9/20 CUBRID : cubridebook설치 / 시작 리뷰 이후 내용을 정리합니다.
CUBRID DBMS 구조
메모리 용량을 확보할 수 있는 여러가지 방법
CUBRID에 존재하는 '볼륨'은 파일형태입니다. 파일은 디스크에 저장되고, 따라서 메모리를 줄일 수 없습니다. 반면 서버 프로세스의 데이터/로그 버퍼는 메모리입니다. 메모리에 저장하는 이유는 빠르게 정보를 가지고 올 수 있도록 하기 위해서 인데요. 그렇기 때문에 데이터/로그 버퍼 사이즈를 줄이면 메모리가 줄어듭니다.
CAS 프로세스는 메모리를 사용합니다. 따라서 CAS 개수를 조정하면 메모리 공간을 확보 할 수 있습니다. MIN_NUM_APPL_SERVER, MAX_NUM_APPL_SERVER 는 각각 CAS 최소,최대 개수를 지정합니다. MIN_NUM_APPL_SERVER는 해당 브로커에 대한 연결 요청이 없더라도 기본적으로 대기하고 있는 CAS 프로세스의 최소 개수를 설정하는 파라미터이며, MAX_NUM_APPL_SERVER는 해당 브로커에 동시 접속할 수 있는 CAS의 최대 개수를 설정하는 파라미터입니다. MAX를 설정하는 것은 cubrid에서 일정이상의 CAS 를 할당하는 (메모리과잉할당) 것을 줄이기 위함이고, MIN을 설정하는 것은 broker에서 CAS를 할당하는 리소스를 줄이기 위해서 미리 일정 개수의 CAS를 설정하는 것입니다.
max_clients는 데이터베이스 서버에 동시 연결을 허용하는 클라이언트(일반적으로 브로커 용용 서버(CAS))의 최대 개수를 지정하기 위한 파라미터이다. 즉, max_clients 파라미터는 데이터베이스 서버 프로세스 하나당 동시에 접속할 수 있는 클라이언트의 최대 개수를 의미합니다. 따라서, max_clients는 수를 줄이는 것도 메모리 용량을 줄이는 방법이 될 수 있습니다. max_clients는 각 브로커의 MAX_NUM_APPL_SERVER 설정 값을 모두 합한 값에 10을 더하여 설정한다
sort_buffer_size는 정렬을 수행하는 질의에서 사용되는 버퍼의 크기를 설정하기 위한 파라미터입니다. 서버는 각 클라이언트의 정렬 요청마다 하나의 정렬 버퍼를 할당하며, 정렬을 완료한 후에는 할당되었던 버퍼 메모리를 해제합니다. sort_buffer_size는 가장 먼저 CAS 에게 할당됩니다. 따라서, 이 값과 CAS 개수를 적절히 맞춰주는 것도 메모리량을 조절하는 방법이 될 수 있습니다.
메모리 관련 파라미터
data_buffer_size
- data_buffer_size는 데이터베이스 서버가 메모리 내에 캐시하는 데이터 버퍼의 크기를 설정하기 위한 파라미터이다.
- data_buffer_size 파라미터의 값이 클수록 버퍼에 캐시되는 데이터 페이지가 많아지므로 디스크 I/O 비용을 줄일 수 있다는 장점이 있다. 반면, 이 파라미터의 값을 너무 크게 설정하면 과도하게 시스템 메모리가 점유되므로 운영체제에 의해 버퍼 풀이 스와핑(swapping)되는 현상이 발생할 수 있다. data_buffer_size 파라미터는 필요한 메모리 크기가 시스템 메모리의 2/3 이내가 되도록 설정할 것을 권장한다.
- 필요한 메모리 크기 = 데이터 버퍼 크기(data_buffer_size)
index_scan_oid_buffer_size
- index_scan_oid_buffer_size는 인덱스 스캔을 수행할 때 OID 리스트의 임시 저장을 위한 버퍼의 크기를 설정하기 위한 파라미터이다. 기본값은 4 * db_page_size (db_page_size가 16K일 때 64K)이다.
