1장 : 설치
2장 : 시작
큐브리드 프로세스
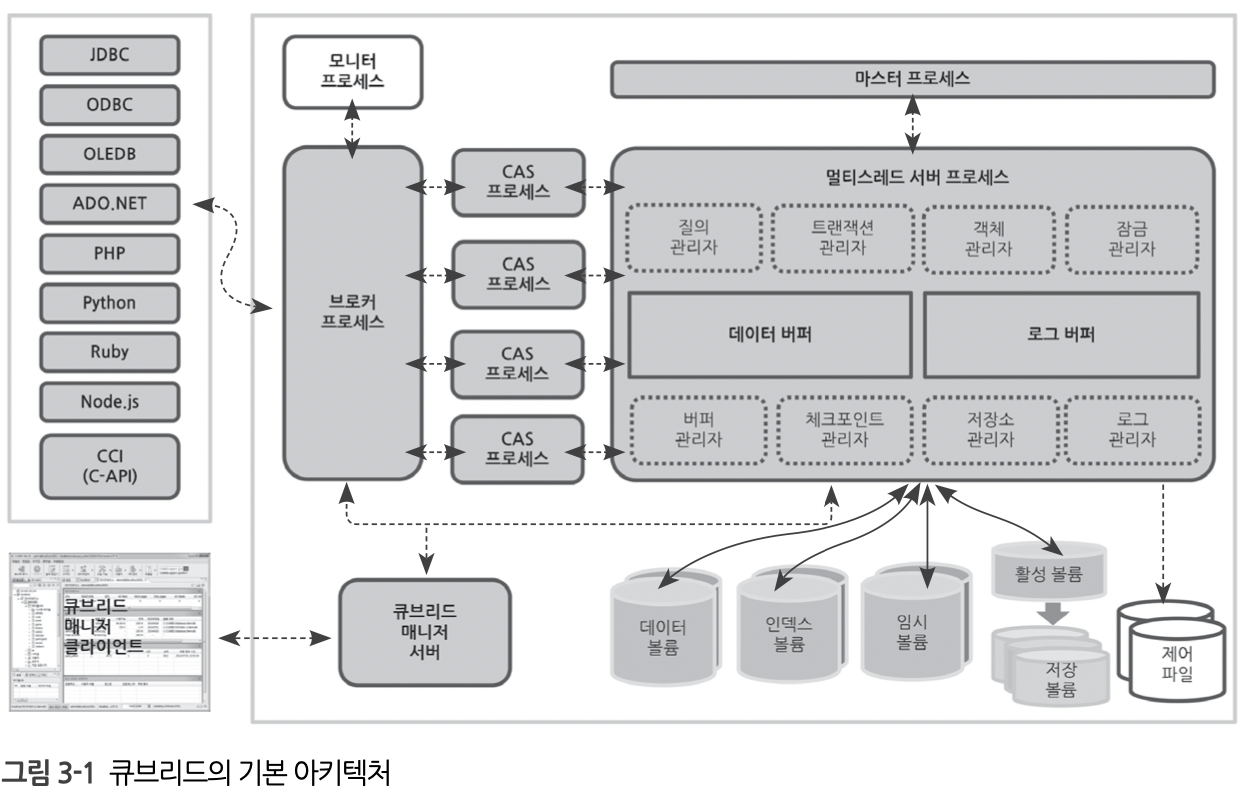
프로세스별 동작 과정
1. 마스터 프로세스
- 큐브리드를 시작하면 마스터 프로세스가 가장 먼저 시작된다.
- 마스터 프로세스는 브로커 응용 서버(CAS)와 데이터베이스 서버 프로세스(cub_server) 사이에서 가교 역할을 하면서 큐브리드의 전반적인 운영에 도움을 준다.
2. 서버 프로세스
- 서버 프로세스는 특정 데이터베이스와 일대일로 대응된다.
- 하나의 장비에는 데이터베이스를 여러개 생성할 수 있고 데이터베이스는 각각 격리된 메모리 공간에서 동작한다. 따라서 그중 한 데이터베이스에 장애가 발생해도 나머지 데이터베이스는 문제가 발생할 가능성이 낮다.
ex)데이터베이스가 2개라면 서버 프로세스 또한 2개가 구동된다.
3. 브로커 프로세스
- 최초에 응용프로그램이 접속하는 프로세스
- cubrid_broker.conf 파일 에서 설정
- 큐브리드가 제공하는 인터페이스를 통해 질의 요청이 들어오면 먼저 브로커 프로세스가 요청을 받은 후, 연결이 종료될 때까지 질의 요청을 처리할 프로세스인 CAS 프로세스(cub_cas)를 할당한다.
