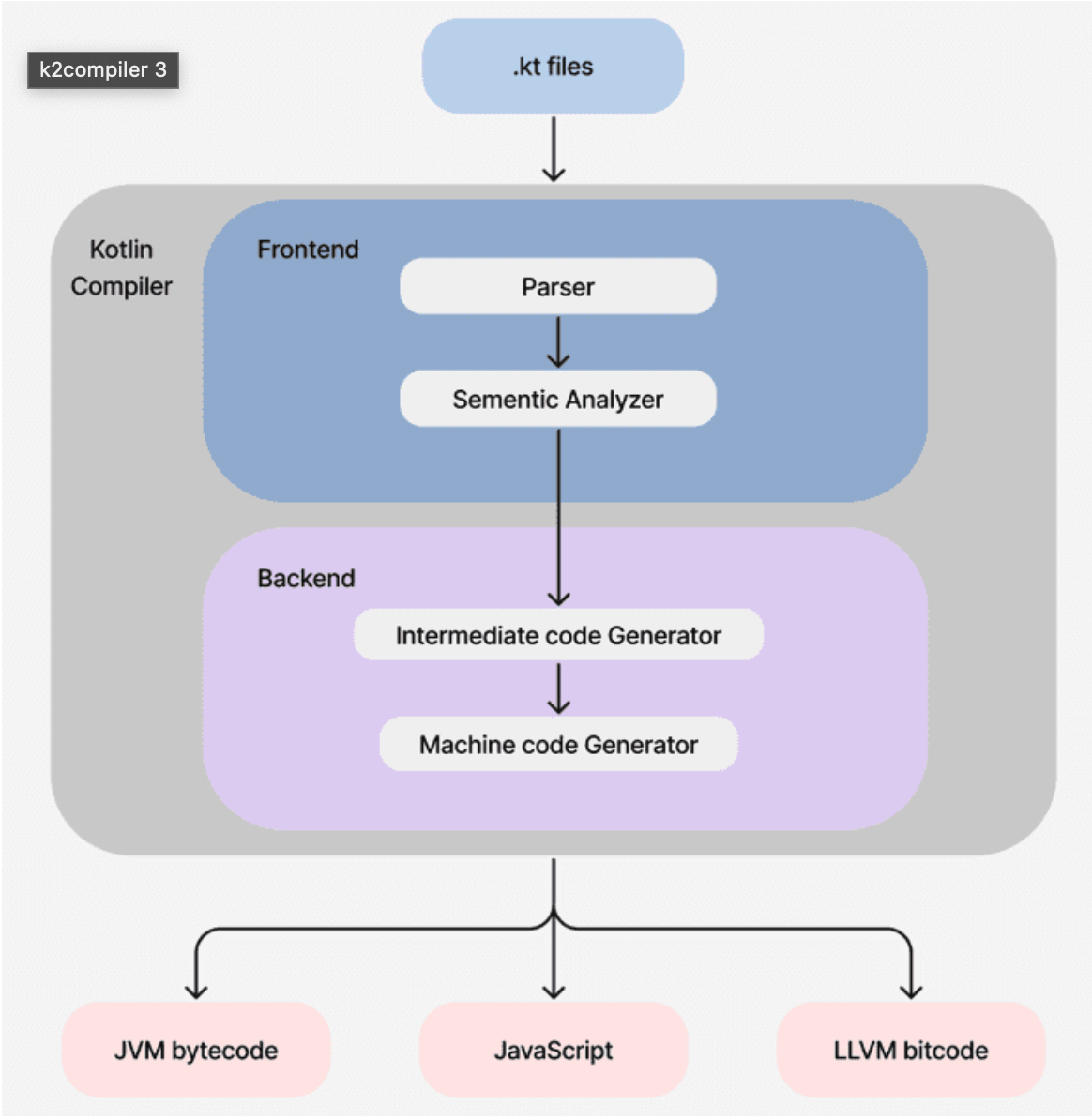
Old Kotlin Compiler
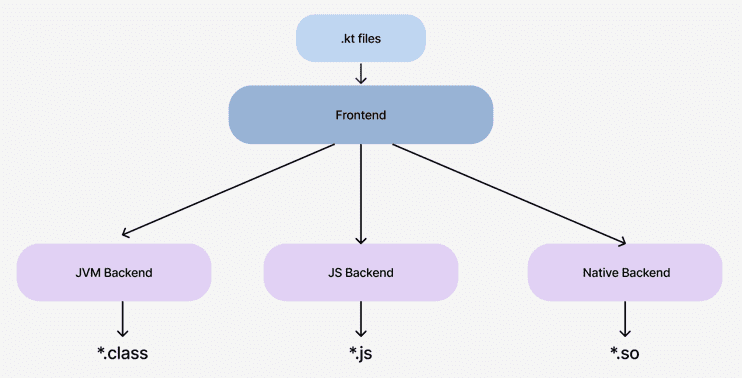
알고있듯이 코틀린 컴파일러는 세가지 타겟 언어를 지원한다. 이에 따라 세가지의 백엔드가 존재한다.
