
코루틴이 경량 쓰레드라 불리는 이유
코루틴 하나가 새로 생성되어 실행된다는 것과 새로운 스레드를 생성하는 것은 다릅니다.
코루틴은 그 자체로 스케줄링 가능한 코드 블럭 또는 이러한 코드 블록들의 집합이라고 볼 수 있기 떄문입니다.
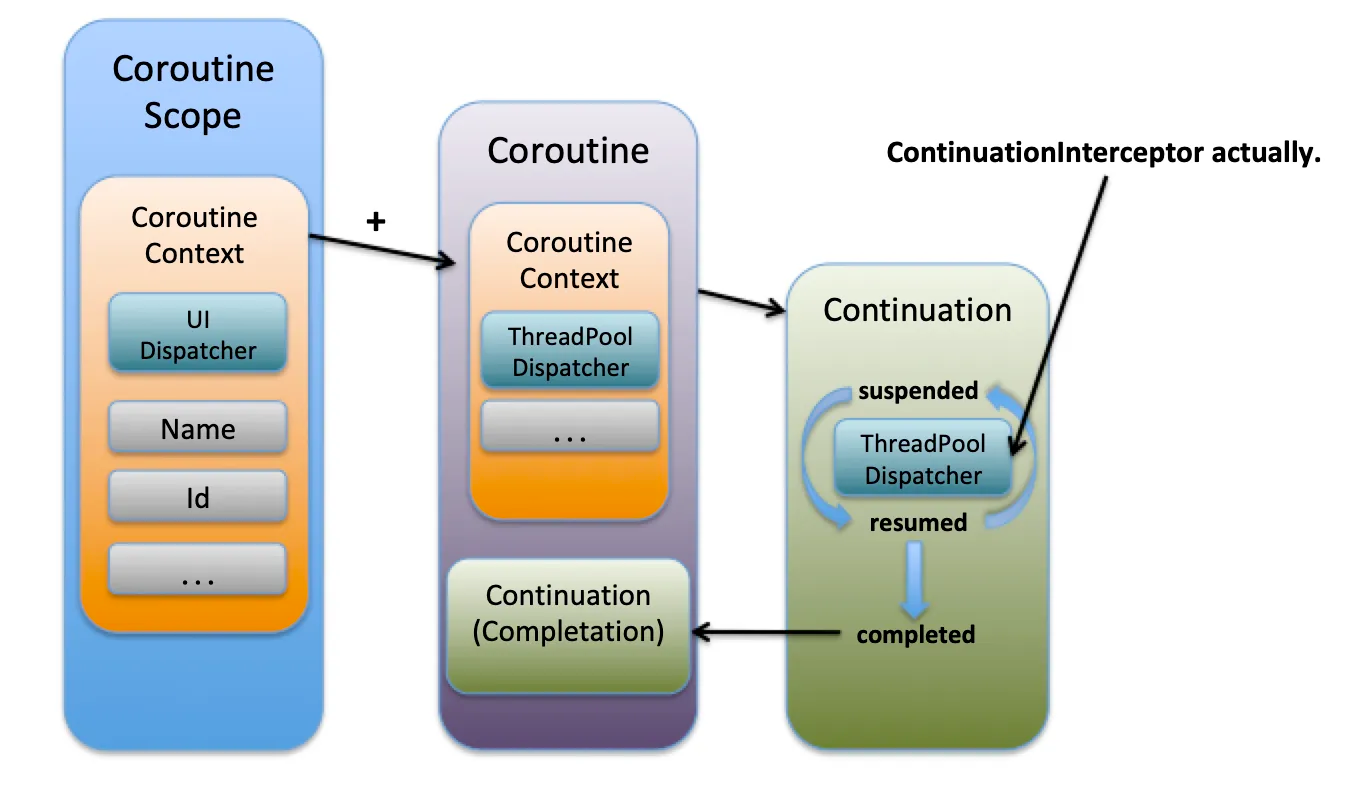
위의 그림에서는
-
최상위 코루틴 스코프에서 코루틴을 생성함
- 해당 코루틴은
UI Dispatcher에 의해 스케줄링 됨 UI Dispatcher에 의해 해당 코루틴은UI Thread에서 실행
- 해당 코루틴은
-
자식 코루틴은 기본값으로 부모의 코루틴을 그대로 상속하지만, 그림에서는
ThreadPool Dispatcher를 재정의하여 사용 함- 따라서 해당 코루틴은
ThreadPoolDispatcher를 통해 백그라운드 쓰레드에서 실행
- 따라서 해당 코루틴은
각각의 코루틴은 CSP스타일에 따라서 Continuation으로 단위로 매핑되고, 실행됩니다.