4. CAS 프로세스
- CAS 프로세스는 연결 요청을 마스터 프로세스에 전달하고, 마스터 프로세스는 요청을 처리할 서버 프로세스를 찾아 CAS 프로세스에 전달한다. 이후 연결이 종료될 때까지 질의 요청은
‘응용프로그램(드라이버 또는 인터페이스) – CAS 프로세스 – 서버 프로세스’의 연결 관계를 유지한다.
5. 큐브리드 매니저 서버 프로세스
- 큐브리드 매니저 서버 프로세스는 큐브리드 매니저에서 사용하는 프로세스다.
- 큐브리드 매니저 : 질의 실행,데이터베이스 추가,백업,복구등 콘솔에서 수행하는 업무를 GUI로 수행할수 있게하는 도구다. 큐브리드 매니저 서버는 HTTPS 프로토콜로 정의된 API를 제공한다.
참고) 큐브리드 HA 기능을 사용해 복제 구성하는 경우에는 트랜잭션 로그(transaction log)가 상대방 노드에 복제되고, 복제 로그(replication log)가 서버 프로세스를 통해 반영되는 과정이 추가된다.
응용프로그램이 서버에 연결되는 과정
응용프로그램이 서버에 연결되는 과정
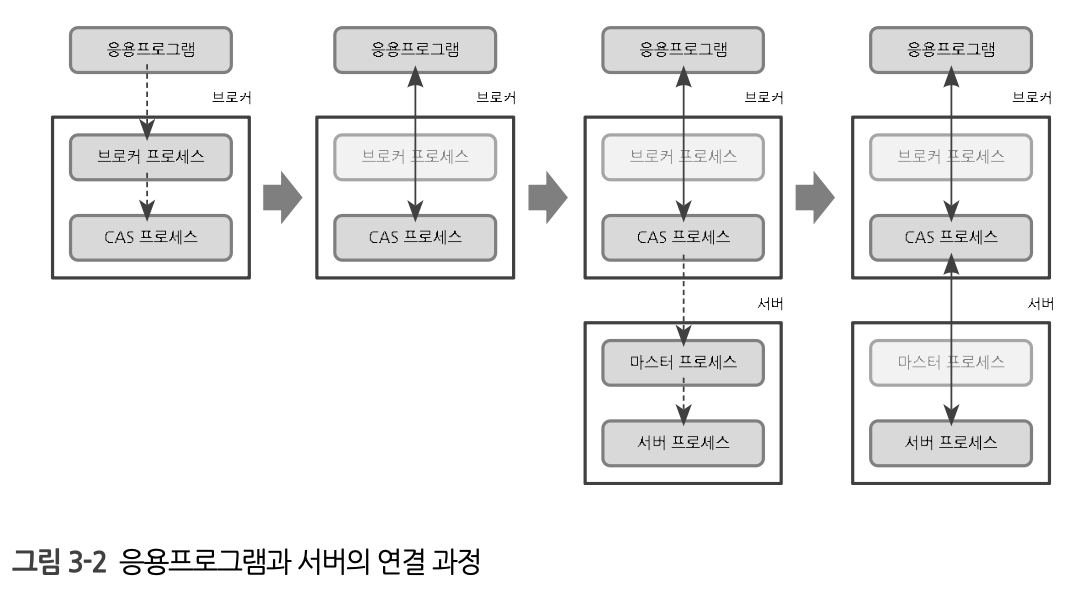
1. 응용프로그램이 브로커 프로세스에 연결을 요청하면 브로커 프로세스는 CAS 프로세스를 할당한다.
2. 응용프로그램과 CAS 프로세스가 연결된다.
3. CAS 프로세스가 마스터 프로세스에 연결을 요청하면 마스터 프로세스는 서버 프로세스에 연결한다.
4. 응용프로그램 – CAS 프로세스 – 서버 프로세스 연결이 완료된다.
큐브리드 프로세스는 응용프로그램, 서버 프로세스, 브로커(브로커/CAS/마스터 프로세스) 3계층으로 구성되어있음
프로세스 종류
" ps -ef | grep cub_ " : 프로세스 현황 출력
cub_master: 마스터프로세스cub_server: 서버프로세스.cub_server demodb는 demodb라는 데이터베이스를 관리하는 전용서버프로세스다.cub_broker: 브로커 프로세스. cubrid_broker. conf파일에서 설정한 개수만큼 생성된다.query_editor_cub_cas_1~5: query_editor 브로커에서 구동중인 5개의 CAS프로세스.broker1_cub_cas_1~5: BROKER1 브로커에서 구동중인 5개의 CAS프로세스.첫번째 cub_broker 아래의
query_editor_cub_cas_1은 해당 브로커에서 구동되는 CAS 프로세스로, query_editor는 브로커의 이름이고 cub_cas는 CAS 프로세스임을 뜻하며 숫자는 프로세스의 순번이다. 즉, 응용프로그램이 데이터베이스로 연결하기 위해 query_editor 브로커가 제공하는 CAS가 5개 구동 중이다. 같은 방법으로, 두 번째 브로커 프로세스는 broker1이라는 것을 알 수 있다.cub_cmserver: 큐브리드 매니저 서버에서 사용하는 프로세스.
