8장 - (1) : 브로커 다중화
브로커 파라미터
[%RWbroker]
SERVICE =ON
BROKER_PORT =33000
MIN_NUM_APPL_SERVER =5
MAX_NUM_APPL_SERVER =40
APPL_SERVER_SHM_ID =33000
LOG_DIR =log/broker/sql_log
ERROR_LOG_DIR =log/broker/error_log
SQL_LOG =ON
TIME_TO_KILL =120
SESSION_TIMEOUT =300
KEEP_CONNECTION =AUTO
CCI_DEFAULT_AUTOCOMMIT =ON
# broker mode parameter
ACCESS_MODE =RWdocument 보기
- SERVICE : 해당 브로커의 구동 여부를 결정하기 위한 파라미터로, ON 또는 OFF의 값으로 설정
- BROKER_PORT : 해당 브로커의 포트 번호를 지정하기 위한 파라미터로 시스템 내에서 유일한 값이면서 65,535 이하의 값
- MIN_NUM_APPL_SERVER : CUBRID 브로커가 생성할 수 있는 응용서버(CAS)의 최소 개수를 지정하는 파라미터
- MAX_NUM_APPL_SERVER : CUBRID 브로커가 생성할 수 있는 응용서버(CAS)의 최대 개수를 지정
- APPL_SERVER_SHM_ID : 응용서버(CAS)가 이용하는 공유 메모리 ID를 지정하기 위한 파라미터로 시스템 내에서 유일한 값이어야 한다. 디폴트 값은 해당 브로커의 포트와 동일하게 설정
공유 메모리에는 cub_cas의 상태 정보가 저장되며, cub_broker는 공유 메모리에 저장된 cub_cas의 상태 정보를 참조하여 응용 클라이언트와의 연결을 중계한다. 공유 메모리에 자장된 cub_cas의 상태정보를 통해 시스템 관리자는 어떤 cub_cas가 현재 작업을 수행중인지, 어떤 응용 클라이언트의 요청이 처리 중인지를 확인할 수 있다.
[cubrid@server ~]$ ipcs -mfailed to initialize broker shared memory: 큐브리드 브로커 서버에서 사용할 공유 메모리 공간이 충돌 되어 발생하는 문제 - LOG_DIR : 브로커에 대한 접속 로그가 저장되는 디렉터리를 지정하는 파라미터
- ERROR_LOG_DIR : 브로커에 대한 에러 로그가 저장되는 디렉터리를 지정하는 파라미터
- SQL_LOG : 응용 클라이언트의 요청에 따라 응용서버(CAS)가 처리한 SQL 문에 대해 로그를 저장할 것인지를 결정하는 파라미터로 디폴트 값은 ON
- TIME_TO_KILL : 자동 추가된 응용서버 중 유휴 상태의 응용서버(CAS)를 제거하기 위한 기준 시간을 설정하는 파라미터로 디폴트 값은 120(sec)이다. 유휴 상태란 작업이 없이 쉬고 있는 상태를 말한다. 이 상태가 TIME_TO_KILL 시간 이상 유지되면 응용서버(CAS) 의 제거/추가가 발생한다.
- SESSION_TIMEOUT은 해당 브로커의 세션을 종료하기 위한 타임아웃 값을 설정하는 파라미터로 디폴트 값은 300(sec)이다. 이 파라미터의 설정값을 초과하는 시간 동안 작업 요청에 응답이 없는 경우 해당 세션은 종료된다.
- KEEP_CONNECTION : 응용서버(CAS)와 응용 클라이언트 사이의 연결 방식을 지정하는 파라미터로 ON/OFF/AUTO 중 하나로 설정된다. 이 파라미터가 OFF로 설정되면 클라이언트는 트랜잭션 단위로 응용서버와 연결하고, ON으로 설정되면 커넥션 단위로 응용서버와 연결한다. 또한 AUTO로 설정되면 응용서버의 개수가 클라이언트 개수보다 많은 경우 커넥션 단위로 연결하고, 응용서버의 개수가 클라이언트의 개수보다 적은 경우 트랜잭션 단위로 연결한다.
- ACCESS_MODE : RW (Read Write), RO (Read Only), SO (Standby Only)를 값으로 설정
브로커 모드
브로커는 DB 서버에 Read Write, Read Only, Standby Only 이렇게 세 가지 모드 중 한 가지로 접속할 수 있으며, 사용자가 브로커 모드를 설정할 수 있다.
