SQL을 이용한 데이터 분석
- SELECT 배우기
Redshift 론치 데모
AWS 콘솔을 통해 Redshift를 론치해보자.
- Redshift 론치하고자 하는 지역이 내가 원하는 지역인지 확인한다.
- 서울에 있는 AWS 리전에서 Redshift 론치한다.
-
Redshift 클릭/검색해서 Redshift 콘솔로 이동한다.
-
create cluster
cluster configuration 클러스터 구성
- cluster identifier 클러스터 식별자: learnde
- cluster size: 가장 싼거 dc2.large
- node 개수: 1대
database configuration 데이터베이스 구성
- admin user name 관리자 이름: awsuser
- password
cluster permissions
additional configuration 외부에서 엑세스 가능하게
- 기본값 사용 off
- 퍼블릭 액세스 가능
end point 가지고 엑세스 한다.
예제 테이블
앞으로 실습에서 사용할 테이블들이다.
관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보
실습의 주제가 마케팅에 관련된 것이기 때문에, 이해하는데 필요한 사전 지식을 알아보자.
사용자 ID: 보통 웹서비스에서 등록된 사용자마다 부여하는 유일한 ID이다.
세션 ID: 세션마다 부여되는 ID이다.
- 세션: 사용자의 방문을 논리적인 단위로 나눈 것이다.
- 사용자가 외부 링크(보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성하는 방법과
- 사용자가 방문 후 30분간 interaction(활동)이 없다가 뭔가를 하는 경우 새로 세션을 생성하는 방법이 있다.
- 즉, 하나의 사용자는 여러 개의 세션을 가질 수 있다.
- 보통 세션의 경우 세션을 만들어낸 접점(경유지)를 채널이란 이름으로 기록해둔다.
- 주소창/북마크로 들어오면 접점이 없다(direct visit)
- 유튜브/인스타 광고로 들어오면 접점이 생긴다(채널)
- 마케팅 관련 기여도 분석을 위해 필요하다.
- 또한 세션이 생긴 시간도 기록한다.
정리하자면 세션이 생길 때 기록하는 정보는 다음과 같다.
- 사용자ID, 세션ID, 세션이 생긴 시간, 세션 만들어낸 채널 정보
이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능하다.
- 마케팅 관련, 사용자 트래픽 관련
- DAU, WAU, MAU 등의 일주월별 Active User 차트
- Active User: 그 기간동안 한번이라도 사이트 방문한 사람
- Marketing Channel Attribution 분석
- 어느 채널에 광고를 하는 것이 가장 효과적인가?
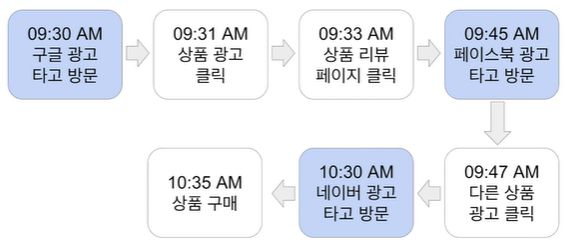
총 3개의 세션(파란 배경)을 갖는 예제 테이블을 살펴보자.
- 세션1: 구글 키워드 광고로 시작한 세션
- 세션2: 페이스북 광고를 통해 생긴 세션
- 앞의 세션과 30분이라는 시간이 안흘렀지만 외부에서 링크를 타고 새로 들어왔기 때문에 새로운 세션이 생성된다.
- 세션3: 네이버 광고를 통해 생긴 세션
- 상품 구매로 이어졌다.
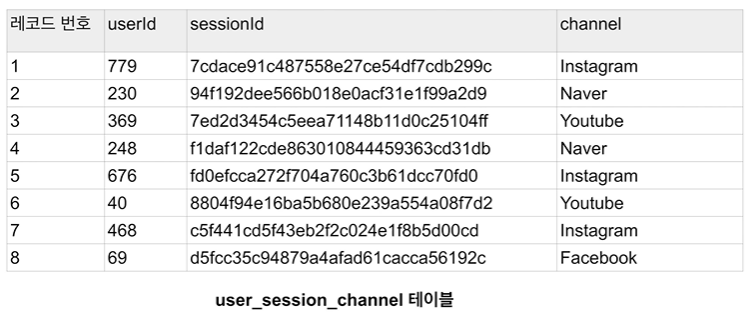
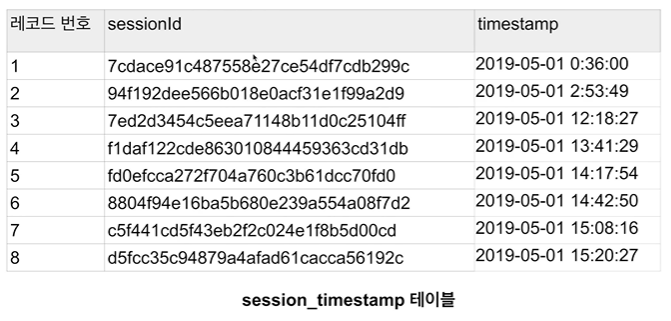
관계형 데이터베이스 예제: 데이터베이스와 테이블
두 개의 테이블이 있다.