큐브리드 서비스
서비스 시작&종료
$ cubrid service start시작 명령어를 실행하면 마스터 프로세스 -> 서버 프로세스 -> 브로커 프로세스 -> 매니저 프로세스 순차로 실행된다.
$ cubrid service stop종료 명령어 실행하면 서버 프로세스 -> 브로커 프로세스 -> 매니저 프로세스 -> 마스터 프로세스 순차로 실행된다.
시작할 프로세스 지정
경우에 따라 데이터베이스와 브로커를 분리해서 운영하는 경우, 사용하지 않는 프로세스까지 cubrid service 명령을 사용해서 실행하는 것이 아니라, 서비스 시작 시 시작하는 프로세스를 cubrid.conf 파일에서 설정해서 시작할 프로세스를 지정할 수 있다.
# 기본 설정 : server,broker,manager 프로세스 실행
# Service section - a section for 'cubrid service' command
[service]
# The list of processes to be started automatically by 'cubrid service start' command
# Any combinations are available with server, broker, manager and heartbeat.
service=server,broker,manager
# 지정 설정 : broker 프로세스만 실행
[service]
service=broker⚠️ 마스터 프로세스는 기본 프로세스에 없는 이유 : 큐브리드 동작에 반드시 필요한 프로세스이기 때문
(마스터 프로세스는 서비스 시작시 맨먼저 시작되고 서비스 종료시 맨마지막에 종료)
서버 프로세스 시작
서버 프로세스는 데이터베이스별로 시작하거나 종료할 수 있다. 큐브리드 설치 시 자동으로 설치되는 데이터베이스인 demodb는 하나의 서버 프로세스가 관리한다. (데이터베이스-서버 일대일)
# demodb만 시작하거나 종료하려면 아래와 같이 실행
$ cubrid server start demodb
$ cubrid server stop demodb(문제) 위 명령어 사용시, 데이터베이스가 여러개라면 필요 데이터베이스 시작 시 번거로움
(해결) cubrid.conf 파일의 server 파라미터에 서비스 시작 시 기본으로 시작할 데이터베이스 이름을 지정
# The list of database servers in all by 'cubrid service start' command.
# This property is effective only when the above 'service' property contains 'server' keyword.
# cubrid.conf 파일의 server 파라미터에 demodb를 입력해두면 큐브리드 서비스를 시작할 때 demodb 서버도 함께 시작
server=demodb
# 서비스 시작 시 시작할 데이터베이스가 여러 개라면 다음과 같이 쉼표(,)로 구분해서 입력
server=demodb, testdb1, testdb2브로커 프로세스 시작
큐브리드를 설치 시, query_editor 와 BROKER1 브로커가 기본으로 생성 (cubrid_broker.conf 파일에 기본으로 설정된 브로커)
[ 브로커 사용법 ]
- 응용프로그램은 접속 포트로 각 브로커를 구분해 접속할 수 있으므로 사용 목적에 따라 브로커를 분리해 사용할 수 있다.
- 예를 들어 응용프로그램 A는 일반 사용자가 사용하는 프로그램이므로 브로커 #1만 사용 하고, 응용프로그램 B는 운영자만 사용하는 프로그램이므로 브로커 #2만 사용하게 할 수 있다. 이렇게 구분하면 브로커 #1을 종료했을 때 브로커 #1에 접속하는 응용프로그램 A만 접속할 수 없게 할 수 있다. 또는 단순히 브로커의 설정을 조작해 브로커 #1에 접속하는 응용프로그램 X는 읽기/쓰기가 모두 가능하게 하고, 브로커#2에 접속하는 응용프로그램 Y는 읽기만 가능하게 할 수 있다.