1. Read Write
cubrid_broker.conf > "ACCESS_MODE=RW"
- 읽기, 쓰기 서비스를 제공하는 브로커
- 이 브로커는 일반적으로 액티브 서버에 연결하며, 연결 가능한 액티브 서버가 없으면 일시적으로 스탠바이 서버에 연결
- 따라서 Read Write 브로커는 일시적으로 스탠바이 서버와 연결될 수 있음
- 일시적으로 스탠바이 서버와 연결되면 트랜잭션이 끝날 때마다 스탠바이 서버와 연결을 끊고, 다음 트랜잭션이 시작되면 다시 액티브 서버와 연결을 시도
- 스탠바이 서버와 연결되면 읽기 서비스만 가능하며, 쓰기 요청에 대해서는 서버에서 오류가 발생
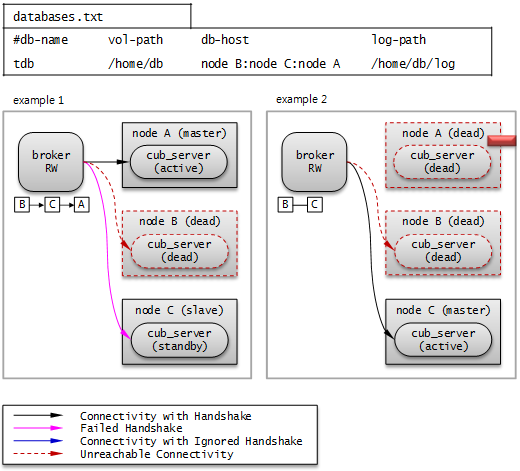
B>C>A 순으로 확인
Example 1. 최종적으로 node A와 연결한다.
Example 2. 최종적으로 node C와 연결한다.
2. Read Only
cubrid_broker.conf > "ACCESS_MODE=RO"
- 읽기 서비스를 제공하는 브로커
- 이 브로커는 가능한 스탠바이 서버에 연결하며, 스탠바이 서버가 없으면 액티브 서버에 연결
- 따라서 Read Only 브로커는 일시적으로 액티브 서버와 연결될 수 있음
- 액티브 서버와 연결된 후
RECONNECT_TIME설정 시간이 지나면 연결을 끊고 재연결을 시도 - 또는 cubrid broker reset 명령을 실행하여 기존 연결을 끊고 새롭게 스탠바이 서버에 연결할 수 있음
- Read Only 브로커에 쓰기 요청이 전달되면 브로커에서 오류가 발생하므로, 액티브 서버와 연결되어도 읽기 서비스만 가능
- active/standby 서버의 구성이 변경되어도 브로커가 모드에 따라 자동으로 active/standby 서버에 연결하므로 애플리케이션은 이를 고려하지 않아도 됨
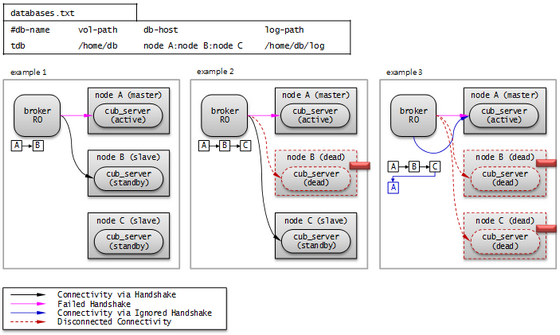
A>B>C 순으로 확인
Example 1. 최종적으로 node B와 연결된다.
Example 2. 최종적으로 node C와 연결된다.
Example 3. 최종적으로 node A와 연결된다.
3. Standby Only
cubrid_broker.conf > "ACCESS_MODE=SO"
- 읽기 서비스를 제공하는 브로커
- 이 브로커는 스탠바이 서버에 연결하며, 스탠바이 서버가 없으면 서비스를 제공하지 않는다.