과거 10년전 코틀린 컴파일러는 Syntax tree와 Sementic Info를 통해 JVM, JS코드를 직접 만들어 냈다. (이는 코틀린 개발자가 8명이여서 빠르게 개발하기 위함) 따라서 Intermediate code Generator 즉 (IR : intermediate Representation)은 사용하지 않았다.
하지만, LLVM bitcode generator가 등장하게되며, 일부 로직(겹치는 중간 코드가 많음)을 공유할 수 있는것이 확인되어서 IR을 LLVM에만 도입하게 된다.
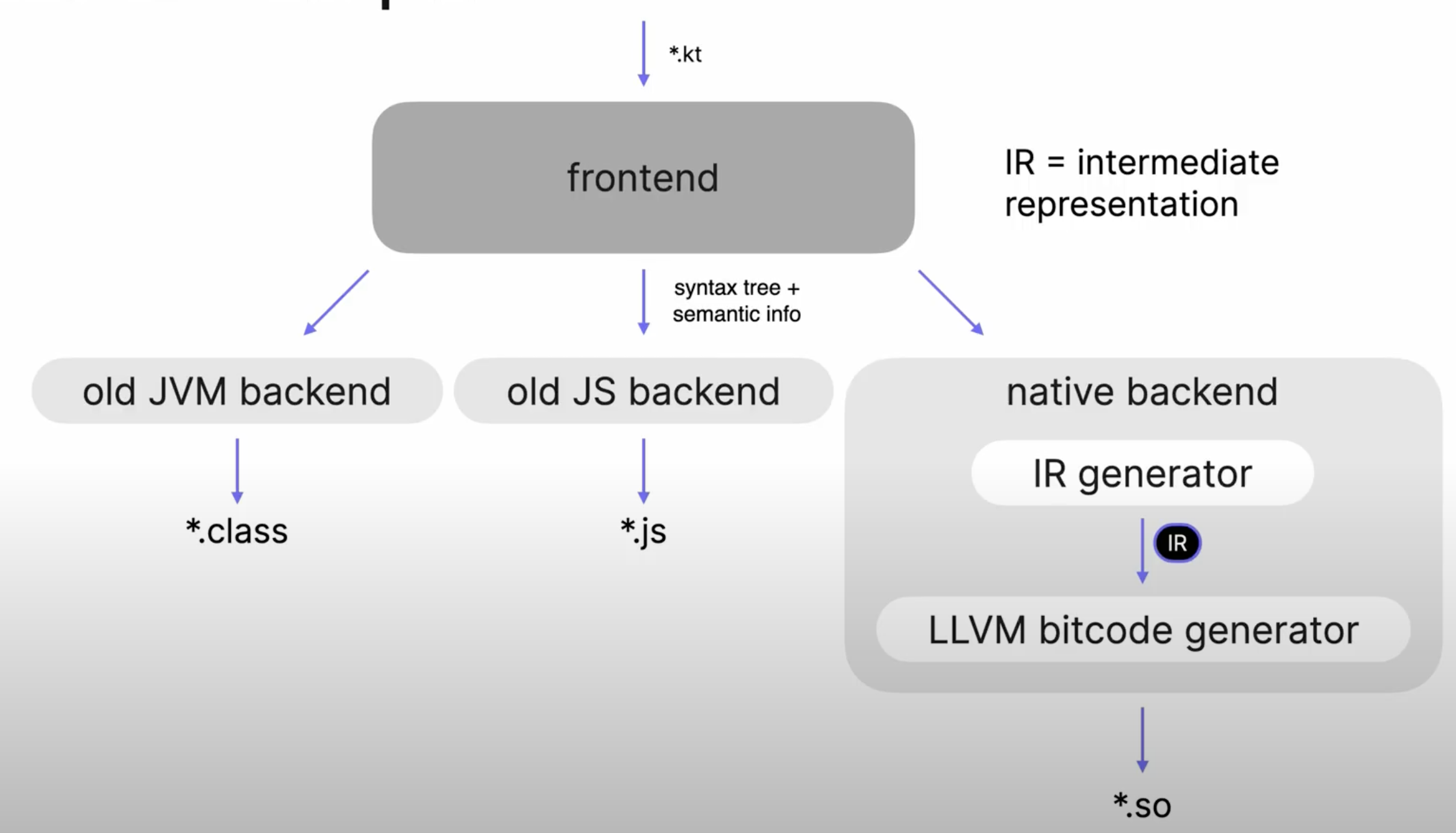
IR(Intermediate Representaion)이란?