# 브로커 시작과 종료 명령
$ cubrid broker start
$ cubrid broker stop
# 브로커 프로세스 실행 후, 브로커 사용여부만 변경
$ cubrid broker on query_editor
$ cubrid broker off query_editor매니저 프로세스 시작
# 매니저 프로세스를 시작하고 종료하는 명령
$ cubrid manager start
$ cubrid manager stop서비스 상태 확인
서버 연결 테스트
큐브리드 설치 -> 서비스 시작 -> 데이터베이스 서버에 잘 연결되는지 확인
$ csql -u dba demodb
CUBRID SQL Interpreter
Type `;help' for help messages.
csql>데이터베이스
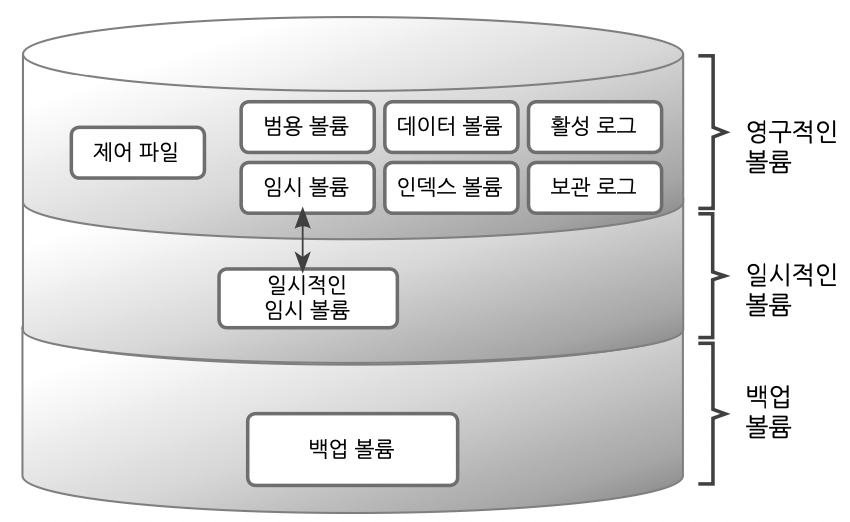
데이터베이스 볼륨 구조
- 영구적인 볼륨 : 한번 생성되면 데이터베이스가 삭제되기 전까지 유지되는 볼륨이다.
영구적인 볼륨은 용도에 따라 나뉜다
- 범용볼륨 : 범용적으로 사용하는 볼륨이다. 스키마,인덱스,데이터를 저장한다. 볼륨생성명령(cubridcreatedb) 을 실행할 때 볼륨 타입을 지정하지 않으면 범용 볼륨으로 생성된다.
- 데이터 볼륨 : 데이터를 저장하기 위한 공간이다.
- 인덱스 볼륨 : 인덱스를 저장하기 위한 공간이다.
- 임시 볼륨 : 질의처리 및 정렬을 수행할때 중간결과 및 최종결과를 임시로 저장하는 공간이다. 이 공간이 모두소진되면 일시적인 볼륨을 사용한다. 일시적인 볼륨은 데이터베이스를 재시작하면 삭제되지만 임시 볼륨은 영구 볼륨 이므로 데이터베이스를 정지해도 유지된다.
- 일시적인 볼륨 : 데이터베이스 운영중 필요한 중간결과를 일시적으로 저장하기위해 사용되는 볼륨이다.
- 백업볼륨 : 데이터베이스의 백업시점의 스냅숏으로, 데이터베이스 백업시 생성되는 볼륨이다.
영구적인 볼륨은 용도에 따라 범용 볼륨(generic volume), 데이터 볼륨(data volume), 인덱스 볼륨(index volume), 임시 볼륨(temp volume)으로 구분해 생성할 수 있다.
데이터베이스 생성
$ cd $CUBRID_DATABASES
$ mkdir testdb
$ cd testdb
# 새로운 데이터베이스 생성
$ cubrid createdb testdb ko_KR.utf8
# 이때, 데이터베이스 볼륨과 로그 볼륨의 크기를 정한다.
# 기본값은 cubrid.conf 파일의 db_volume_size, log_volume_size 파라미터에서 정한 값이며
# 이 파라미터의 기본값은 512MB다.
Creating database with 512.0M size using locale ko_KR.utf8. The total amount of disk space needed is 1.5G.testdb 데이터베이스 볼륨 파일을 확인해보면
$ ls -l
total 1050928
drwxrwxr-x 2 brightest brightest 4096 Jun 10 12:03 lob
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb_lgar_t
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb_lgat
-rw------- 1 brightest brightest 218 Jun 10 12:03 testdb_lginf
-rw------- 1 brightest brightest 288 Jun 10 12:03 testdb_vinftestdb: 데이터베이스의 데이터와 인덱스 정보를 저장하는 볼륨. 카탈로그 테이블정보가 포함돼있다.testdb_lgar_t: 보관로그파일을 저장하기전에 사용되는 임시파일. 활성로그파일이 가득차면 보관로그파일이 생성되는데, 보관 로그 파일은 데이터베이스의 백업 또는 복구 시 사용된다. HA 구성 시 데이터 복제에도 보관 로그 파일이 사용된다. 이 예에서는 보관 로그 파일이 아직 생성되지 않은 상태다.testdb_lgat: 활성로그파일. 진행중인 트랜잭션정보를 저장한다.testdb_lginf: 로그파일의 정보를 저장하는 파일.testdb_vinf: 볼륨파일의 정보를 저장하는 파일.