- 데이터를 확인하기 위해 standby 서버에만 접속해야 하는 경우, 주기적으로 데이터를 수집하지만 단기간 데이터를 수집하지 못해도 괜찮은 경우 등에는 서비스에 영향을 주지 않기 위해서 slave-only 모드를 사용할 수 있다
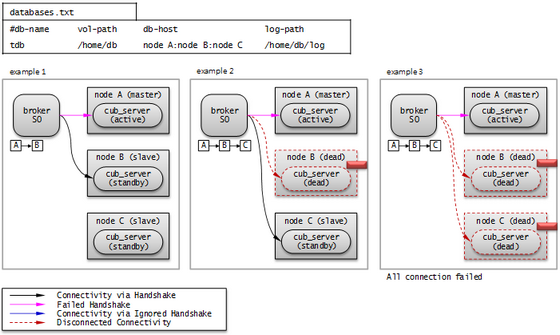
A>B>C 순으로 확인
Example 1. 최종적으로 node B와 연결된다.
Example 2. 최종적으로 node C와 연결된다.
Example 3. 최종적으로 어떤 노드와도 연결되지 않는다 => 이 부분이 Read Only 브로커와의 차이점
HA(high availability) - 브로커
HA는 하드웨어, 소프트웨어, 네트워크 등에 장애가 발생하더라도 서비스에는 영향을 주지 않아 365일 24시간 무중단 서비스를 제공할 수 있게 하는 기능
큐브리드에는 브로커라는 중간 레이어가 있기 때문에, 이것 또한 장애 포인트가 될 수 있습니다.
CUBRID HA 기능을 제공하기 위해 브로커도 물리적인 하드웨어를 중복으로 구성하여, 하나의 브로커에 장애가 발생해도 응용 프로그램에서는 지속적인 서비스를 제공할 수 있습니다.
큐브리드에서는 브로커와 데이터베이스 서버를 다중화할 수 있으며 이를 통틀어 HA라고 합니다.
브로커 다중화
- 브로커는 데이터베이스 서버와 동일한 장비에서 구동하거나 브로커 전용 별도 장비에서 구동할 수 있음 (=사용자의 선호에 맞게 변형이 가능)
- 여러 개의 브로커를 한 장비에서 구동하거나 각 장비에서 구동할 수 있음
브로커의 주된 역할 : 질의 파싱과 질의 실행 계획 생성
➡️ 이 과정에서 CPU와 메모리 자원을 사용한다. 유입되는 트래픽이 많은 경우 많은 연결이 필요하기 때문에 브로커가 CPU와 메모리 자원을 많이 사용할 수 있는데 이런 경우에는 브로커를 별도로 구동해 부하를 분산할 수 있다.
➡️ 브로커를 데이터베이스 서버와 다른 장비에서 구동하는 경우에는 브로커에서 databases.txt 파일의 db-host 파라미터에 데이터베이스 서버의 호스트 이름을 설정해야 한다.
브로커 다중화의 활용
- 응용프로그램은 데이터베이스 서버가 아니라 브로커에 연결을 요청
- 이때 연결을 요청할 브로커의 우선순위를 지정할 수 있으며, 특정 브로커에 접속하는 응용프로그램에는 읽기 작업만 허용할 수도 있다.
- 따라서
브로커 장비를 다중화해 연결 부하를 분산하고,하나의 브로커 장비가 비정상적으로 종료되는 경우에도 다른 브로커 장비가 이를 대체하도록 설정할 수 있다. 주로 다중 접속이 필요한 환경에서 브로커를 다중화한다.
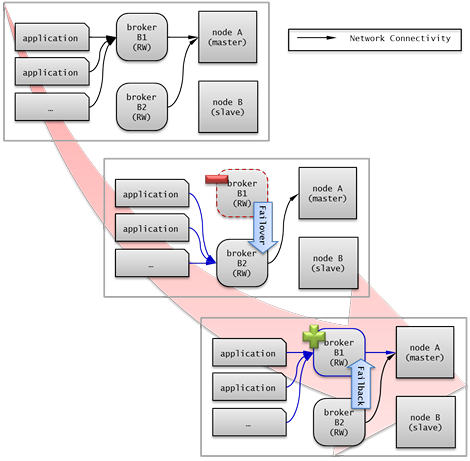
EXAMPLE 1 ) 브로커 failover
2개의 Read Write(RW) 브로커를 구성 합니다. 첫 번째 접속 브로커를 broker B1 으로 하고 두 번째 접속 브로커를 broker B2 로 설정하면, application이 broker B1 에 접속할 수 없는 경우 broker B2 에 접속하게 된다. 이후 broker B1 이 다시 접속 가능해지면 application은 broker B1 에 재접속<브로커 failover 설정>
1)
브로커 failover는 시스템 파라미터의 설정에 의해 자동으로 failover되는 것이 아니며, JDBC, CCI, PHP 응용 프로그램에서는 접속 URL의 altHosts에 브로커 호스트들을 설정해야 브로커 failover가 가능하다.