코드 생성을 위해 설계된 코드의 트리라고 생각하면 편하다.
New Kotlin Compiler (K2 Compiler)
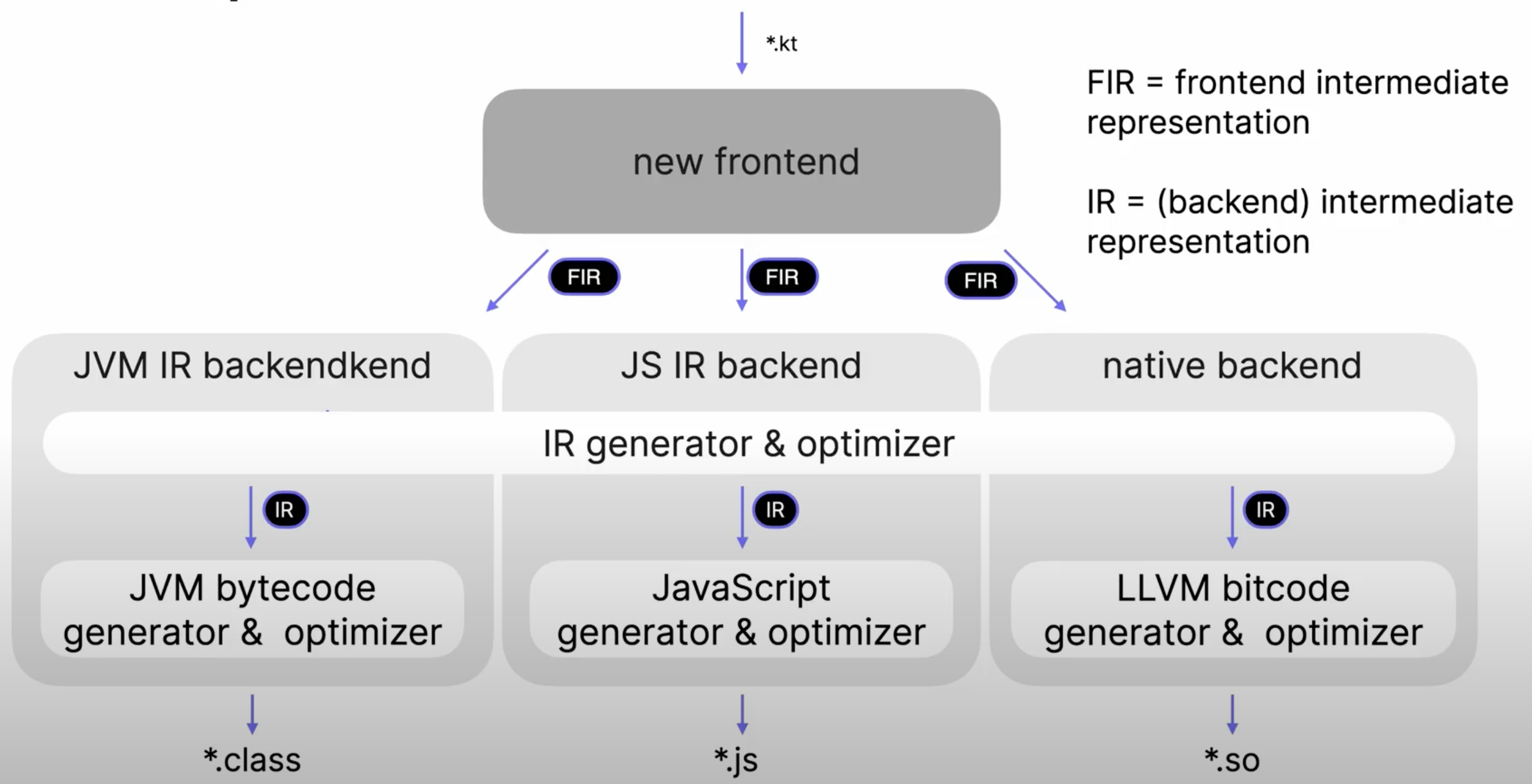
New Backend Compiler
K2컴파일러에서는 이전 구조에서 추상화의 문제점을 깨닫고 이를 수정하였다.