데이터베이스 볼륨 추가
데이터베이스 범용 볼륨의 여유 공간이 generic_vol_prealloc_size 파라미터에 지정한 크기보다 작아지면 범용 볼륨이 자동으로 추가된다. 하지만 예상되는 사용량만큼 용도에 맞게 데이터베이스 볼륨을 미리 생성해 두는 것을 권장한다. 그렇다고 예상 사용량에 비해 너무 큰 볼륨을 미리 추가 하는 것은 좋지 않다. 볼륨이 크게 할당될수록 백업 시간이 길어지기 때문이다.
# 볼륨 파일 추가
cubrid addvoldb -S -p data -n testdb_DATA01 --db-volume-size=512M testdb cubrid
addvoldb -S -p data -n testdb_DATA02 --db-volume-size=512M testdb cubrid
addvoldb -S -p index -n testdb_INDEX01 --db-volume-size=512M testdb cubrid
addvoldb -S -p temp -n testdb_TEMP01 --db-volume-size=512M testdb
# 결과
$ ls –l
drwxrwxr-x 2 brightest brightest 4096 Jun 10 12:03 lob
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb
-rw------- 1 brightest brightest 536870912 Jun 10 16:38 testdb_DATA01
-rw------- 1 brightest brightest 536870912 Jun 10 16:38 testdb_DATA02
-rw------- 1 brightest brightest 536870912 Jun 10 16:38 testdb_INDEX01
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb_lgar_t
-rw------- 1 brightest brightest 536870912 Jun 10 12:03 testdb_lgat
-rw------- 1 brightest brightest 218 Jun 10 12:03 testdb_lginf
-rw------- 1 brightest brightest 536870912 Jun 10 16:38 testdb_TEMP01
-rw------- 1 brightest brightest 288 Jun 10 12:03 testdb_vinftestdb_DATA01,testdb_DATA02: 데이터를 저장하는 볼륨파일.testdb_INDEX01: 인덱스를 저장하는 볼륨파일.testdb_TEMP01: 질의시 정렬 중간결과등을 저장하는 임시볼륨파일. 큰 데이터를 저장한 테이블을 정렬하거나 인덱스를 생성할 때 정렬된 데이터를 임시로 저장하는 데 사용된다.
👉 이 파일이 모두 사용되면 일시적으로testdb_t32766이라는 이름의 파일이 생성되는데, 이는 일시적인 임시 볼륨이다.
여기서 잠깐! 🖐
testdb_TEMP01은 데이터베이스가 재시작해도 파일이 유지되는 영구적인 임시 볼륨(temp volume)이고,testdb_t32766는 데이터베이스 재시작 시 삭제되는 일시적인 임시 볼륨(temporary temp volume)이다.
testdb_TEMP01과 같은 영구적인 임시볼륨을 미리 추가로 생성해두는것을 고려해야하는 이유
일시적인 임시 볼륨은 한 번 크기가 늘어나면 늘어난 상태를 유지해, 데이터베이스가 정지될 때까지 디스크의 여유 공간을 차지한다 => I/O 성능에 영향을 준다
데이터베이스 볼륨 사용량 확인
$ cubrid spacedb -p testdb큐브리드 설정
- 큐브리드를 설치하면 큐브리드를 바로 시작할 수 있게 기본적으로 설정돼 있지만, 특정 서버에서는 서비스 포트 번호를 변경하거나 메모리 설정을 조정 해야 한다.
- 큐브리드는 목적에 따라 몇 개의 설정 파일을 제공한다. 이들 설정 파일은 큐브리드 설치 경로 아래의 conf 디렉터리 에 있다.
데이터베이스 서버 설정
큐브리드 서버와 관련된 파라미터는 cubrid.conf 파일에서 설정. cubrid.conf 파일 내용은 크게 네 부 분으로 구분돼 있음
[service]:큐브리드 서비스 시작에 관련된 파라미터.
[common]:전체 데이터베이스에 공통으로 관련된 파라미터.
[@{데이터베이스이름}]:각 데이터베이스에 개별적으로 적용되는 파라미터.
[standalone]:cubrid유틸리티가 독립모드(stand-alone,--SA-mode)로 구동할때 사용되는 파라미터.
