
1. 프로세스(process) 개념
프로세스(process)는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다. 종종 스케줄링의 대상이 되는 작업(task)이라는 용어와 거의 같은 의미로 쓰인다.
2. 프로그램과 프로세스
프로세스에 대해 공부할때 빠지지 않고 비교하는 대상이 있는데 바로 프로그램과 프로세스의 차이입니다.
- 프로그램 : 프로그램은 일반적으로 하드 디스크 등에 저장되어 있는 실행코드
- 프로세스 : 프로그램을 구동하여 프로그램 자체와 프로그램의 상태가 메모리 상에서 실행되는 작업 단위
3. 메모리상의 프로세스
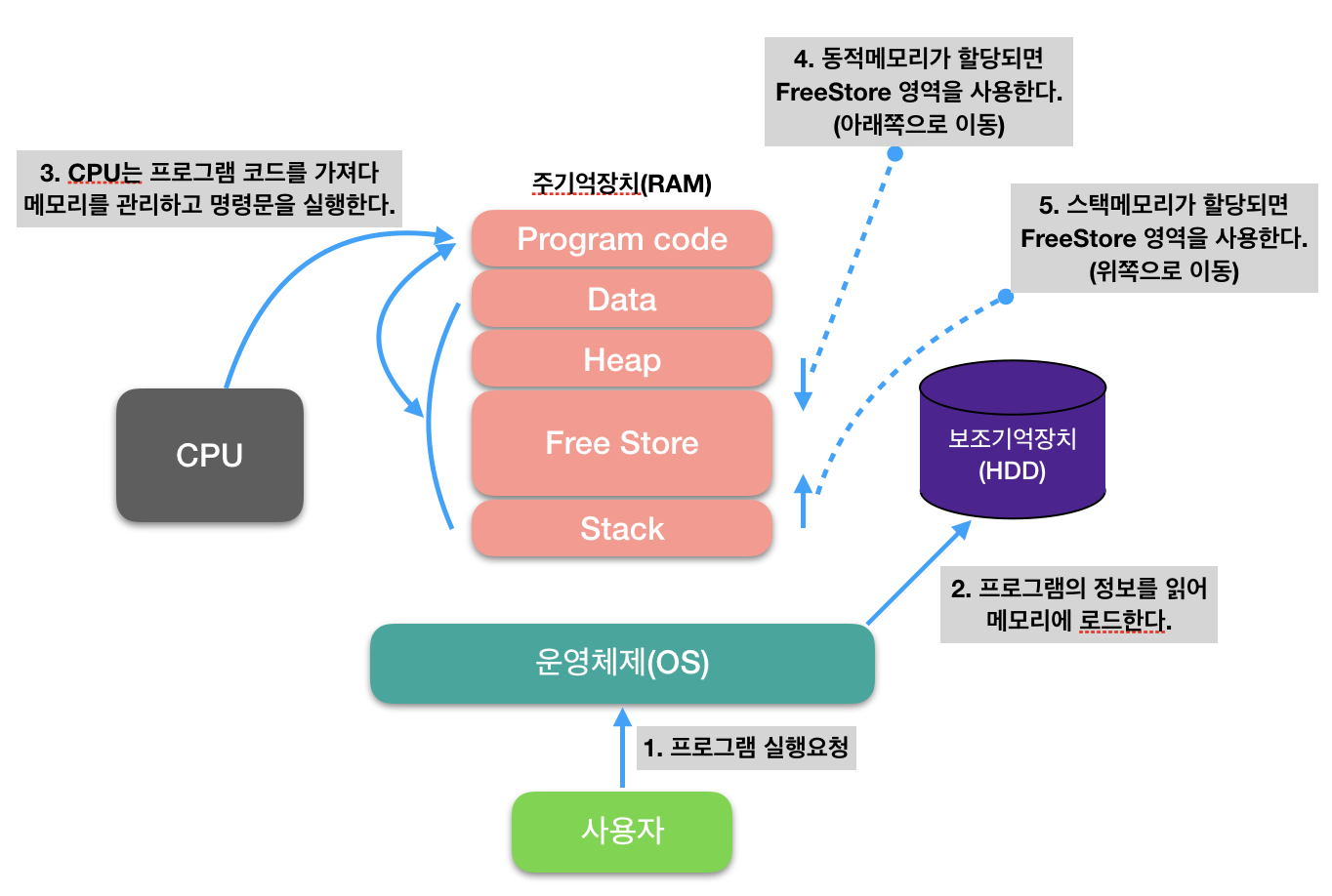
-
코드 영역 : 우리가 작성한 소스코드가 들어가는 부분. 즉, 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 부른다. 함수, 제어문, 상수 등이 여기에 지정된다.
-
데이터 영역 : 전역변수와 static 변수가 할당되는 부분. 프로그램의 시작과 동시에 할당되고, 프로그램이 종료되어야 메모리에서 소멸되는 영역. (데이터 영역을 초기화여부에 따라 Data와 BSS로 나눠서 설명하기도 합니다)
-
스택 영역 : 프로그램이 자동으로 사용하는 임시 메모리 영역. 함수 호출시 생성되는 지역변수와 매개변수가 저장되는 영역이고, 함수 호출이 완료되면 사라짐.
-
힙 영역 : 프로그래머가 할당/해제하는 메모리 공간. 이 공간에 메모리를 할당하는 것을 동적할당이라고도 부른다.
스택영역과 힙영역은 사실 같은 공간을 공유합니다. HEAP이 메모리 위쪽 주소부터 할당되면 STACK은 아래쪽부터 할당되는 식입니다. 그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 HEAP OVERFLOW, STACK OVERFLOW라고 칭합니다.