- 전체 계층에 AOP느낌으로 IR을 두어 백엔드간에 로직을 공유하도록 변경
- Old -> New는 성능향상 목적 X, 다른 백엔드 간 로직 공유하는 것이 목적
- 이렇게 공유된 IR을 활용하면 새로운 기능을 더 쉽게 지원할 수 있어서 이전함
백엔드에서 타겟언어로의 변환은 복잡하지만 IR을 거쳐 공통 로직을 처리하고 나면 좀 더 간단하게 변환할 수 있다.
이러한 과정을 거치며 내부 클래스가 없어지거나, 특정 함수들이 해쉬값을 통한 함수로 포장되거나... 등등에 따른 타입추론이 좀 더 간단해지는 면이 있어서 코틀린 작성도 도움이 될 것 -> 이후 설명
New Frontend Compiler
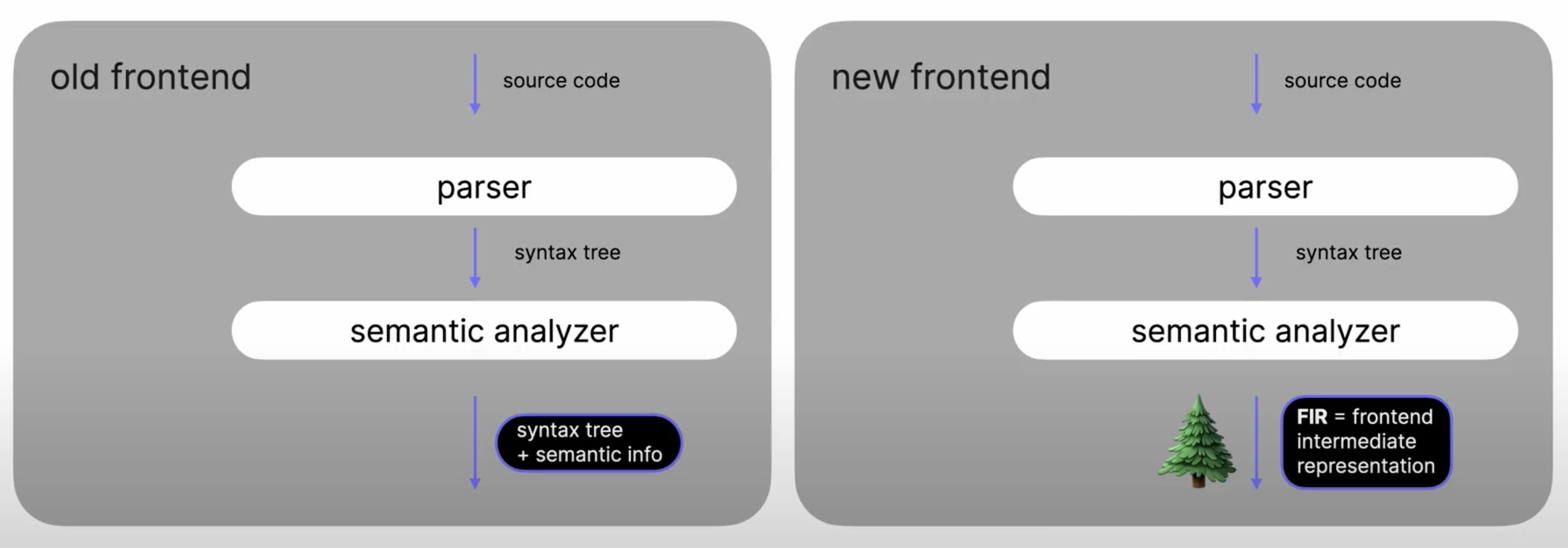
- parser와 sementic analyzer를 사용하는것은 동일
- binding context(맵)에서 차이점이 있다