- join key: sessionid
- primary key: sessionid
SQL 소개 (DDL과 DML)
SQL 기본
먼저 다수의 SQL 문을 실행한다면 세미콜론으로 분리해야 한다.
- SQL문1; SQL문2; SQL문3;
SQL 주석
- --: 인라인 한줄짜리 주석 (자바에서 //에 해당한다)
- : 여러 줄에 걸쳐 사용 가능한 주석
SQL 키워드는 대문자를 사용한다던지 하는 나름대로의 포맷팅이 필요하다.
- 팀 프로젝트라면 팀에서 사용하는 공통 포맷이 필요하다.
테이블/필드이름의 명명규칙을 정하는 것이 중요
- 단수형 vs. 복수형
- User vs. Users
- _ vs. CamelCasing
- user_session_channel vs. UserSessionChannel
SQL DDL - 테이블 구조 정의 언어
데이터를 생성, 수정, 삭제하는 등의 데이터의 전체적인 골격을 결정하는 역할을 한다.
CREATE TABLE
- Primary key 속성을 지정할 수 있으나 (여기선) 무시된다.
- Primary key uniqueness는 데이터웨어하우스에서는 지켜지지 않는다. (Redshift, Snowrlake, BigQuery)
- CTAS: CREATE TABLE table_name AS SELECT (테이블 정의와 동시에 내용 채운다)
- vs. CREATE TABLE and then INSERT
CREATE TABLE raw_data.user_session_channel (
userid int,
sessionid varchar(32) primary key,
channel varchar(32)
);DROP TABLE
- 테이블 자체가 사라진다.
DROP TABLE table_name;- 없는 테이블을 지우려고 하는 경우 에러를 낸다.
DROP TABLE IF EXISTS table_name;- vs.
DELETE FROMDELETE FROM은 조건에 맞는 레코드들을 지운다. (테이블 자체는 존재)
ALTER TABLE
- 새로운 컬럼 추가:
ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
- 기존 컬럼 이름 변경:
ALTER TABLE 테이블이등 RENAME 현재필드이름 to 새필드이름
- 기존 컬럼 제거:
ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
- 테이블 이름 변경:
ALTER TABLE 현재테이블이름 RENAME to 새테이블이름;
SQL DML - 테이블 데이터 조작 언어
정의된 데이터베이스에 입력된 레코드를 조회하거나 수정, 삭제하는 등의 역할을 한다.
SELECT
- 하나/다수의 테이블로부터 조건에 맞는 레코드 읽어오게 할 수 있다.
SELECT FROM: 테이블에서 레코드와 필드를 읽어오는데 사용된다.WHERE를 사용해서 레코드 선택 조건을 지정한다.GROUP BY를 통해 정보를 그룹 레벨에서 뽑는데 사용하기도 한다.- DAU, WAU, MAU 계산은
GROUP BY를 필요로 한다.
- DAU, WAU, MAU 계산은
- ORDER BY를 사용해서 레코드 순서를 결정하기도 한다.
레코드 수정 언어:
INSERT INTO: 테이블에 레코드를 추가하는데 사용UPDATE FROM: 테이블 레코드의 필드 값 수정DELETE FROM: 테이블에서 레코드를 삭제- vs.
TRUNCATE(transaction x)
- vs.
SQL 실습 환경 소개
실습에 들어가기에 앞서
처음 쓰는 데이터로 일을 하기 전에 꼭 염두해야 할 부분이다.
현업에서 깨끗한 데이터란 존재하지 않는다.
- 항상 데이터를 믿을 수 있는지 의심할 것!(의데이터증)
- 실제 레코드를 몇 개 살펴보는 것 만한 것이 없다 -> 노가다는 꼭 필요하다!
- 원하지 않는 결과가 나오면 실제로 내가 사용한 데이터들을 훑어보자.
데이터 일을 한다면 항상 데이터의 품질을 의심하고 체크하는 버릇이 필요하다.
- 중복된 레코드들 체크하기
- 믿고 쓸 수 있나?
- 최근 데이터의 존재 여부 체크하기 (freshness)
- timestamp 찾아서 확인하자.
- Primary key uniqueness가 지켜지는지 체크하기
- 값이 비어있는 컬럼들이 있는지 체크하기
위의 체크는 코딩의 unit test 형태로 만들어 매번 쉽게 체크해볼 수 있다.
- 코드로 만들어서 자동화
실습 환경 구축
주피터 SQL 엔진 설정
%load_ext sql버전 충돌 막기 위해 다운그레이드
- 재설치가 끝나면 하단에 Restart runtime 버튼 클릭하고 다시 처음부터 재실행해야 한다.
!pip install ipython-sql==0.4.1
!pip install SQLAlchemy==1.4.49RedShift의 데이터베이스와 연결
%sql postgresql://username:password@hostname/dbnamesql 코드 입력할 때 이런 식으로 위에 선언하고 한칸 띄우고 시작해야한다.
