🤚 전체적인 진행과정과 실습, 일부 내용은 핸즈온 머신러닝(2판), 한빛미디어 를 참고했다. 이 장에서의 목표는 캘리포니아의 인구조사 데이터를 사용해 주택가격 모델을 만드는 것이다.
colab 실습 주소 : https://colab.research.google.com/github/rickiepark/handson-ml2/blob/master/02_end_to_end_machine_learning_project.ipynb
예측변수와 레이블 분리
- 예측변수 : 위도, 경도, 중간소득, 해안 위치 등
- 레이블(정답값) : 중간주택가격
# drop을 통해 median_house_value를 삭제한 복사본을 만들어 반환 (원본에는 영향 없음)
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()데이터 정제
앞서 total_bedrooms 특성에 값이 없는 경우를 보았는데 이를 고쳐야한다. 방법은 3가지가 있다.
방법 1. 해당 구역을 삭제한다
방법 2. 전체 특성을 삭제한다
방법 3. 어떤 값으로 채운다. ex) 0, 평균, 중간값 등
# 옵션 1. total_bedrooms가 없는 구역을 삭제하므로 전체적으로 16354개 데이터가 남게됨
housing = housing.dropna(subset=["total_bedrooms"])
print(housing.info())# 옵션 2. 아예 그냥 total_bedrooms 자체를 없애버린다.
housing = housing.drop("total_bedrooms", axis=1) # axis=1 의미는 1은 열을 의미.
# 만약 행을 삭제하고 싶으면 housing.drop(행번호, axis=0) 이런식으로 해주면 된다.
print(housing.info())# 옵션 3. 중간값을 계산한 다음 total_bedrooms가 없는 부분을 중간값으로 대체.
# 따라서 16512개 데이터가 유지됨
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median, inplace=True)
print(housing.info())사이킷런 SimpleImputer
위 방법도 있지만 사이킷런을 이용하는 것도 한가지 방법이다. 사이킷런의 SimpleImputer는 누락된 값을 손쉽게 다루도록 해준다.
1단계. 객체 생성
from sklearn.impute import SimpleImputer
# 누락된 값을 특성의 중간값으로 대체한다는 설정하에 객체를 생성
# mean, most_frequent, constant(fill_value) 등 설정 가능
imputer = SimpleImputer(strategy="median") 2단계. 텍스트 특성 제외
텍스트 특성인 ocean_proximity은 중간값을 계산할 수 없기 때문에 제외해야 한다.
housing_num = housing.drop("ocean_proximity", axis=1)3단계. 중간값 계산
imputer.fit(housing_num)
print(imputer.statistics_) # 중간값
# [-118.51 34.26 29. 2119.5 433. 1164. 408. 3.5409]
# 수동으로 계산한 것과 같은지 비교해보자
print(housing_num.median().values)4단계. 누락된 값을 중간값으로 대체
X = imputer.transform(housing_num)5단계. 다시 pandas dataframe으로 변환
housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index)
print(housing_tr.info())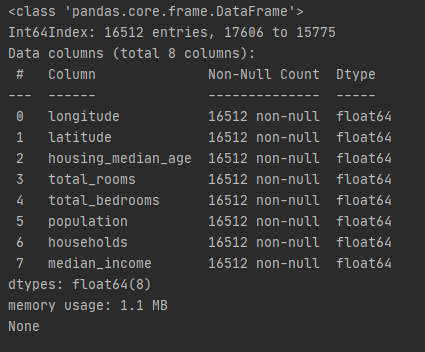
텍스트와 범주형 특성 다루기
지금까지는 수치형 특성만 다루었는데 ocean_proximity라는 텍스트 특성이 남아있다. 이 속성은 임의의 텍스트는 아니고 카테고리가 있는 범주형 특성을 가지고 있다. 대부분의 머신러닝 알고리즘은 숫자를 다루므로 이 카테고리를 텍스트에서 숫자로 변환시켜보도록 하겠다.
