
이 글은 Python의 모듈인 Pandas를 공부하고 정리한 글입니다.
항상 Python에서 데이터를 다룰때 Pandas를 사용했지만
기초는 모른체 구글에서 검색하거나 감으로 사용했었다.
이 기회에 기초를 공부해보았다.
w3school의 Pandas강의를 참고해서 공부했다
Pandas가 뭔가요
- Pandas는 Python에서 데이터 분석을 할때 사용하는 모듈이다.
테이블 형식의 2차원 자료를 다룰때 유용하게 사용한다.
pip install pandas위의 명령어를 사용해서 모듈을 다운로드 할 수있다.
import pandas위의 코드를 사용해서 모듈을 사용 할 수 있다.
import pandas as pdPython에서 모듈은 as 키워드를 사용해서 모듈명을 축약 할 수 있는데
보통 Pandas는 pd라는 이름으로 축약한다.
Pandas의 시리즈란?
- Series : 테이블의 하나의 열, 1차원 배열과 같다.
하나의 시리즈에는 여러 자료형이 들어갈 수 있다.
a = [1, 7, 2]
myvar = pd.Series(a)위의 코드를 사용해서 리스트를 시리즈로 만들었다.
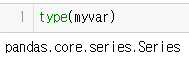
자료형이 pandas.core.series.Series인걸 볼 수 있다.
a = [1, 7, 2, 12]
myvar = pd.Series(a)
print(myvar[3]) #12시리즈의 원소에 접근할때는 인덱스를 사용한다.
a = [1, 7, 2]
myvar = pd.Series(a, index=["x", "y", "z"])
print(myvar["z]) #2시리즈를 생성할 때 기본 인텍스는 기존 리스트의 인덱스와 같다.
시리즈를 생성할 때 index인자를 사용하면 인덱스를 따로 지정 해 줄 수 있다.
calories = {"day1": 420, "day2": 380, "day3": 390}
myvar = pd.Series(calories)
myvar딕셔너리를 시리즈로 제작해주면 각 원소의 인텍스가 해당하는 Key로 지정된다.
데이터프래임이란????
- 데이터 프래임은 2차원 구조를 가진 테이블과 같은 자료구조이다.
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
df위의 예제는 data 딕셔너리를 데이터프래임으로 만들어주었다.
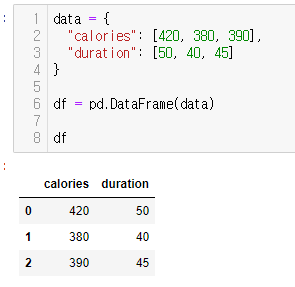
data의 key들이 각각의 열이 되고 value가 열을 이루는 데이터로 행이 된것을 볼 수 있다.
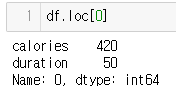
데이터프래임에서 인텍스를 사용해서 행을 찾을때는 loc라는 속성을 사용한다.
이때 결과는 시리즈를 반환한다.
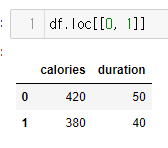
여러 행을 찾을때는 찾고자하는 인덱스를 리스트로 전달을 한다.
이때는 결과로 데이터프래임을 반환한다.
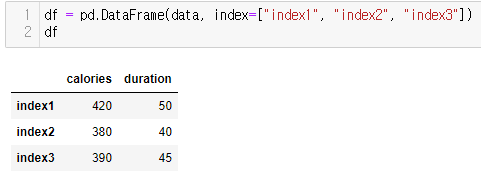
데이터프래임 역시 index 속성을 사용해서 각 행들의 인덱스를 지정 해 줄 수 있다.