큐브리드 9.3부터 추가됐다.
cubrid 유틸리티란 cubrid로 시작하는 명령의 집합을 말한다(예: cubrid createdb, cubrid loaddb, cubrid backupdb 등).[common] 파라미터 종류
-
data_buffer_size: 캐싱되는 데이터버퍼의 크기. 이 값이 클수록 캐싱되는 데이터가 많아지므로 디스크I/O 비용을 줄일수있지만, 너무 크면 시스템 메모리가 과도하게 점유돼 운영체제에의해 스와핑이 발생할수있다.
-
log_buffer_size: 로그버퍼의 크기.
-
sort_buffer_size: 정렬을 수행하는 질의에서 사용하는 버퍼의크기. 정렬을 요청하는 클라이언트마다 정렬버퍼가 할당되며, 정렬이 완료되면 해제된다. 인덱스를 생성하는 경우 정렬 버퍼가 많이 필요하므로 정렬 버퍼를 늘리는 것 이 좋지만 데이터베이스 운영 중에는 불필요하게 많은 메모리를 점유할 수 있으므로 다시 줄이는 것이 좋다.
-
max_clients: 큐브리드 서버프로세스에 접속 가능한 클라이언트의 최대개수. 여기서 클라이언트란 브로커의 CAS, CSQL, HA 복제 관련 프로세스, cubrid 유틸리티를 의미한다. 따라서 사용하려는 응용프로그램의 최대 개수 보다 크게 설정해야 한다.
참고)
리눅스에서는 프로세스 하나당 오픈할 수 있는 파일 디스크립터 개수의 최댓값(ulimit –n)을 max_clients 파라미터의 값보다 크게 설정해야 한다. -
cubrid_port_id: 큐브리드 마스터 프로세스가 사용하는 포트번호. 이 포트는 큐브리드 마스터 프로세스와 브로커 프로세스가 통신할 때 사용하는 포트다. 응용프로그램은 CAS 프로세스와 통신하므로 응용프로그램에서 사용하는 포트는 cubrid_broker.conf 파일의 BROKER_PORT 파라미터로 설정한다.
-
log_max_archives: 보관로그의 최대개수. 특정시점으로 복구하려면 해당시점이 보관로그에 보존돼야하므로 이 값을 크게 설정해야한다. 그 외의 경우에는 설정을 바꾸지 않아도 된다.
" 데이터베이스 서버를 설정할 때 가장 유의해야 하는 것은 data_buffer_size 파라미터와 max_clients 파라미터다. data_buffer_size 파라미터값은 메모리 영역의 40~60% 정도, max_clients 파라미터값을 1024 "
브로커 설정
cubrid_broker.conf 파일로 브로커 설정
[broker]
- broker 아래에 정의된 파라미터는 모든 브로커에 공통으로 적용되는 파라미터다.
- MASTER_SHM_ID:큐브리드브로커가사용하는공유메모리의아이디.시스템내에서유일한값이어야한다.
[%query_editor][%BROKER1]
- SERVICE:해당브로커의구동여부.ON이면구동하고,OFF이면구동하지않는다
- BROKER_PORT:해당브로커에서사용하는포트번호
MIN_NUM_APPL_SERVER:해당브로커에서구동되는CAS프로세스의최소개수.브로커가처음구동될때이 개수만큼의 CAS 프로세스를 구동한다. 기본값은 5다.MAX_NUM_APPL_SERVER: 해당 브로커에서 구동되는 CAS 프로세스의 최대 개수.MIN_NUM_APPL_ SERVER파라미터로 지정한 개수보다 많은 연결 요청이 오면 CAS 프로세스 개수를 늘리며, 최대 개수를 초과하면 먼저 진행 중인 트랜잭션이 종료될 때까지 기다렸다가 CAS 프로세스를 할당한다. 기본값은 40이다.
브로커의 CAS 개수
- 브로커의 CAS 개수는
MIN_NUM_APPL_SERVER파라미터와MAX_ NUM_APPL_SERVER파라미터로 설정- 브로커의
MAX_ NUM_APPL_SERVER파라미터값의 합 < 데이터베이스 서버의 cubrid.conf 파일에서 설정한 max_clients 파라미터의 값 (이유 : 데이터베이스 서버 프로세스에는 CAS 외에도 복제 로그 복사 프로세스(copylogdb), 복제 로그 반영 프로세스(applylogdb) 등 HA 관련 프로세스와 csql 등의 명령 프로세스가 데이터베이스 서버로의 연결을 사용하기 때문)- 설정에 따라 브로커가 실행됐을 때 메모리 가용량이 충분한 지도 검토해야 함
CAS 프로세스 메모리 사용 설정
cubrid_broker.conf파일에서MAX_NUM_APPL_SERVER파라미터로 브로커당 CAS 프로세스의 최 대 개수를 설정할 때는 " CAS 프로세스당 필요한 메모리 공간 " 을 고려해 이 값을 설정
이 " CAS 프로세스당 필요한 메모리 공간 "
= cubrid broker status 명령을 실행
실행결과의 PSIZE 값이 프로세스가 차지하는 메모리 공간입니다. 대략 50MB 정도인데, 대부분은 공유 메모리에 의해 공유되는 공간이고 이후 증가한 만큼이 실제로 사용하는 메모리 공간입니다.