OrdinalEncoder 클래스
이를 위해서는 사이킷런의 OrdinalEncoder 클래스를 사용하면 된다.
from sklearn.preprocessing import OrdinalEncoder
# [[ ]] 를 사용한 이유는 데이터프레임을 반환하도록 하기위함
housing_cat = housing[["ocean_proximity"]]
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
print(housing_cat_encoded[:10])
print(ordinal_encoder.categories_)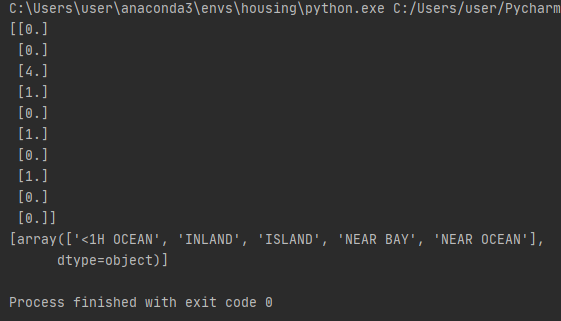
카테고리와 카테고리마다 숫자로 지정되어 변환된것을 알 수 있다. 예를 들어 NEAR OCEAN은 숫자 4, 1H OCEAN은 숫자 0으로 지정되어있다.
OneHotEncoder 클래스
하지만 위와 같은 표현방식에는 문제점이 있다. 🤷♂️ 바로 머신러닝 알고리즘이 가까이 있는 두개의 값이 떨어져있는 두개의 값보다 더 비슷하다고 생각한다는 점이다. 이 문제는 일반적으로 카테고리별 이진 특성을 만들어 해결한다. 한 특성만 1이고 나머지는 0이므로 이를 원-핫 인코딩(One-Hot Encoding)이라고 부릅니다.
사이킷런은 숫자로 된 범주형 값을 원-핫 벡터로 바꿔주는 OneHotEncoder 클래스를 제공하고 있다.
from sklearn.preprocessing import OneHotEncoder
housing_cat = housing[["ocean_proximity"]]
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
print(housing_cat_1hot.toarray())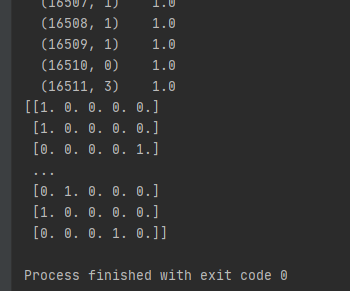
특이한점은 그냥 출력할때는 사이파이(Scipy) 희소 행렬 형태로 되어있다. 이는 수천 개의 카테고리가 있는 범주형 특성일 경우 매우 효율적이다. 이렇게 하는 이유는 원-핫 인코딩하면 열이 수천 개인 행렬로 변하고 각 행은 1이 하나뿐이고 그 외에는 모두 0으로 채워져 있을 것이다. 0을 모두 메모리에 저장하는 것은 낭비이므로 희소 행렬은 0이 아닌 원소의 위치만 저장하면 된다.
이 행렬을 거의 일반적인 2차원 배열처럼 사용할 수 있지만 우리가 보기 좋게 넘파이 배열로 바꾸려면 toarray() 함수를 호출하면 된다.
사용자 정의 변환기
저번시간에 특성조합으로 상관관계를 조사해봤었다. rooms_per_household(가구당 방의 개수), population_per_household(가구당 인원), bedrooms_per_room(침실/방 비율)이 있었다. 이런 특성을 계산한 다음 combine 하는 함수(변환기)를 만들어보도록 하자.
from sklearn.base import BaseEstimator, TransformerMixin
# 열 인덱스
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
# 사용자 정의 변환기
# BaseEstimator를 상송하면 하이퍼파라미터 튜닝에 필요한 메서드 get_params(), set_params()를 추가로 얻게 된다.
# TransformerMixin는 fit_transform() 메서드를 하나를 가지고 있으며 이를 제공한다. 단순히 fit()과 transform()을 연결한 것
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # 방 당 침실 수 특성을 추가할지 말지 결정
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None): # 아무것도 하지 않는다.