Continuation으로 변경된 코드 블럭은 suspend되어 있다가, label분기에 의해 실행시점이 다가오면 (resume요청이 발화되면) dispatcher에게 쓰레드 전환이 필요한지 isDispatchNeeded()함수를 이용해 확인한 후 dispatch가 필요하면 dispatch()함수를 호출하여 적합한 쓰레드로 전달하여 수행합니다.
isDIspatchNeeded()란?
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true함수의 설명은 다음과 같습니다.
이 함수는 만약 코루틴의 실행이 dispatch 메서드를 수행해야 한다면 true를 반환합니다.
만약 이 메서드가 false를 반환하면, 코루틴은 현재 스레드에서 즉시 재개됩니다. context 매개변수는 디스패치되고 있는 코루틴의 컨텍스트를 나타냅니다.
디스패처는 이 메서드를 오버라이드하여 성능 최적화를 제공하고 불필요한 디스패치 비용을 피할 수 있습니다.
디스패치를 수행하는 것은 필요할 수 있지만, 이는 성능적인 부분에서는 좋지 않습니다.
따라서 성능향상을 위해 MainCoroutineDispatcher.immediate는 이미 필요한 UI 스레드에 있는지 확인하고 필요하지 않은 경우 추가적인 디스패치를 피합니다.
코루틴 빌드 함수의 디스패쳐 및 coroutinStart
또한 launch 및 async와 같은 코루틴 빌더는 선택적으로 CoroutineStart 매개변수를 허용합니다.
(CoroutineStart또한 CoroutineContext의 요소입니다.)
// CoroutineStart 매개변수
DEFAULT -> block.startCoroutineCancellable(completion)
ATOMIC -> block.startCoroutine(completion)
UNDISPATCHED -> block.startCoroutineUndispatched(completion)
LAZY -> Unit // will start lazilyDEFAULT
DEFAULT는 코루틴 빌더의 기본값이며 해당 코루틴을 현재 콘텍스트에서 즉시 스케줄합니다.
코루틴 컨텍스트의 CoroutineDispatcher가 디스패처에의 isDispatchNeeded 함수에서 true를 반환한다면, 코루틴 코드는 나중에 실행을 위해 스케줄 됩니다. 이때 코루틴 빌더를 호출한 코드는 계속해서 실행됩니다.
@Test
fun coroutineTest() = runBlocking {
launch(start = CoroutineStart.DEFAULT) {
print("A")
}
launch(start = CoroutineStart.DEFAULT) {
print("B")
}
print("C")
}
// 출력
CAB예를들어 위의 코드를 실행한다면 A, B를 출력하는 코루틴이 Continuation이 되어 스케줄링 큐에 들어가고(빌더를 호출한 코드는 계속해서 실행되고) C가 먼저 출력되게 됩니다.
Dispatchers.Unconfined은 항상CoroutineDispatcher.isDispatchNeeded함수에서false를 반환하므로,DEFAULT로Dispatchers.Unconfined으로 코루틴을 시작하는 것은UNDISPATCHED를 사용하는 것과 동일합니다.
launch(
context = Dispatchers.Unconfined, // 그냥 해당 쓰레드에서 바로 실행하기
start = CoroutineStart.DEFAULT // context의 쓰레드를 그대로 활용
) {
}
launch(start = CoroutineStart.UNDISPATCHED) { // 디스패처 진행 안하기
}LAZY
코루틴이 시작될 때 지연 시작합니다. (이는 Job의 생명주기 중 New를 가질 수 있는 것을 의미합니다.)
ATOMIC
ExperimentalApi이며
코루틴을 원자적으로(취소할 수 없는 방식으로) 코루틴 컨텍스트에 따라 실행 예약합니다.
이것은 DEFAULT와 유사하지만, 코루틴은 실행이 시작되기 전에 취소될 수 없습니다.