EX > 초기 구동 시 CAS 프로세스의 PSIZE 값이 50MB / 트랜잭션 수행 후 => 70MB / CAS 프로세스가 실제로 사용하는 메모리 = 20MB
cubrid_broker.conf 파일의
APPL_SERVER_MAX_SIZE파라미터를 설정하면 해당 CAS 프로세스 가 사용하는 메모리 공간의 최대 크기를 지정할 수 있으며, 이때 사용하는 메모리의 기준은 PSIZE 입니다. 이 PSIZE 값이 설정된 값을 초과하면 진행 중이던 트랜잭션을 모두 수행한 후 해당 CAS 프로세스를 재시작합니다.리눅스에서 기본값은 0이며, 이 경우 CAS 프로세스의 PSIZE 값이 초기 구동 시 PSIZE 값의 두 배가 되면 해당 CAS 프로세스를 재시작합니다. 예를 들어, 초기 구동 시 PSIZE 값이 50MB라면 이 값이 100MB가 될 때 진행 중이던 트랜잭션을 모두 수행한 후 CAS 프로세스를 재시작합니다.
APPL_SERVER_MAX_SIZE 의 값이 0 또는 음수인 경우: 현재 프로세스의 크기가 CAS의 초기 메모리의 2배가 될 때 재시작
APPL_SERVER_MAX_SIZE 의 값이 양수인 경우: APPL_SERVER_MAX_SIZE 의 설정 값을 초과할 때 재시작
APPL_SERVER_MAX_SIZE_HARD_LIMIT파라미터는APPL_SERVER_MAX_SIZE파라미터 와 비슷하지만 진행 중인 트랜잭션을 무시하고 CAS 프로세스를 재시작한다는 점이 다릅니다. 예를 들어 APPL_SERVER_MAX_SIZE 파라미터값이 200MB, APPL_SERVER_MAX_SIZE_HARD_LIMIT 파라미터값이 201MB이며, 초기 구동 시 CAS 프로세스의 PSIZE 값이 50MB라면 CAS 프로세스의 PSIZE 값이 200MB를 초과하는 시점에 진행 중이던 트랜잭션을 마저 수행하려 하지만 201MB에 도달하 면 해당 트랜잭션의 수행을 포기하고 해당 CAS 프로세스가 재시작됩니다. 이는 예기치 않은 특정 질의가 메모리를 점유하는 위험을 방어하기 위한 것입니다.
CAS로그파일
- CAS의 로그 파일이 정해진 크기를 넘으면 {로그명}.bak 파일로 변경되고 신규 로그 파일이 생성된다.
- {로그명}.bak 파일은 최신 1개만 유지한다.
- CAS의 로그 파일 크기는 cubridbroker.conf 파일의 SQL LOG_MAX_SIZE 파라미터값을 따른다. * 기본 : 100MB 정도로 설정한다.
CSQL
CSQL = GUI 환경을 사용할 수 없는 콘솔(console) 환경에서 질의를 실행하고 결과를 조회하기 위해 주로 사용
CSQL = 큐브리드 설치 경로 아래의 bin 디렉 터리에 위치
# 기본으로 설치한 demodb는 dba 사용자의 비밀번호가 설정돼 있지 않으므로 비밀번호 없이 연결할 수 있지만,
# 비밀 번호를 설정한 후에는 -p 옵션을 사용해 비밀번호를 지정해야 연결할 수 있다.
$ csql -u dba demodb
CUBRID SQL Interpreter
Type `;help' for help messages.
csql>
# 현재 빈 문자열인 dba 비밀번호 변경
csql> alter user dba password '1234';
csql> ;exit
$ csql -u dba demodb
Enter Password :
# 다시 빈 문자열로 변경
alter user dba password '';⚠️ 주의할점
- CSQL에서 실행하면 질의문이 SQL 로그에 남지 않는다.
- 브로커를 통하는 응용프로그램에서만 SQL 로그가 남으므로 자신이 수행하는 질의문에 대한 SQL 로그를 남기고 싶다면 큐브리드 매니저를 사용하는 것을 권장한다.