- index_scan_oid_buffer_size 파라미터 값과 데이터베이스 생성 시 설정한 단위 페이지의 크기에 비례하여 OID 버퍼의 크기가 결정되고, 이러한 OID버퍼의 크기가 클수록 인덱스 스캔 비용이 증가하는 경향을 보인다. 이를 고려하여 index_scan_oid_buffer_size 파라미터 값을 조정할 수 있다.
max_agg_hash_size
- max_agg_hash_size는 집계를 포함하는 질의에서 투플 그룹을 해싱하기 위해 할당한 트랜잭션 당 최대 메모리 크기를 설정하는 파라미터
sort_buffer_size
- sort_buffer_size는 정렬을 수행하는 질의에서 사용되는 버퍼의 크기를 설정하기 위한 파라미터이다. 서버는 각 클라이언트의 정렬 요청마다 하나의 정렬 버퍼를 할당하며, 정렬을 완료한 후에는 할당되었던 버퍼 메모리를 해제한다. 정렬을 수행하는 질의로는 SELECT 정렬 질의 뿐만 아니라 인덱스 생성 질의도 포함된다.
temp_file_memory_size_in_pages
- temp_file_memory_size_in_pages는 질의에 관한 임시 결과를 캐시하는 버퍼 페이지 개수를 설정하기 위한 파라미터
필요한 메모리 크기 = 임시 메모리 버퍼 페이지 수(temp_file_memory_size_in_pages) * 데이터베이스 페이지 크기(page size)임시 메모리 버퍼 페이지 수 = temp_file_memory_size_in_pages 파라미터 설정값데이터베이스 페이지 크기 = 데이터베이스 생성 시 cubrid createdb 유틸리티의 -s 옵션에 의해 지정된 페이지 크기 값thread_stacksize
- thread_stacksize는 스레드의 스택 크기를 설정하기 위한 파라미터로 기본값은 1048576 바이트이다. thread_stacksize 파라미터의 설정값은 운영체제가 허용하는 스택 크기를 초과할 수 없다.
디스크 용량을 확보할 수 있는 여러가지 방법
[centos@서버1 ~]$ du -sh ~cubrid19
7.7M /home1/cubrid19
[centos@서버1 ~]$ du -sh ~cubrid20
4.0K /home1/cubrid20리눅스에서 계정을 생성하면 각 계정마다 디스크 공간 차지합니다. 따라서, 여러개의 cubrid 계정들 중 몇 개를 삭제하거나, 각 계정 안의 안쓰는 파일들을 정리하여 디스크 공간을 확보할 수 있습니다.
또한 CUBRID의 볼륨파일은 디스크에 저장되므로 볼륨 값들을 조정할 수 있는 파라미터를 조절하면 디스크 공간을 확보할 수 있습니다.
디스크 용량 관련 파라미터
db_volume_size
- db_volume_size는 다음과 같은 값을 설정하는 파라미터이다. 값 뒤에 B, K, M, G, T로 단위를 붙일 수 있으며, 각각 Bytes, Kilobytes, Megabytes, Gigabytes, Terabytes를 의미한다. 단위를 생략하면 바이트 단위가 적용된다. 기본값은 512M이다.
- cubrid createdb와 cubrid addvoldb 유틸리티에서 --db-volume-size 옵션을 생략했을 때 생성되는 데이터베이스 볼륨의 기본 크기
- 데이터베이스 볼륨 공간을 모두 사용하면 자동으로 추가되는 범용(generic) 볼륨의 기본 크기
dont_reuse_heap_file
- dont_reuse_heap_file은 테이블 삭제(DROP TABLE)로 인해 삭제된 힙 파일을 새로운 테이블 생성(CREATE TABLE) 시 재사용하지 않도록 설정하는 파라미터로, no로 설정되면 삭제된 힙 파일을 재사용하고, yes로 설정되면 삭제된 힙 파일을 새로운 테이블 생성 시 재사용하지 않는다. 기본값은 no이다.
generic_vol_prealloc_size
- generic 볼륨이 항상 유지해야 할 여유 공간(free space)의 크기를 지정한다. 여유 공간이 지정한 값보다 줄어들게 되면 generic 볼륨의 여유 공간을 추가로 확보한다.