UNDISPATCHED
위에서 보듯이 UNDISPATCHED를 활용하여 코루틴을 현재 쓰레드에 즉시 시작하여 디스패치 없이 성능을 향상시킬 수 있습니다.
launch(
context = Dispatchers.Unconfined,
start = CoroutineStart.DEFAULT
) {
}DEFAULT는 코루틴을 현재 쓰레드에서 즉시 실행합니다.Unconfined디스패치를 진행하지 않고, 초기Continuation이나, 현 콘텍스트의Continuation에서 코루틴을 실행합니다.
코루틴이 경량 쓰레드라 불리는 이유
코루틴에서 코루틴을 실행할 때 기본값은 기존의 Dispatcher 그대로 상속받아 실행하게 됩니다. Dispatcher은 코루틴이 돌아가는 환경(Thread)을 결정할 수 있지만, 새로운 환경을 구성하거나 변경하지는 않습니다.
따라서 아래와 같은 코드가 OOM없이 작동할 수 있습니다.
@Test
fun coroutineTest() = runBlocking {
repeat(100_000) {
launch(start = CoroutineStart.UNDISPATCHED) {
delay(1000L)
val coroutineThreadName = Thread.currentThread().name
println("코루틴에서 현재 실행 중인 스레드의 이름: $coroutineThreadName")
}
}
}
// 출력 결과
코루틴에서 현재 실행 중인 스레드의 이름: Test worker @coroutine#80449
코루틴에서 현재 실행 중인 스레드의 이름: Test worker @coroutine#80450
코루틴에서 현재 실행 중인 스레드의 이름: Test worker @coroutine#80451
코루틴에서 현재 실행 중인 스레드의 이름: Test worker @coroutine#80452
코루틴에서 현재 실행 중인 스레드의 이름: Test worker @coroutine#80453
launch { }코루틴 빌더는Dispatcher를 재정의 하지 않았기 때문에 현재 스코프(runBlocking)의Dispatcher를 그대로 사용합니다.runBlocking코루틴 빌더는 내부적으로GlobalScope을 사용하며Dispatcher는BlockingEventLoop을 사용하는데, 이는 큐를 이용한 이벤트 루프 형태의Dispatcher구현입니다. 그래서 위 코드는 실행 스레드에서 이벤트 루프 기반으로 10만번의 이벤트를 발생하게 되며 스레드 부하는 없으므로 OOM을 피할 수 있게 됩니다.
위의 소스에서는 Test Worker쓰레드가 10만개 까지 늘어난 것으로 보이지만, 실질적으로 100,000개의 스레드를 생성한 것은 아닙니다. 코틀린의 코루틴은 코루틴 스케줄러에 의해 워커(스레드)를 효율적으로 재사용하며 사용됩니다.
뒤에 붙는 숫자는 각 코루틴의 고유한 식별자(identifier)입니다. 이는 코루틴이 어떤 스레드에서 실행되는지를 추적하고 구분하기 위한 목적으로 사용됩니다.
따라서 많은 코루틴들이 스레드 풀에서 관리되고, 필요에 따라 스레드가 동적으로 생성되거나 재사용될 수 있습니다. 해당 쓰레드풀의 관리를 위해서는 CoroutineScheduler의 설정을 수정해야 합니다.
디스패쳐는 코루틴을 어떻게 스케줄링 하는가?
코루틴 빌더를 통해 코루틴을 생성할 때 어떠한 디스패처도 설정되어 있지 않다면 기본적으로 Dispatchers.Default를 사용하게 됩니다.
이렇게 설정한 디스패쳐(coroutineConext)는 코루틴의 실행을 스케줄링합니다.
그렇다면 어떻게 스케줄링을 진행할까요? 가장 간단한 두개의 디스패쳐를 알아봅시다.
-
Main디스패쳐는 애플리케이션 메인 스레드(single thread)에서EventLoop를 이용해 코루틴의 실행을 스케쥴링 진행 -
Unconfined는 코루틴(Continuation)이 재개(suspend->resume) 되는 스레드에서 바로 스케줄링
그렇다면 Default 및 IO는 어떻게 동작할까요?