return self
def transform(self, X): # 특성을 계산해서 합쳐서 반환해줌
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.to_numpy())# 열 추가 후 pandas로 변환
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
# 결과 출력
housing_extra_attribs.head() 
특성 스케일링
데이터에 적용할 가장 중요한 변환 중 하나가 특성 스케일링(Feature Scaling)이다. 머신러닝 알고리즘은 입력 숫자 특성들의 스케일이 많이 다르면 잘 작동하지 않는다. 주택 가격 데이터도 이에 해당한다. 즉, 전체 방 개수의 범위는 6에서 39,320인 반면 중간 소득의 범위는 0에서 15까지이다. 단, 타깃 값에 대한 스케일링은 일반적으로 불필요하다.
모든 특성의 범위를 같도록 만들어주는 방법으로 min-max 스케일링(정규화, Normalization) 과 표준화(Standardization) 가 널리 사용된다.
- min-max 스케일링(정규화, Normalization) : 0~1 범위에 들도록 값을 이동하고 스케일을 조정하면 됩니다. 데이터에서 최소값을 뺀 후 최대값과 최소값의 차이로 나누면 이렇게 할 수 있습니다. 사이킷런에는 이에 해당하는 MinMaxScaler 변환기를 제공합니다. 0~1사이를 원하지 않는다면 feature_range 매개변수로 범위를 조정할 수 있습니다.
- 표준화(Standardization) : 먼저 평균을 뺀 후 표준편차로 나누어 결과 분포의 분산이 1이 되도록 합니다. 범위의 상한과 하한이 없어 어떤 알고리즘에서는 문제가 될 수 있습니다. 그러나 표준화는 이상치에 영향을 덜 받습니다. 사이킷런에는 표준화를 위한 StandardScaler 변환기가 있습니다.
변환 파이프라인
앞서 보았듯이 변환단계가 많다. SimpleImputer도 해야하지, 특성조합해야하지, 특성 스케일링해야하지, 원핫인코딩 해야지...😡 이것을 순서대로 처리할 수 있도록 도와주는 Pipeline 클래스가 있다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# SimpleImputer -> CombinedAttributesAdder -> StandardScaler 순서로 진행하도록 설정
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
print(housing_num_tr)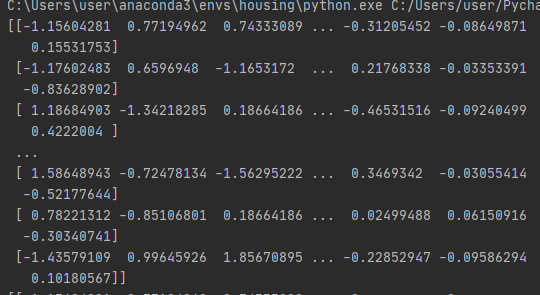
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
# ColumnTransformer는 각 열마다 다른 변환기를 사용할 수 있도록 해주는 클래스이다
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
print(housing_prepared)
print(housing_prepared.shape)
마침
코드를 자세히 이해하기 보다는 데이터를 어떻게 정제하고 변환하는지를 집중적으로 살펴보도록 하자.
- 데이터를 가져오고,
- 계층적 샘플링을 하고,
- 훈련용과 테스트용을 분리하고,
- 특성조합과 상관관계를 조사하고,
- 파이프라인을 구현해서 Null값을 중간값으로 대체하는 SimpleImputer와 특성조합을 추가하는 CombinedAttributesAdder와 표준화를 거쳐서 텍스트형 데이터 원핫인코더까지...
이런 과정을 왜 수행했는지 아는게 더 중요한거 아닐까? 싶다. 🤔