- 브로커의 SQL 로그는 $CUBRID/log/broker/sql_log 디렉터리 아래에 존재한다.
큐브리드 매니저
질의 실행/데이터베이스 생성/관리/백업 등을 GUI 환경에서 수행할 수 있는 도구
# 큐브리드 매니저 서버가 동작중인지 확인 명령
$ cubrid manager status
# 큐브리드 매니저 서버 시작
$ cubrid manager start큐브리드 서비스 시작 시, 큐브리드 매니저 함께 자동 시작 설정
[service]
# The list of processes to be started automatically by 'cubrid service start' command
# Any combinations are available with server, broker, manager and heartbeat.
service=server,broker,manager큐브리드 매니저 모드 2가지
1) 관리 모드
- 관리 모드는 데이터베이스 운영자를 위한 모드
- 권한에 따라 데이터베이스 생성, 관리, 백업 등의 데이터 베이스 관리와 질의 실행이 가능
- 관리 모드에서 데이터베이스 서버에 연결하려면 큐브리드 매니저 서버 정보(특히 매니저 서버 포트 번호)를 알고 있어야 하며, 큐브리드 매니저 계정이 필요
큐브리드 매니저 계정은 데이터베이스 사용자 계정과는 별개의 계정으로,
데이터베이스 사용자 계정=특정 데이터 베이스에만 영향을 줌
큐브리드 매니저 계정=큐브리드 호스트 내의 모든 데이터베이스에 영향을 줄 수 있으므로 주의해서 관리해야 함.
⚠️ 주의) 특히 큐브리드 매니저의 admin 계정은 데이터베이스를 생성하고 삭제할 수 있는 슈퍼 사용자(super user)이므로 더욱 주의해야 함
관리모드 큐브리드 매니저 설정
큐브리드 매니저 서버 포트는 cm.conf 파일의 cm_port 파라미터에 설정돼 있으므로 포트 설정을 변경한 경우 cm_port 파라미터값을 확인해 연결 정보를 입력한다.
- 큐브리드 매니저 서버가 설치된 호스트 주소 (기본값은localhost)
- 큐브리드 매니저 서버가 사용하는 포트번호 (기본값은8001)
[ 호스트 정보 편집 ]
호스트 주소 : 큐브리드가 설치된 호스트의 주소
사용자 PC에 설치한 경우에는 입력돼 있는 localhost를 그대로 둔다.
CM 사용자와 CM 비밀번호 : 데이터베이스 사용자 계정이 아니라 큐브리드 매니저 계정의 아이디와 비밀 번호를 입력하는데, 초기 설정은 아이디와 비밀번호 모두 admin이다.
관리모드 큐브리드 데이터베이스 구동 및 로그인
- 서버 프로세스를 시작하고 종료할 때에는 큐브리드 매니저 admin 계정을 사용하지만 데이터베이스에 로그인하려면 데이터베이스 사용자 계정이 필요하다.
- demodb에는 dba 사용자 계정이 있으며 초기 설정에는 비밀번호가 설정돼 있지 않다.
- 데이터베이스 로그 인 대화 상자에서 사용자 이름에 dba를 입력하고 비밀번호는 입력하지 않은 채로 확인을 클릭한다.
- 로그인 후 데이터베이스 사용자 계정의 비밀번호를 변경하려면 호스트 창에서 해당 데이터베이스 사용자를 마우스 오른쪽 버튼으로 클릭하고 DB 사용자 편집을 클릭해서 변경
관리모드 큐브리드 데이터베이스 테이블 보기
show tabels; show create table athlete;질의편집기를 사용해서도 확인 가능함
2) 질의 모드
- 질의 모드는 개발자를 위한 모드
- 큐브리드 매니저 계정이 없어도 연결할 브로커 정보와 데이터베이스 사용자 계정만 있으면 데이터베이스 서버에 연결해 질의를 실행할 수 있음
- 브로커 정보
(브로커주소=호스트주소/브로커 포트번호)와 데이터베이스 사용자계정(데이터베이스 이름) - 브로커 포트는 큐브리드 설치 경로 아래의 conf 디렉터리에 있는 cubrid_broker.conf 파일에서 확인
- 큐브리드 매니저를 관리 모드로 실행하고 있었다면 질의 모드로 전환해야 함. 큐브리드 매니저 위쪽 도 구 모음에서 모드 전환을 클릭하고 원하는 모드를 클릭하면 모드를 전환할 수 있음
- 연결 정보 등록 클릭해서 데이터베이스 정보 등록

NAVER - CUBRID, 브로커 이야기