Dispatchers.Default 와 Dispatchers.IO
Kotlin JVM에는 백그라운드 작업을 수행하기 위해서Dispatchers.Default와Dispatchers.IO가 준비되어 있으며 작업의 타입에 따라 선택적으로 사용하면 됩니다.
일반적으로 우리는 코루틴을 실행할 때
- CPU 사용이 주를 이루는 작업은
Dispatchers.Default Network, Disk I/O가 주를 이루는 작업은Dispatchers.IO
를 사용한다고 다양한 곳에서 언급하고 있습니다.
이는 어떻게 작동할까요??
Default, IO디스패쳐는 모두 CoroutineScheduler라는 동일한 스케줄러에 의해 공유됩니다.
코루틴들은 디스패쳐를 통해
CoroutineScheduler로 요청 될 때Task라는 형태로 래핑되어 요청됩니다. 이 때,Dispatchers.Default디스패쳐를 사용하도록 설정 된 코루틴은NonBlockingContext으로 표시되어 내부적으로CPU intensive한 작업들을 위한 큐를 이용하여 처리되고,Dispatchers.IO디스패쳐를 사용하도록 설정 된 코루틴은Task에ProbablyBlockingContext로 표시되어 내부적으로I/O intensive한 작업들을 위한 큐를 이용하여 처리 됩니다.
즉, 디스패쳐가 각각의 코루틴을 Task로 매핑한 후, 다른 큐로 스케줄링을 진행합니다.
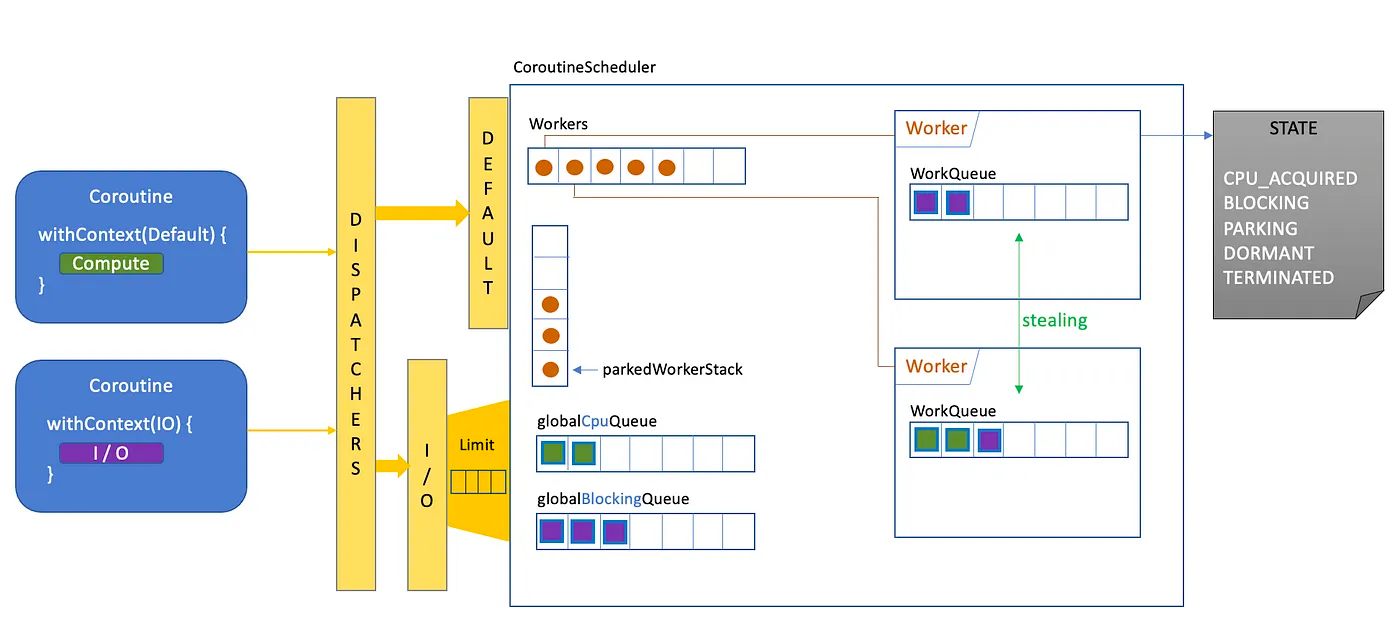
위의 이미지에서
globalCpuQueue는Dispatcher.Default가 활용하는 큐globalBlockingQueue는Dispatcher.IO가 활용하는 큐
를 의미합니다.