%%sql
SELECT ...SELECT
SELECT
- 테이블(들)에서 레코드들(혹은 레코드수)을 읽어오는데 사용한다.
- WHERE를 사용해 조건을 만족하는 레코드를 뽑아올 수 있다.
SELECT 필드이름1, 필드이름2,...
FROM 테이블이름
WHERE 선택조건
GROUP BY 필드이름1, 필드이름2, ...
ORDER BY 필드이름 [ASC|DESC] -- 필드 이름 대신에 숫자 사용 가능
- 오름차순|내림차순
LIMIT N;SELECT 예시
SELECT * -- 모든 필드 읽어오기
FROM raw_data.user_session_channel;SELECT DISTINCT channel -- 유일한 채널 이름을 알고싶은 경우
FROM raw_data.user_session_channel;SELECT channel, COUNT(1) -- 채널별 카운트를 하고 싶은 경우 COUNT 함수
FROM raw_data.user_session_channel
GROUP BY 1; -- channelSELECT COUNT(1) -- 테이블의 모든 레코드 수 카운트. COUNT(*). 하나의 레코드
FROM raw_data.user_session_channel;SELECT COUNT(1)
FROM FROM raw_data.user_session_channel
WHERE channel='Facebook'; -- channel 이름이 Facebook인 경우만 고려해서 레코드 수 카운트
CASE WHEN
필드 값의 변환을 위해 사용 가능하다.
- 여러 조건을 사용하여 변환하는 것도 가능하다.
CASE
WHEN 조건1 THEN 값1
WHEN 조건2 THEN 값2
ELSE 값3
END 필드이름SELECT
channel,
CASE
WHEN channel in ('Facebook', 'Instagram') THEN 'Social-Media'
WHEN channel in ('Google', 'Naver') THEN 'Search-Engine'
ELSE 'Something-Else'
END channel_type # 결과칼럼명
FROM raw_data.user_session_channel
LIMIT 100;NULL이란?
- 값이 존재하지 않음을 나타내는 상수이다. (0 혹은 "" 과는 다르다)
- 필드 지정시 값이 없는 경우 NULL로 지정 가능하다.
- 테이블 정의시 디폴트 값으로도 지정 가능하다.
- 어떤 필드의 값이 NULL인지 아닌지 비교는 특수한 문법을 필요로 한다.
field1 is NULL혹은field1 is not NULL
- NULL이 사직연산에 사용되면 그 결과는? 모든 결과는 null이 된다
- SELECT 0 + NULL, 0 - NULL, 0 * NULL, 0/NULL
COUNT 함수
COUNT 함수를 제대로 이해하기 위해 레코드가 7개인 테이블을 생각해 보자.
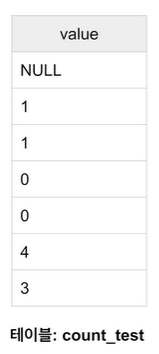
- SELECT COUNT(1) FROM count_test
- 7
- SELECT COUNT(NULL) FROM count_test
- 0
- 왜? COUNT 함수는 인자로 들어온 값이 NULL이면 안세고, NULL이 아니면 센다.
- SELECT COUNT(value) FROM count_test
- 6
- SELECT COUNT(DISTINCT value) FROM count_test
- 4
- DISTINCT는 unique한 값들만 센다.
WHERE
IN
LIKE and ILIKE
- 대소문자 구별하면
LIKE, 대소문자 구별하지 않으면ILIKE쓰면 된다.
BETWEEN
위의 오퍼레이터들은 CASE WHEN 사이에서도 사용가능하다.
STRING Functions
LEFT(str, N)REPLACE(str, exp1, exp2)UPPER(str)LOWER(str)LEN(str)LPAD, RPADSUBSTRING
%%sql
SELECT
LEN(channel),
UPPER(channel),
LOWER(channel),
LEFT(channel, 4)
FROM raw_data.user_session_channel
LIMIT 100;ORDER BY
- Default ordering is ascending
ORDER BY 1 ASC
- Descending requires "DESC"
ORDER BY 1 DESC
- Ordering by multiple columns:
ORDER BY 1 DESC, 2, 3
- NULL 값 순서는?
- NULL 값들은 오름차순일 경우(ASC), 마지막에 위치한다.
- NULL 값들은 내림차순일 경우(DESC), 처음에 위치한다.
- 이를 바꾸고 싶다면
NULLS FIRST혹은NULLS LAST를 사용하면 된다.
Type Casting
숫자 계산할때 많이 쓰인다.
프로그래밍에서 1/2의 결과는?
- 0이 된다. (정수간의 연산은 정수가 되어야하기 때문)
- 분자나 분모 중의 하나를 float로 캐스팅해야 0.5가 나온다.
- 이는 프로그래밍 언어에서도 일반적으로 동일하게 동작한다.
:: 오퍼레이터 사용
category::float
cast 함수를 사용
cast(category as float)
%%sql
SELECT 1/2, 1/2::float;판다스와 연동하는 방법
result = %sql SELECT * FROM raw_data.user_session_channel
df = result.DataFrame()