시작하기에 앞서서...
SQL이 왜 중요할까?
데이터 직군은 크게 세가지로 나눌 수 있으며, 각 직군이 요구하는 스킬은 다음과 같다.
- 데이터 엔지니어
- 파이썬, 자바/스칼라
- SQL, 데이터베이스
- ETL/ELT(Airflow, DBT)
- Spark, Hadoop(빅데이터)
- 데이터 분석가
- SQL, 비지니스 도메인에 대한 지식
- 세가지 직군 중에서 SQL이 가장 중요한 직군 (물론 나머지도 SQL 없이는 제대로 수행 불가능!)
- 통계(AB 테스트 분석)
- SQL, 비지니스 도메인에 대한 지식
- 데이터 과학자
- 머신러닝
- SQL, 파이썬
- 통계
데이터 직군에서 일하기 위해 SQL은 필수다!
관계형 데이터베이스
관계형 데이터베이스란?
구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지이다.
-
엑셀 스프레드시트 형태의 테이블로 데이터를 정의하고 저장한다고 생각하면 된다.
- 테이블에는 컬럼(열, 스키마)과 레코드(행)이 존재한다.
-
관계형 데이터베이스를 조작하는 프로그래밍 언어가 SQL이다.
-
SQL문은 크게 두가지 종류로 나뉜다.
- 테이블 정의를 위한 DDL(Data Definition Language)
- 테이블 데이터 조작/질의를 위한 DML(Data Manipulation Language)
데이터 분석가의 관점에서 SQL을 자세하게 배워보자!
대표적 관계형 데이터베이스
✅프로덕션 데이터베이스: MySQL, PostgreSQL, Oracle, ...
- OLTP(OnLine Transaction Processing)
- 빠른 속도에 집중하며(빠르게 응답 못해주면 사용자가 기다려야 하기 때문에) 서비스에 필요한 정보를 저장한다.
- 웹서비스나 모바일 앱과 바로 연동이 되어서 서비스에 필요한 정보 저장하고 읽어오는데 사용이 된다.
- 백엔드, 프론트엔드가 사용
✅데이터 웨어하우스: Redshift, Snowflake, BigQuery, Hive, ...
- OLAP(OnLine Analytical Processing)
- 처리 데이터 크기에 집중(빠른 속도보다 더 중요하다), 데이터 분석 혹은 모델 빌딩등을 위한 데이터 저장
- 보통 프로덕션 데이터베이스를 복사해서 데이터 웨어하우스에 저장(데이터 엔지니어가 프로덕션 데이터베이스까지 접근 안해도 되게)
- 데이터 엔지니어, 과학자가 사용
회사가 작은 경우 보통 프로덕션 데이터베이스만 있다.
- 필요한 데이터가 다 여기에 있다.
- 서비스에 연동이 되어 있기 때문에 쿼리 날려서 느려지면 서비스 전체에 영향을 미친다. (벡엔드가 기분나빠 할 수 있다!)
- 스타트업에서 자주 발생하는 문제로, 별도의 데이터베이스가 필요한 이유이다.
- 데이터 웨어하우스 없는 회사면 고생할 확률이 더 높다 :)
관계형 데이터베이스의 구조
관계형 데이터베이스는 2단계로 구성된다.
- 가장 밑단에는 테이블들이 존재한다. (테이블은 엑셀의 시트에 해당)
- 테이블들은 데이터베이스(혹은 스키마)라는 폴더 밑으로 구성된다. (엑셀에서는 파일)
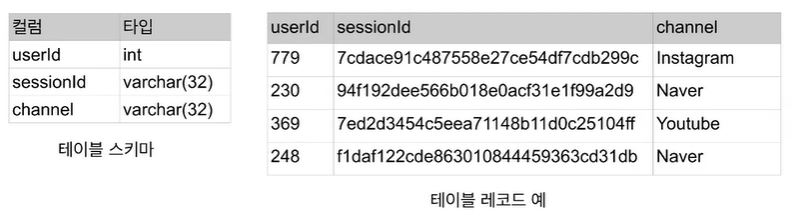
테이블의 구조 (테이블 스키마라고 부르기도 한다)
- 테이블은 레코드들로 구성된다.(행)
- 레코드는 하나 이상의 필드(컬럼)로 구성된다.(열)
- 필드(컬럼)는 이름과 타입과 속성(primary key)으로 구성됨
- primary key: 유일해야 한다, 동일한 값 하나밖에 없어야 한다. 같은 값 추가되면 막는다.