또한 Dispatcher.IO의 경우 LimittingDispatcher라는 클래스로 래핑되어 자체적으로 설정 된 병렬 실행 제한치에 따라 스케줄링 요청을 할지, 작업 큐에 넣을지를 결정합니다.
Taks는 다음과 같이 정의됩니다.
// Cpu bound task
const val TASK_NON_BLOCKING = 0
// I/O bound task
const val TASK_PROBABLY_BLOCKING = 1
interface TaskContext {
val taskMode: Int
fun afterTask()
}
class TaskImpl(
val block: Runnable,
submissionTime: Long,
taskContext: TaskContext
) : Task(submissionTime, taskContext) {
override fun run() {
try {
block.run()
} finally {
taskContext.afterTask()
}
}
}
PROBABLY_BLOCKING인 경우 앞서 설명한 것처럼LimitingDispatcher에서 자체적으로I/O parallelism컨트롤을 위해 자체 큐를 운용하고 있으므로 이 함수가 불릴 때 자체 큐에서 대기 중인 작업을CoroutineScheduler에 추가 공급하는데 쓰입니다. (자체적으로 큐를 하나 더 가지고 있음)
이러한 작업들은 Task라는 단위로 CoroutineScheduler에서 관리되며 내부 Worker들에 의해 실행됩니다. CoroutineScheduler는 Java.Executor의 구현체입니다.
Java.Executor란??
자바에서 멀티스레드 환경에서 작업을 비동기적으로 실행하기 위한 인터페이스입니다. 이는 스레드 풀을 관리하고 작업을 스케줄링하는데 사용됩니다. Executor를 활용하여 어플리케이션에서 명시적으로 쓰레드를 관리하지 않아도 됩니다.
public static void main(String[] args) {
// 스레드 풀 생성
Executor executor = Executors.newFixedThreadPool(5);
// 작업을 제출하여 실행
for (int i = 0; i < 10; i++) {
final int taskId = i;
// Executor는 작업을 적절한 스레드에서 비동기적으로 실행합니다.
executor.execute(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
});
}
}runable한 테스크를 전송하여 알잘딱 실행
Executor executor = anExecutor;
executor.execute(new RunnableTask1());
executor.execute(new RunnableTask2());CoroutineScheduler는 일반적으로 Excutor가 갖는 속성을 가집니다.
- corePoolSize : 최소로 유지되는 Worker 수
- maxPoolSize : 최대 Worker 수
- idleWOrkerKeepAliveNs : 지정된 나노 초가 지난 유후 Worker제거
이러한 속성에 따라서 CoroutineScheduler는 필요한 만큼의 Worker를 생성 및 제거하며 배열로 관리합니다. 이렇게 관리되는 Worker들 중에서 Parked Worker들은 추가적으로 별도의 스택에서 참조되어 관리됩니다.
Worker란? 자바의 쓰레드입니다.
