
1. 프로세스 생성
프로세스는 실행 도중에 프로세스 생성 시스템 호출을 통해 새로운 프로세스를 생성할 수 있습니다. 이 때 생성하는 프로세스를 부모 프로세스, 새로운 프로세스를 자식 프로세스라고 부릅니다. 새로 만들어진 프로세스도 자식 프로세스를 만들 수 있는데 그 결과 프로세스 트리를 형성합니다.
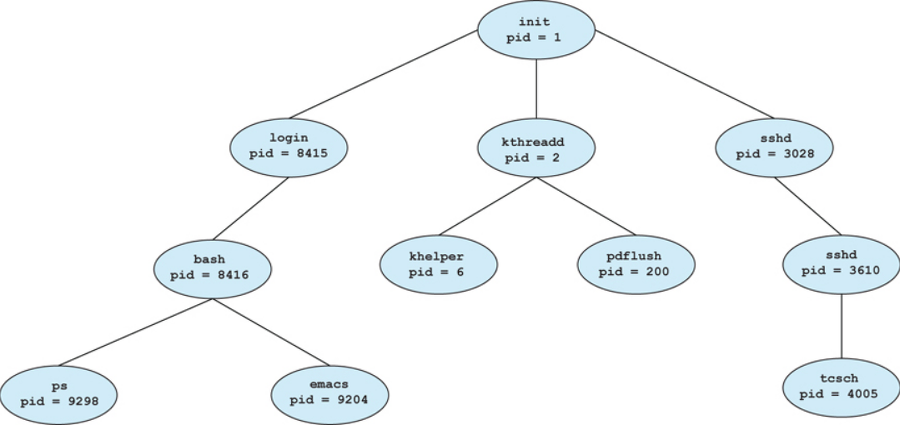
대부분의 운영체제는 프로세스를 식별할 때 process id(pid) 로 구분하는데 보통 정수값입니다. pid가 1인 init프로세스가 루트 부모 프로세스 역할을 수행하며, 시스템이 부팅되면 init프로세스는 다양한 사용자 프로세스를 생성합니다.
보통 ps -ef 명령이나 ps aux 명령을 사용해서 현재 돌아가고 있는 프로세스를 확인할 수 있습니다.

보통 프로세스가 자신의 task를 수행하려면 자원들(CPU, 메모리, 파일, 입출력장치)이 필요합니다.
- 방법1. 프로세스가 subprocess(자식 프로세스)를 생성하면 운영체제로부터 직접 자원을 받던가
- 방법2. 부모 프로세스 자원을 나눠갖습니다. 이 때 초기화 자료를 부모 프로세스가 자식 프로세스로 넘겨줄 수도 있습니다.

-
1단계. 새로운 프로세스는 부모 프로세스가
fork()시스템 호출로 생성됩니다. 새로운 프로세스는 원래 프로세스의 주소공간의 복사본으로 구성됩니다. 이렇게 함으로써 부모와 자식 프로세스간 쉽게 통신이 가능하게 됩니다. -
2단계.
fork()시스템 호출 다음에 두 프로세스 중 한 프로세스가exec()시스템 호출을 사용하여 자신의 메모리 공간을 새로운 프로그램으로 교체합니다. 이와 같은 방법으로 부모와 자식이 나눠지게 되며 각자의 길을 가게 됩니다. -
3단계. 자식프로세스가 실행되는 동안 부모프로세스가 할일이 더이상 없다면 부모프로세스는 자식이 종료될때 까지 ready queue에서 자신을 제거하기 위해
wait()시스템 호출을 합니다. -
4단계. 자식 프로세스가 끝나면
exit()시스템 호출을 하여 종료시킵니다. 부모 프로세스 역시 wait() 호출로 부터 재개하여 exit() 시스템 호출을 사용하여 끝냅니다.
아래와 같이 C프로그램을 작성할 수 있습니다.
#include <stdio.h>
int main(int argc, char* argv[])
{
int pid;
/* 새 프로세스를 생성한다.(fork) */
pid = fork();
if(pid < 0) { // 오류
fprintf(stderr, "Fork Failed");
return 1;
}
else if(pid == 0) { // 자식 프로세스
/* 자식 프로세스를 새로운 프로그램으로 바꿈 */
execlp("/bin/ls", "ls", NULL);
}
else { // 부모 프로세스
/* 자식 프로세스가 완료되기를 기다림 */
wait(NULL);
printf("Child Complete");
}
return 0;
}2. 프로세스 종료
프로세스는 종료를 위해 exit() 시스템 호출을 사용해야 합니다. 종료 시 모든 자원은 운영체제로 반환됩니다.