- 여유 공간의 검사는 generic, data, 또는 index 볼륨에 대한 새로운 페이지 요청이 있을 때만 이루어진다.
log_volume_size
- log_volume_size는 cubrid createdb 유틸리티에서 --log-volume-size 옵션이 생략되었을 때 로그 볼륨 파일의 기본 크기를 설정하는 파라미터이다.
temp_file_max_size_in_pages
- temp_file_max_size_in_pages는 질의 또는 인덱스 생성 등을 위해 데이터를 정렬하는 과정에서 중간 결과 및 최종 결과를 저장하기 위해 일시적 임시 볼륨(temporary temp volume)이 사용될 때, 질의 하나가 수행될 때 사용할 수 있는 임시 공간의 최대 크기를 페이지 개수로 명시하는 파라미터로 기본값은 -1이다.
- 중간 결과 저장소의 크기와 최종 결과 저장소의 크기는 각각 별개로 측정되므로, 그들 중 하나의 크기가 파라미터가 명시한 크기보다 큰 경우 에러가 발생하면서 해당 질의의 수행이 취소된다. 기본값으로 설정되면 temp_volume_path 파라미터에서 지정된 디스크 공간 이내에서 무제한으로 일시적 임시 볼륨(temporary temp volume)이 저장되고, 0으로 설정되면 일시적 임시 볼륨이 생성되지 않는다.
- 질의 수행 시 필요한 임시 볼륨(temp volume)은 일시적 임시 볼륨과 영구적 임시 볼륨으로 구분되는데, 이 파라미터의 값은 일시적 임시 볼륨에만 적용된다. (큰 크기의 임시 공간이 필요한 질의를 수행하면서 일시적 임시 볼륨이 기대 이상으로 증가함으로 인해) 디스크의 여유 공간이 부족해져 시스템 운영에 문제가 발생하는 것을 예방하려면, 예상하는 영구적 임시 볼륨을 미리 확보하고, 하나의 질의가 수행될 때 일시적 임시 볼륨에서 사용되는 공간의 최대 크기를 제한하는 것이 좋다.
temp_volume_path