- New Frontend에서는 맵에 저장하지 않고, 의미 정보가 트리에 직접 저장된다. 이 구조는 FIR(Frontend Intermediate Representation)이라고 부른다
- 정리하자면 Old는 트리와 맵인 두개의 데이터 구조를 생성한다면, New는 하나의 데이터 구조를 생성하게끔해서 성능 향상을 시킨다
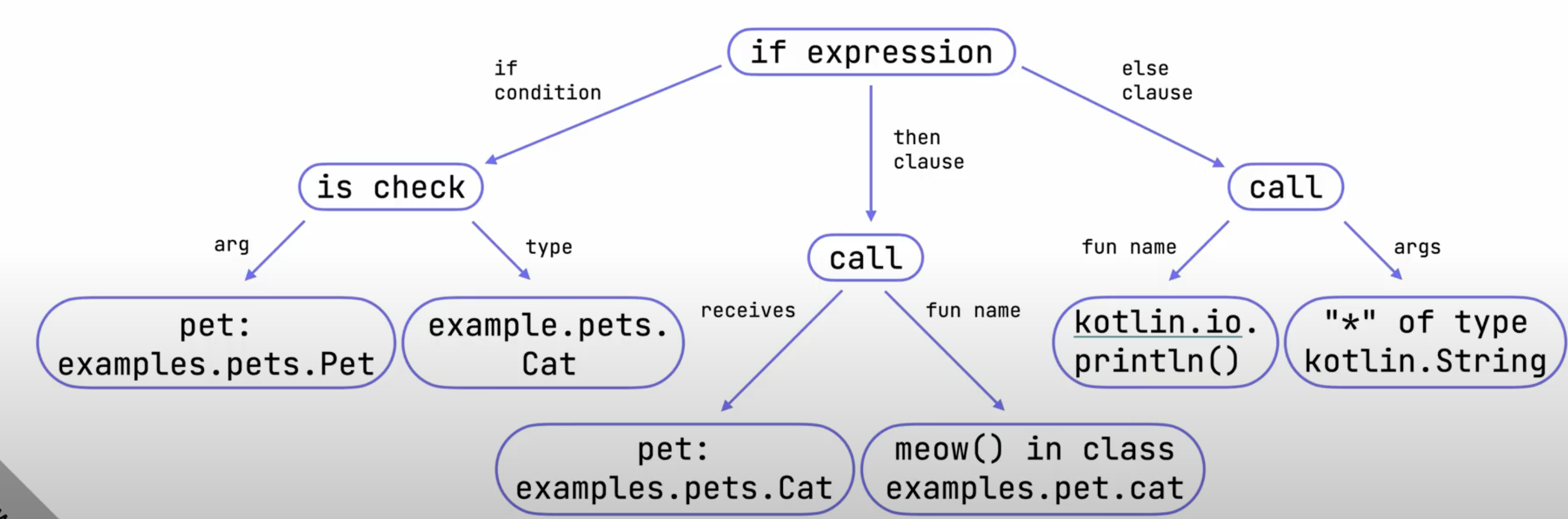
Desugaring 제공
New Frontend에서의 FIR은 디슈가링(안드로이드에서 호환성을 위해 일컫는 Desugaring이랑은 다름)을 지원한다.
디슈가링이란 복잡한 언어 구문을 단순화하고 더 간단한 구문으로 대체하는 것이다.
왜이렇게 늦었나?
전체 인프라, 코드베이스를 갈아엎느라 좀 늦었다. 해당 영상은 21년도에 나왔지만, Kotlin 2.0은 이제서야 (24/05/21)에 릴리즈 되었다.
REF