- 테이블 스키마에 맞춰서 레코드 추가하면 된다.
SQL
SQL 소개
SQL은 Structured Query Language의 약자로 관계형 데이터베이스에 있는 데이터(테이블)를 질의하거나 조작해주는 언어이다.
- 1970년대 초반에 IBM이 개발했다.
두 종류의 언어로 구성된다.
- DDL(Data Definition Language)
- 테이블의 구조를 정의하는 언어
- DML(Data Manipulation Language)
- 테이블에서 원하는 레코드들을 읽어오는 질의 언어
- 테이블에 레코드를 추가/삭제/갱신해주는데 사용하는 언어
SQL은 빅데이터 세상에서도 중요하다!
- 구조화된 데이터를 다루는 한 SQL은 데이터 규모와 상관없이 쓰인다.
- 모든 대용량 데이터 웨어하우스는 SQL 기반이다.
- Redshift, Snowflake, BigQuery, Hive
- 따라서 SQL은 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술이다.
SQL의 단점
SQL은 구조화된 데이터를 다루는데 최적화가 되어 있기 때문에 비구조화된 데이터에 대해서는 제약이 심하다.
- 많은 관계형 데이터베이스들이 플랫한 구조만 지원한다. (JSON과 같은 중첩 구조 X)
- 구글 빅쿼리는 중첩구조를 지원한다.
- 비구조화된 데이터를 다루는데 Spark, Hadoop과 같은 분산 컴퓨팅 환경이 필요해진다.
- 즉, SQL만으로는 비구조화 데이터를 처리하지 못한다.
- 관계형 데이터베이스마다 SQL 문법이 조금씩 상이하다.
스키마의 종류
어떤 형태로 모델링 할것이냐(데이터를 어떻게 표현할 것인가) 에는 크게 두가지 방법이 있다.
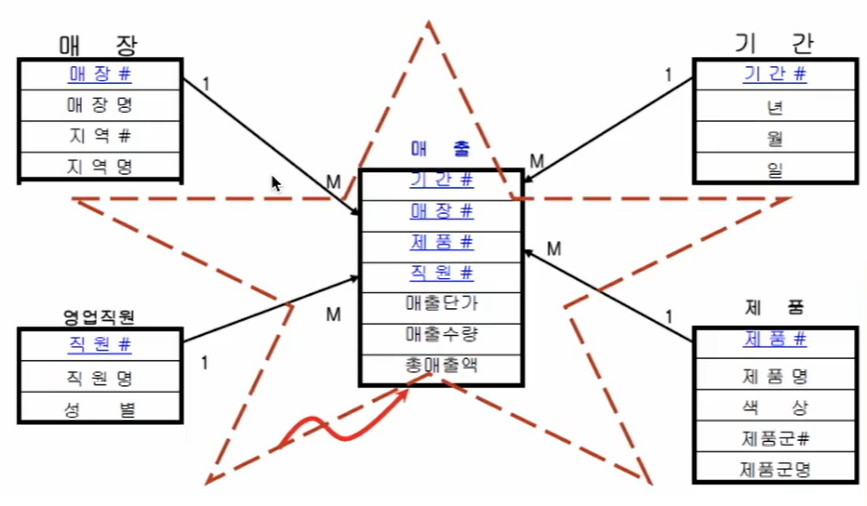
✅Star Schema
- Production DB용 관계형 데이터베이스에서는 보통 스타 스키마를 사용해 데이터를 저장한다.
- 데이터를 논리적 단위로 나눠 저장하고 필요시 조인한다.
- 스토리지의 낭비가 덜하고 업데이트가 쉽다.
- ID 형태로 링크를 건다. (조인 - 다수의 테이블들을 특정 키를 가지고 매핑한다)
- 시간이 더 걸릴 뿐 만 아니라 리소스도 더 필요하다.
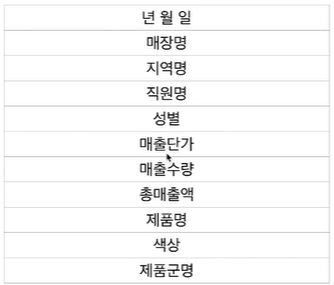
✅Denormalized Schema
- 데이터 웨어하우스에서 사용하는 방식이다.
- 단위 테이블로 나눠 저장하지 않음으로 별도의 조인이 필요 없는 형태를 말한다.
- 이는 스토리지를 더 사용하지만 조인이 필요 없기에 빠른 계산이 가능하다.