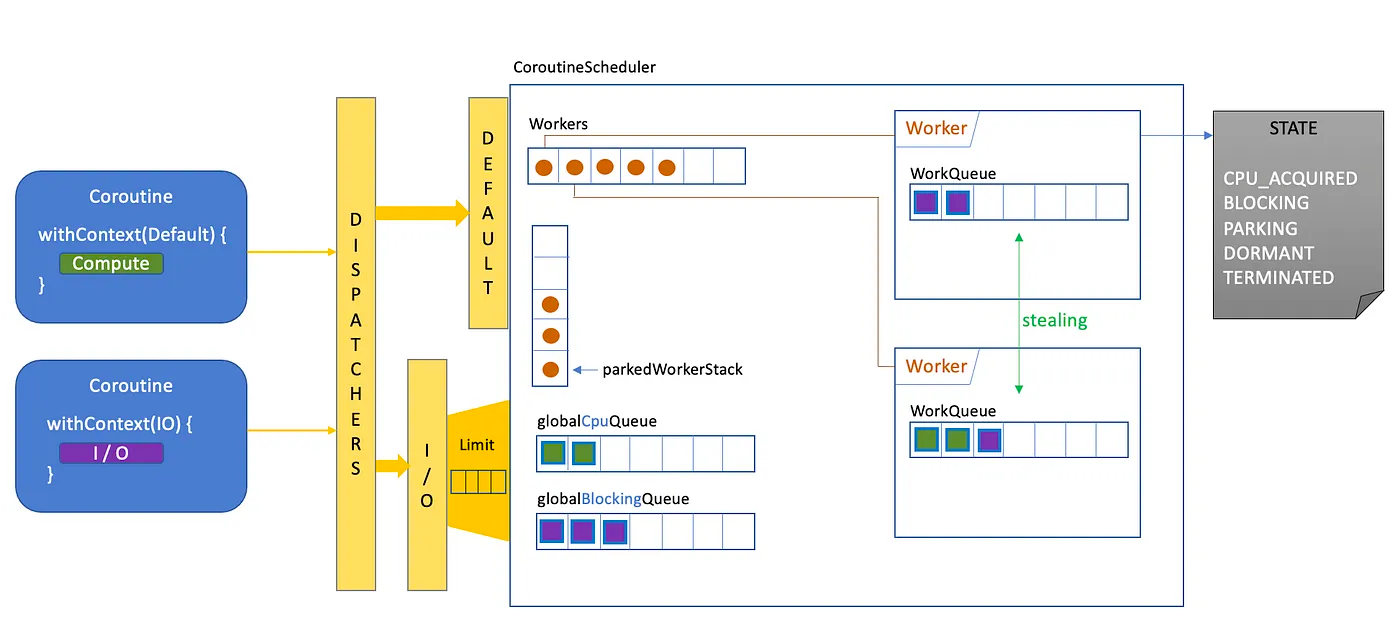
이러한 코루틴스케줄러의 내부 Worker들은 각각 개별 큐를 가집니다. 이 큐는 SPMC (Single-Producer, Multi-Consumer) 자료구조로 사용 됩니다.
Producer는 해당 큐를 소유한Worker로 유일한Task Producer입니다.Multi-Consumer인 이유는 어떤Worker가 너무 바빠서 대기중인Task가 너무 많거나 혹은 어떤Worker가Blocking I/O로 인해 대기 상태에 들어가 요청된Task들의 수행이 지연되고 있다면 일을 먼저 마친Worker바쁜Worker를 살펴본 후 해당Worker의Task를 뺏어다 대신 수행하는Task Stealing Algorithm이 적용 되어 있기 때문있습니다.
이미지 좌측 하단에 globalCpuQueue 와 globalBlockingQueue 가 있습니다. 각 Worker 에 할당되지 못한 Task 들은 이곳에 TaskContext 에 따라 적절한 큐에 삽입된 이후 가용한 Worker 가 생기면 자신의 로컬큐로 가져가 이후 작업을 수행합니다.
결론
즉, 코루틴은 Executor의 구현체인 CoroutineScheduler에 의해 스케줄링 되며 실행됩니다.
실행되는 과정은 Dispatcher에 따라 달라지며 특정 디스패쳐인 Main, Unconfined를 제외하고 IO, Default는 각각의 성격에 맞게 별도로 스케줄링됩니다. (IO, Default용 쓰레드풀이 따로 존재하는 건 X, 그저 스케줄링이 다르게 될 뿐)
IO디스패쳐의 경우는 실행할 코루틴이 I/O Blocking을 유발할 수 있다고 가정하여 별도의 큐를 활용함과 동시에 병렬실행을 위한 큐도 따로 존재합니다.
이렇게 스케줄링된 코루틴(Task)들은 내부 워커(Thread)의 내부 작업 큐에 들어가서 실행되게 됩니다.
이러한 방식이 작업을 전환하는데 있어 기존의 멀티쓰레딩의
Context Switching에 비해 더 적은 오버헤드를 발생시킵니다.또한 스케줄링을 직접 지정할 수는 없지만,
I/O,Default라는 스케줄링 선택권을 개발자에게 제공함으로써 코루틴을 좀 더 가볍게 쓸 수 있도록 합니다. (이것이 가능한 방식은 코루틴이 정지함수를CSP방식으로 구현하기 때문입니다.)
참고 자료
