🤚 전체적인 진행과정과 실습, 일부 내용은 핸즈온 머신러닝(2판), 한빛미디어 를 참고했다. 이 장에서의 목표는 캘리포니아의 인구조사 데이터를 사용해 주택가격 모델을 만드는 것이다.
colab 실습 주소 : https://colab.research.google.com/github/rickiepark/handson-ml2/blob/master/02_end_to_end_machine_learning_project.ipynb
데이터 이해를 위한 탐색과 시각화
DataFrame.plot 사용하기
DataFrame의 plot를 이용하면 다양한 형태의 그래프를 그릴 수 있다. (🔎공식문서 사용법)
- DatatFrame.plot.bar() : 막대 그래프
- DatatFrame.plot.lime() : 산 그래프
- DatatFrame.plot.scatter(x,y) : 산포도 그래프
- DatatFrame.plot.box() : Box 그래프
혹은 DatatFrame.plot(kind="그래프 종류", x, y) 도 가능하다.
실습1. 위경도에 따라 조사하기
저번시간에 strat_train_set까지 구했는데 이어서 작업하겠다.
import matplotlib.pyplot as plt
(...생략...)
housing = strat_train_set.copy() # 복사
# x축은 위도, y축은 경도를 나타내는 점 분포도를 그림
housing.plot(kind="scatter", x="longitude", y="latitude")
# 혹은 matplotlib.pyplot를 import해서 그릴수도 있다
# plt.scatter(housing["longitude"], housing["latitude"])
plt.show()
다만 아쉬운게 점이 몰려있는 부분 중에서 어디가 특히 몰려있는지 확인하기 힘들다. 이때는 투명도를 조절하면 된다.
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
plt.show()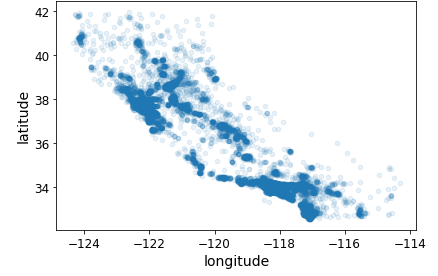
실습2. 위경도 + 주택가격
# 위도경도에 따른 산점도를 그리는거는 맞는데 추가적으로 s=housing["population"]/100를 통해
# 인구수에 따라서 점의 크기를 달리해서 표현했다
# 또한 c를 컬러를 나타낸다. 주택중간가격에 따라 색깔 표현을 달리해서 jet 표현방식을 사용해서 표현
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False)
plt.legend()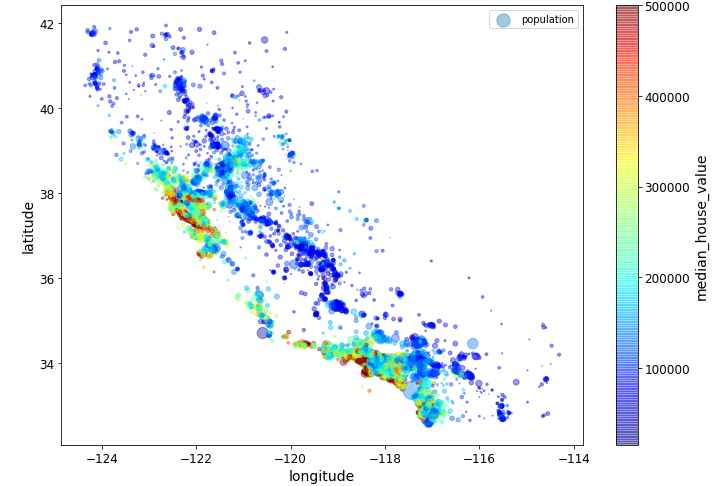
그래서 보자면 원이 좀 크게 그려졌으면 인구가 많은것이고, 빨간색으로 갈 수록 중간주택가격이 높은 것이다. 해안가 주변으로 사람들이 모여살며 주택가격이 높은것을 볼 수 있다.
상관관계 조사
corr_matrix = housing.corr()
# 중간주택가격을 기준으로 관계가 높은 순으로 정렬해서 나열해보도록 하겠다.
print(corr_matrix["median_house_value"].sort_values(ascending=False))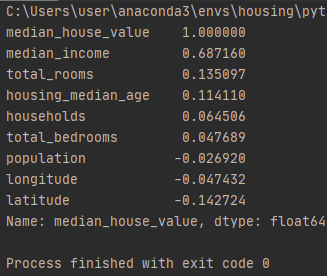
중간 주택가격과 다른 특성 사이의 상관관계 크기를 나타낸 결과이다. 상관관계는 -1 ~ 1까지 범위가 있는데 1에 가까우면 강한 상관관계. 0에 가까우면 전혀 관련없음. -1은 역상관관계를 나타낸다.
결과를 보면 중간주택가격과 중간소득은 상관관계가 제일 크다는 것을 알 수 있다. 관계가 있다는 소리이다. 아무래도 소득이 높으면 좋은 주택에서 살겠지?
중간 주택가격과 중간소득을 그래프를 통해 한번 보도록 해보자.
housing.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1)
plt.axis([0, 16, 0, 550000])
plt.show()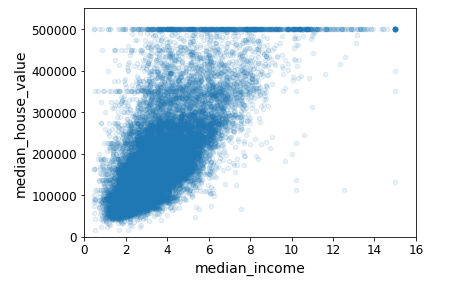
어느정도 일관성이 보이는 것을 알 수 있다. 다만 앞서 본 가격 제한값이 500,000에서 수평선으로 잘보인다. 따라서 이런 부분은 나중에 제거하는 것이 좋다.
특성조합으로 실험
머신러닝 알고리즘용 데이터를 준비하기전 마지막으로 해볼 수 있는 것은 여러 특성의 조합을 실험해보는 것이다.
예를 들어 아래와 같은 새로운 특성조합을 생각해볼 수 있지 않을까?
- 특정 구역의 방 개수는 얼마나 많은 가구 수가 있는지 모른다면 그다지 유용하지 않다. 진짜 필요한 것은 가구당 방의 개수이다.
- 비슷하게 전체 침실 개수도 그 자체로는 유용하지 않다. 즉, 방 개수와 비교하는 게 나을거같다.
- 가구당 인원도 흥미로운 특성 조합일거 같다.
이런 특성들을 만들어본다음 상관관계를 비교해보자.
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))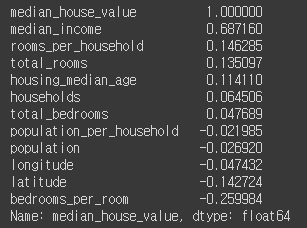
새로운 bedrooms_per_room 특성은 침실/방 비율이 낮은 집이 더 비싼 경향이 있다는 것을 보여주고 있다. 가구당 방 개수(rooms_per_household)도 구역 내 전체 방 개수(total_rooms)보다 더 유용하다.
✍ 이처럼 기존 특성보다 조합했을때 특성이 더 잘 상관관계를 보여주는 경우도 찾아볼 수 있다.