데이터 웨어하우스란?
데이터 웨어하우스
회사에 필요한 모든 데이터를 저장한다.
- SQL 기반의 관계형 데이터베이스이다.
- 프로덕션 데이터베이스와는 별도이어야 한다. (복사본으로)
- OLAP(OnLine Analytical Processing) vs. OLTP(Online Transaction Processing)
- AWS의 Redshift, Google Cloud의 Big Query, Snowflake 등이 대표적이다. (Redshift보다 Big Query나 Snowflake가 사용법도 별 차이 없으며 더 좋다)
- 고정비용 옵션 vs. 가변비용 옵션
- 프로덕션 데이터베이스와는 별도이어야 한다. (복사본으로)
- 데이터 웨어하우스는 고객이 아닌 내부 직원을 위한 데이터베이스이다.
- 처리속도가 아닌 처리 데이터의 크기가 더 중요해진다.
- ETL 혹은 데이터 파이프라인
- 외부에 존재하는 데이터를 읽어다가 데이터 웨어하우스의 테이블로 저장해주는 코드들이 필요해지는데 이를 ETL 혹은 데이터 파이프라인이라고 부른다.
ETL이란?
ETL은 추출(Extract), 변환(Transform), 로드(Load)를 나타낸다.
기업이 전 세계 수많은 팀에서 관리하는 전체 데이터를 가져와 비즈니스 목적에 실질적으로 유용한 상태로 변환하는 end-to-end 프로세스를 의미한다.
- 데이터 웨어하우스로 이전하는데 사용되는 것은 ETL 사용 사례 중 하나
데이터 인프라
- 데이터 웨어하우스, ETL 등을 통틀어 데이터 인프라라고 부른다.
- 데이터 엔지니어가 관리한다.
- 여기서 한 단계 더 발전하면 Spark과 같은 대용량 분산처리 시스템이 일부로 추가된다.
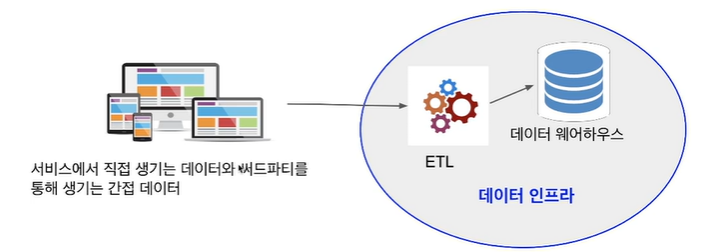
- 여기서 한 단계 더 발전하면 Spark과 같은 대용량 분산처리 시스템이 일부로 추가된다.
데이터 순환 구조
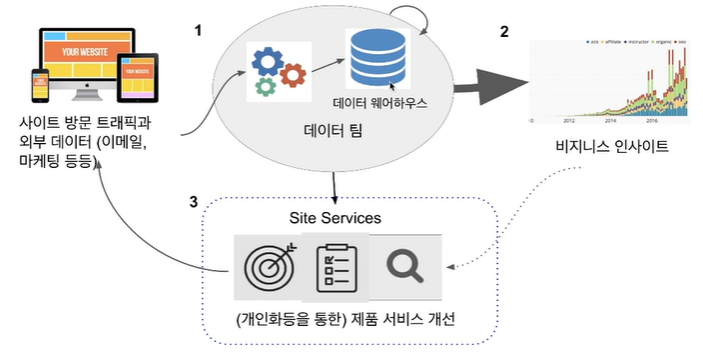
Cloud와 AWS 소개
클라우드의 정의
컴퓨팅 자원(하드웨어, 소프트웨어 등)을 네트워크를 통해 서비스 형태로 사용하는 것이다.
키워드:
- "No Provisioning" 준비할 게 없다 - 원하는 사양 선택하면 바로 준비가 된다.
- "Pay As You Go" 쓴 만큼 돈을 지불한다.
자원(예를 들면 서버)을 필요한만큼 (거의) 실시간으로 할당하여 사용한 만큼 지불한다.
- 탄력적으로 필요한만큼의 자원을 유지하는 것이 중요하다.
- 클라우드가 비싸다고 느껴진다면, 탄력적으로 운영 하기 힘들기 때문에 필요 이상으로 자원 할당해서 지출이 커지기 때문인지 고민해봐야 한다. (실제로 비싸기도 하다)
클라우드 컴퓨팅의 장점
- 초기 투자 비용이 크게 줄어든다.