- temp_volume_path는 복잡한 질의문이나 정렬 수행을 위하여 자동으로 생성되는 일시적 임시 볼륨(temporary temp volume)의 디렉터리를 지정하는 파라미터로 기본값은 데이터베이스 생성 시에 설정된 볼륨 위치이다.
volume_extension_path
- volume_extension_path는 cubrid addvoldb 유틸리티로 추가 볼륨을 생성할 때 추가 볼륨의 경로를 지정하는 -F 옵션을 생략하면 기본 경로로 사용할 경로를 지정하는 파라미터이다. 기본값은 데이터베이스 생성 시에 설정된 볼륨 위치이다.
브로커 목적에 따른 다중화?이중화?
브로커 다중화 : 서비스운영을 위해 (부하분산)
브로커 이중화 : 장애대비
CUBRID 공부 꿀팁
- DBMS 구조 이미지와 파일이 연결될 수 있도록 연상하기
- 일부러 오류내서 에러로그 확인해보기(sort_buffer_size 에 따른 cas 할당 테스트)
- 롤체인지 테스트 해보기
- 현재 운영에서 사용되는 자동 설치 스크립트에 대한 내용을 확인하고 수동으로 진행해보기
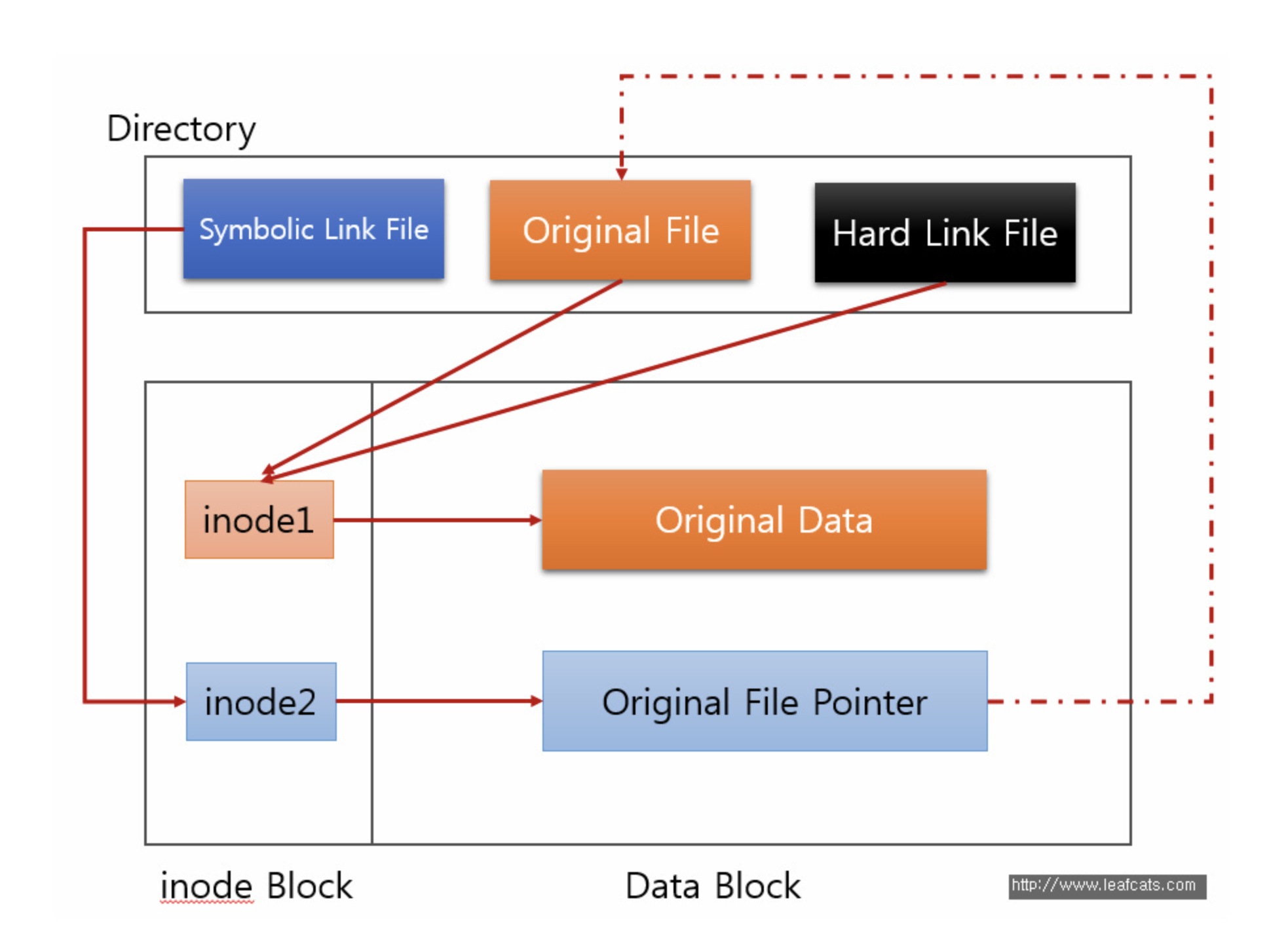
모든 파일과 디렉터리는 한개씩 inode 를 가지고 있다. 그리고 여기에는 해당 파일의 허가권, 소유권, 파일의 실제 위치 등 중요한 정보들이 들어있다.
하드링크 vs 소프트링크
하드링크
원본 파일로 하드 링크를 만들면, 하드 링크는 원본 파일과 동일한 inode를 직접적으로 가리킨다. 따라서 원본 파일이 사라지더라도 데이터만 살아 있다면 원본 파일에 접근이 가능하다.
소프트링크(심볼릭링크)
소프트 링크의 경우는 만들게 되면 또 다른 inode를 생성해서 이를 바라본다. 복사 생성된 inode는 포인터를 카리키고, 포인터는 다시 원본 파일을 가리킨다. 따라서 특정 데이터에 접근할 때, 심볼릭 링크를 통해 접근할 경우 다시 원본 파일을 거치게 된다. 때문에 원본 파일이 사라질 경우 해당 데이터에 접근할 수 없다.
참고링크