일반적으로 부모 프로세스는 자식 프로세스가 종료되기를 기다렸다가 연쇄적으로 종료되지만, 여러가지 이유로 인하여 자식들 중 하나의 실행을 종료할 수 있습니다.
-
경우1. 자식이 자신에게 할당된 자원을 초과하여 사용할 때
-
경우2. 자식에게 할당된 태스크가 더 이상 필요없을 때
-
경우3. 부모가 exit를 하는데, 운영체제는 부모가 exit한 후에 자식이 실행을 계속하는 것을 허용하지 않는경우. 이것을
cascading termination(연쇄식 종료)라고 부릅니다.
3. 프로세스간 통신
프로세스에는 두가지 종료가 있습니다.
-
Independent Process(독립적인 프로세스) : 프로세스가 시스템에서 실행 중인 다른 프로세스들에게 영향을 주거나 받지 않는 경우. 다른 프로세스와 데이터를 공유하지 않는경우에 해당.
-
Cooperating Process(상호 협력적인 프로세스) : 프로세스가 시스템에서 실행 중인 다른 프로세스들에게 영향을 주거나 받는 경우. 다른 프로세스와 자료를 공유하는 경우에 해당.
그렇다면 왜 상호 협력을 할 필요가 있을까?
-
Information Sharing(정보공유) : 여러 사용자가 동일한 정보(공유 파일 등)에 흥미를 가질 수 있으므로 그러한 정보를 병행적으로 접근할 수 있도록 환경을 제공
-
Computation Speed-up(계산 가속화) : 특정 task의 계산을 빠르게 하고 싶으면 그것을 subtask로 나누어 병렬로 수행되게 할 수 있다. 이 것은 여러개의 CPU 또는 I/O 채널 등 복수 개의 processing element가 있어야만 수행될 수 있다.
-
Modularity(모듈성) : 시스템 기능을 별도의 프로세스들 또는 스레드들로 나누어 모듈형 시스템을 구성해야 할수도 있다.
-
Convenience(편의성) : 개별 사용자들이 많은 task를 동시에 수행할 수도 있다. 이 때 병렬로 처리되도록 환경을 제공해야한다.
프로세스간 통신기법(Interprocess Communication, IPC)에는 2가지 기법이 존재합니다. 공유메모리와 메시지 전달.
공유메모리(Shared Memory)
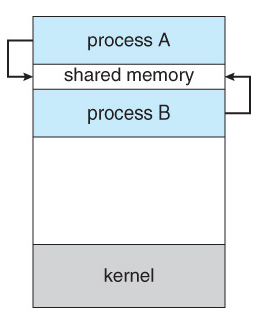
shared memory는 프로세스들에 의해 공유되는 메모리 영역이며, 그 영역에 데이터를 읽고 씀으로써 정보를 교환할 수 있습니다. shared memory는 자원 사용 시 충돌 문제가 있지만 속도가 빠르고 편이를 제공합니다.
메시지 전달(Message Passing)
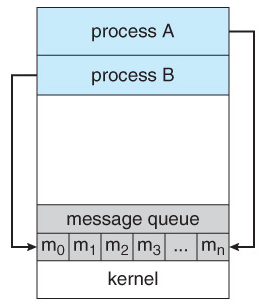
message passing은 프로세스들 사이에 교환되는 메시지를 통해 정보를 교환합니다. message passing은 충돌을 회피할 필요가 없기 때문에 적은 양의 데이터를 교환할 때 유용하고 구현이 쉽습니다. 하지만 message passing은 system call을 통해 kernel을 거쳐야하므로 시간을 좀 더 소비하게 됩니다.
4. 공유 메모리 시스템
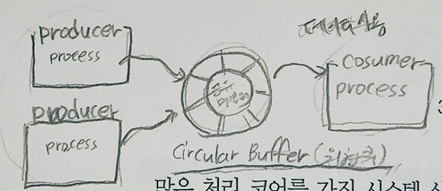
프로세스들은 공유 메모리를 읽고 씀으로써 정보를 교환할 수 있습니다. 이 때 프로세스들이 동시에 동일한 위치에 쓰지 않는다는 것을 보장해야 합니다.
보통 producer-consumer(생상자-소비자) 모델을 동기화하는 일반적인 패러다임으로 생각합니다. producer는 버퍼에 채우고 consumer는 버퍼의 내용을 소비하고, 그 사이에는 공유메모리(=버퍼)가 존재합니다. 이 때 동시에 접근해서는 안되고 버퍼가 꽉 차거나 비었을 때를 고려해야 합니다.