- CAPEX(Capital Expenditure) vs. OPEX(Operating Expense)
- 리소스 준비를 위한 대기시간이 대폭 감소한다. (기회비용 이점)
- Shorter Time to Market
- 노는 리소스 제거로 비용이 감소한다.
- 글로벌 확장 용이하다.
- 소프트웨어 개발 시간이 단축된다.
- Managed Service (SaaS) 이용
AWS 소개
가장 큰 클라우드 컴퓨팅 서비스 업체이다.
- 2002년 아마존의 상품데이터를 API로 제공하면서 시작하였다.
- 현재 100여개의 서비스를 전세계 15개의 지역에서 제공한다.
- 대부분의 서비스들이 오픈소스 프로젝트들을 기반으로 한다.
- 최근 들어 ML/AI 관련 서비스들도 내놓기 시작했다.
- 사용고객
- Netflix, Zynga등의 상장업체들도 사용하며
- 많은 국내 업체들도 사용을 시작했다. (서울 리전을 개설했다)
- 다양한 종류의 소프트웨어/플랫폼 서비스를 제공한다.
- AWS의 서비스만으로 쉽게 온라인서비스를 생성할 수 있다.
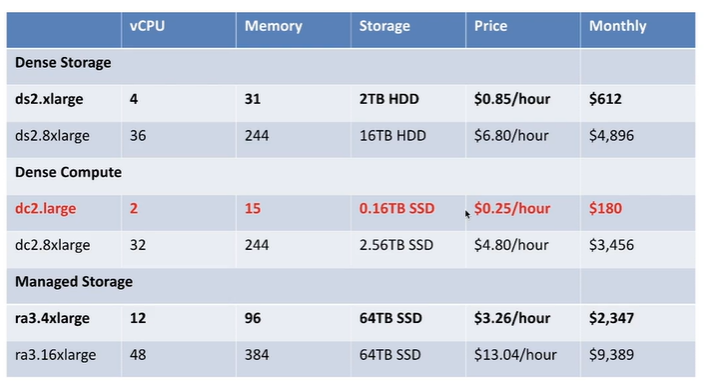
6. Redshift 소개
Redshift: Scalable SQL 엔진
- 2 PB까지 지원한다.
- 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용할 수 없다.
- Columnar Storage
- 컬럼별 압축이 가능하다.
- 컬럼을 추가하거나 삭제하는 것이 아주 빠르다.
컬럼 압축은 왜하는 걸까?
- 큰 필드의 액세스 빈도가 낮은 경우, 읽기 및 쓰기 액세스 시 리소스의 낭비가 일어난다.
- 액세스 빈도가 높은 다른 필드들의 속도를 높일 수 있다.
Columnar Storage란?
- 컬럼 지향 데이터베이스는 데이터를 컬럼 단위로 묶어서 저장한다.(전통적인 데이터베이스는 전체 로우가 연속적으로 저장)
- 특정 쿼리에 대해서는 로우의 모든 데이터가 필요하지 않다는 가정에 기반한다. (ex. MIN, MAX, SUM, COUNT)
- 컬럼 단위의 값은 데이터가 유사할 가능성이 높기 때문에 높은 압축률을 얻을 수 있다.
- 벌크 업데이트 지원 (INSERT 제한)
- SQL의 INSERT 명령어를 사용하면 오래 걸려서 바람직한 방법이 아니다.
- 따라서 레코드가 들어있는 파일을 S3로 복사 후 COPY 커맨드로 Redshift로 일괄 복사하는 벌크 업데이트를 사용해야 한다.
- 고정 용량/비용 SQL 엔진
- 장점: 비용이 예상된다.
- 단점: 더 많은 연산 하면 느리게 된다.
- vs. Snowflake vs. BigQuery (쓴 만큼 비용, 비용 예산 힘듦)
- 다른 데이터 웨어하우스처럼 primary key uniqueness를 보장하지 않는다.
- 보장하려면 레코드 추가될때마다 값이 유일하게 존재하는지 체크해야한다.
- 속도가 안나온다.
- 보장하려면 레코드 추가될때마다 값이 유일하게 존재하는지 체크해야한다.
- Redshift는 PostgreSQL 8.x와 SQL이 호환된다.
- 하지만 PostgreSQL 8.x의 모든 기능을 지원하지는 않는다.
- PostgreSQL 8.x를 지원하는 툴이나 라이브러리로 액세스 가능하다.
- JDBC/ODBC
Redshift Options and Pricing