4. 프로세스 상태(Process State)
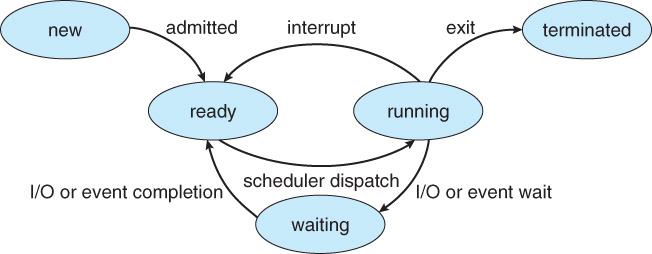
대학교 OS공부시간에 참 많이보던 그림입니다. 프로세스는 실행되면서 그 상태가 변하는데 위 5가지 상태중에 한가지에 놓이게 됩니다.
프로세스의 5가지 상태
1. New (생성) : 사용자가 프로그램을 실행하면 프로세스가 생성됩니다.
2. Ready (준비) : 프로세스가 대기 큐에서 CPU를 차지하기 위해서 기다립니다.
3. Running (실행) : 프로세스가 CPU를 차지하면서 실행되는 상태입니다.
4. Waiting(대기) : 프로세스가 입출력이나 이벤트를 기다리는 상태입니다. 해당일이 끝나면 준비상태로 되돌아갑니다.
5. Terminated (종료) : 프로세스 종료 상태
프로세스의 상태전이
- Dispatch : 준비 상태에 있는 프로세스 중 하나를 선택하여 실행시키는 것을 의미합니다.
- Interrupt : 운영체제는 프로세스가 CPU를 자발적으로 반납하지 않고 독점하는 경우를 방지하기 위해 하드웨어적으로 인터럽팅 클록을 주기적으로 발생시켜 프로세스가 특정 시간 간격동안만 실행할 수 있도록 합니다.
5. 프로세스 제어블록(Process Control Block)
프로세스에 대한 정보는 프로세스 제어블록(PCB, Process Control Block)라고 부르는 자료구조에 저장됩니다.
이 자료구조는 크게 다음과 같은 정보를 담고있습니다.

이미지 출처 : https://asfirstalways.tistory.com/117
-
PID : 운영체제가 각 프로세스를 식별하기 위해 부여된
프로세스 식별번호 -
프로세스 상태 : 위에서 살펴봤던 5가지 중에 한가지의
프로세스의 상태를 저장합니다. -
프로그램 카운터 : CPU가
다음으로 실행할 명령어를 가리키는 값입니다. CPU는 기계어를 한 단위씩 읽어서 처리하는데 프로세스를 실행하기 위해 다음으로 실행할 기계어가 저장된 메모리 주소를 가리키는 값입니다. -
CPU 레지스터 및 일반 레지스터 : 레지스터는 컴퓨터의 구조에 따라 다양한 수와 타입을 가지는데 대표적으로 누산기, 인덱스 레지스터, 스택 레지스터, 범용 레지스터 등이 있습니다. 나중에 프로세스가 계속 올바르게 처리되도록 하기 위해서 꼭 저장되어야 합니다.
-
CPU 스케줄링 정보 : 운영체제가 여러 개의 프로세스가
CPU에서 실행되는 순서를 결정하는 것을 스케줄링이라고 합니다. 이 스케줄링에서 우선순위가 높으면 먼저 실행될 수 있는데 이를스케줄링 우선순위라고 합니다. -
포인터 : 부모프로세스에 대한 포인터, 자식 프로세스에 대한 포인터, 프로세스가 위치한 메모리 주소에 대한 포인터, 할당된 자원에 대한 포인터 정보 등.
-
입출력 상태 정보 : 프로세스에 할당된 입출력장치 목록, 열린 파일 목록 등
PCB가 프로세스의 중요한 정보를 포함하고 있기 때문에, 일반 사용자가 접근하지 못하도록 보호된 메모리 영역 안에 남는다. 일부 운영 체제에서 PCB는 커널 스택의 처음에 위치한다. (이 메모리 영역은 편리하면서도 보호를 받는 위치이기 때문이다.)
6. 문맥교환(context switching)
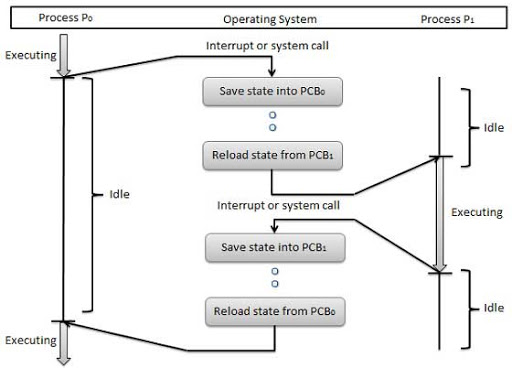
문맥교환이란 CPU를 점유하고 있던 프로세스에서 다음기다리는 프로세스로 바턴을 넘겨주는것을 의미합니다.
문맥교환이 일어나는 상황은 크게 2가지 입니다. Interrupt발생 시와 System Call 발생 시. 즉, 시간이 다 되었거나 아니면 입출력 요청이 들어왔거나 입니다.
다른 프로세스로 넘어가는 과정은 상당한 오버헤드와 지연을 발생시킵니다. 근데도 이렇게 하는 이유는 뭘까요? 당연히 하나만 수행할 수 없기 때문입니다. 동시에 실행하는것처럼 하기 위해서 입니다.
마침
프로세스 양이 상당하다보니 다음시간도 프로세스를 이어서 해야할거 같네요.
References
- 위키피디아 프로세스 : https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
- jinShine님의 블로그 : 메모리 구조
- 멍멍멍님의 블로그 : https://bowbowbow.tistory.com/16
- PROJECT REBAS님의 블로그 : https://rebas.kr/852
![]()