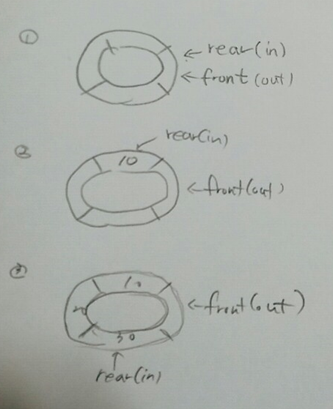
생성자 : 생성자는 버퍼가 가득차게 되면 소비자가 정보를 소비할때까지 대기해야 합니다.
item nextProduced;
while(true) {
/* produce an item in nextProduced */
while(((in + 1) % BUFFER_SIZE) == out); // wait
buffer[in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
}소비자 : 소비자는 버퍼가 비어있으면 생성자가 정보를 넣어줘야 할때까지 대기해야 합니다.
item next_Consumed;
while(true){
while(in == out); // wait
/* consume the item in nextConsumed */
next_Consumed = buffer[out];
out = (out+1)%BUFFER_SIZE;
}여기엔 동기화가 적용이 안됐는데 producer와 consumer가 버퍼에 동시에 접근하는 경우 문제가 생길 수 있습니다. 이 것은 나중에 다루게됩니다.
5. 메시지 전달 시스템
shared memory와 같은 효과를 낼 수 있는 다른 방법은 운영체제가 messaging-passing 설비를 구축하고 프로세스간 통신 수단을 제공해 주는 것입니다. messaging-passing 방식은 통신하는 프로세스들이 서로 다른 컴퓨터에서 네트워크로 연결된 분산 환경일 때 특히 유용합니다.
messaging-passing system은 최소한 send, receive 연산을 제공해야 합니다. messaging-passing system을 고려할 때 고려해야 하는 세 가지 사항이 있습니다.
고려사항
- 직접 통신 or 간접 통신 => Naming
- 동기식 통신 or 비동기식 통신 -> Synchroinization
- 자동 버퍼링 or 명시적 버퍼링 => Buffering
1. Naming
직접통신
- send(P, message) - 프로세스 P에게 메시지를 송신한다
- receive(Q, message) - 프로세스 Q로부터 메시지를 수신한다
문제점은 서로 상대방의 신원을 알고 정의해야합니다. 만약 프로세스의 이름을 바꾸면 모든 다른 프로세스 정의를 검사할 필요가 있습니다. 1대1 통신만 가능합니다. (추천하지 않는 방식입니다)
간접통신
- send(A,messgae) - 메시지를 메일박스 A로 송신한다
- receive(A, message) - 메시지를 메일박스 A로 부터 수신한다
연결은 2개 이상의 프로세스들과 연관될 수 있습니다.
2. Synchroinization
동기식(Blocking)
- 동기식 보내기 : 송신프로세스가 정보를 보냄. 수신프로세스가 수신할때까지 아무것도 안함(예를 들어, 전화를 걸때)
- 동기식 받기 : 송신프로세스가 정보를 전달할때까지 수신프로세스는 아무것도 안함
비동기식(Non-Blocking)
- 비동기식 보내기 : 송신프로세스가 정보를 보내고, 수신프로세스가 받던지 말던지 상관없이 딴일을 함(예를들어, 카톡)
- 비동기식 받기 : 유효한 메시지 혹은 널을 받는다
send와 receive가 모두 봉쇄형일때 우리는 송신자와 수신자간에 랑데부(rendezvous protocol) 를 갖게된다고 한다. 1:1연결. 보내는 쪽과 받는 쪽이 명확해지고 서로 계속 연결을 유지하기 때문에 중간에 버퍼가 필요없다. 무용량(zero cpapcity) 버퍼가 가능해진다.
3. Buffering
- Zero Capacity(무용량): queue의 최대 길이가 0이다. sender는 receiver가 메시지를 수신할 때까지 기다려야 한다.
- Bounded Capacity(유한용량): queue가 유한한 길이를 가진다. queue가 꽉차면 sender는 기다려야 하고, queue가 비어있으면 receiver가 기다려야 한다.
- Unbounded Capacity(무한용량): queue가 무한한 길이를 가진다. sender는 blocking 될 일이 없다. receiver만 queue가 비어있을 때 기다려야 한다.
마침
이번시간을 마지막으로 프로세스에 대한 기본적인 내용을 살펴봤습니다. 다음시간부터는 스레드에 대해서 공부해보도록 하겠습니다.
References
![]()