2)설정한 우선순위가 가장 높은 브로커에 접속하고, 접속한 브로커에 장애가 발생하면 접속 URL에 다음 순위로 설정한 브로커에 접속한다.
3)응용 프로그램에서는 접속 URL의 altHosts를 설정하는 것 외에는 별도의 처리가 필요 없으며, JDBC, CCI, PHP 드라이버 내부에서 처리한다.
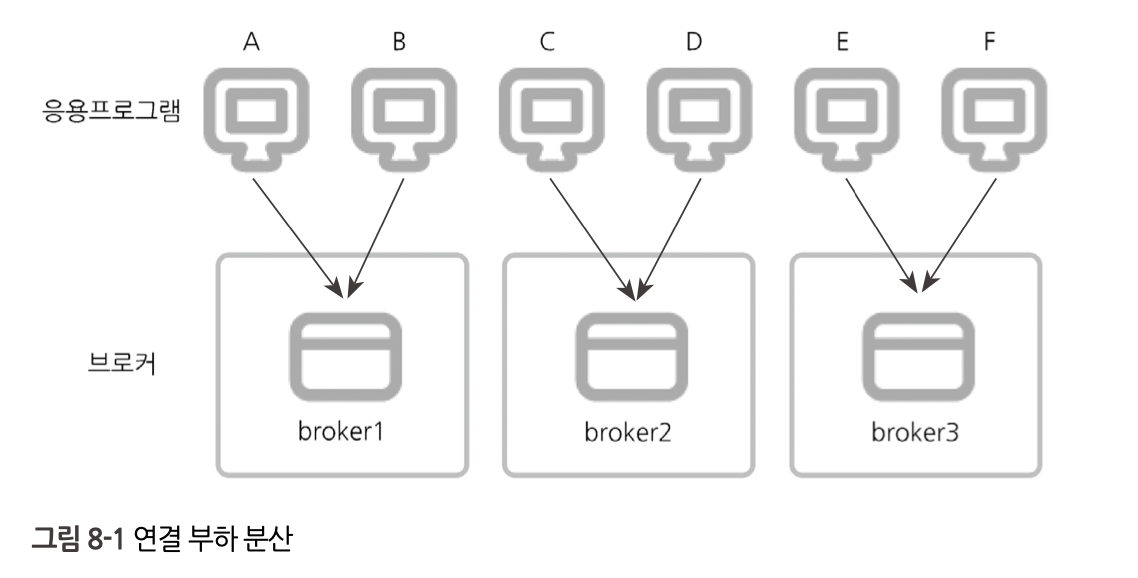
EXAMPLE 2 ) 브로커 부하분산
A, B, C, D, E, F로 총 6개의 응용프로그램이 있고 broker1, broker2, broker3의 3개의 브로커 장비가 존재할 때
A, B는 broker1에,C, D는 broker2에,E, F는 broker3에 접속하도록 설정할 수 있다.
그리고 broker1, broker2, broker3이 연결 부하를 분산해 처리하다가 broker1이 비정상 종료되면 broker1이 처리하던 연결 부하를 broker2가 처리하고, broker2도 비정상 종료되면 broker3이 모든 연결 부하를 처리할 수 있다.브로커 장비는 용도에 맞게 읽기/쓰기용과 읽기 전용으로 나누어 설정할 수도 있다. 따라서
응용프로그램 E, F에는 읽기만 허용하고 싶다면 broker3을 읽기 전용으로 설정해 권한을 제어할 수 있다. 데이터베이스를 다중화한 경우에는읽기/쓰기용 브로커는 액티브(master) 데이터베이스에 접속하고읽기 전용 브로커는 스탠바이(standby) 데이터베이스에 우선 접속해 데이터베이스 서버 장비의 부하도 분산할 수 있다.
응용프로그램 연결 설정
브로커의 failover, failback 기능을 사용하려면 JDBC에서는 다음과 같이 URL 문자열의 altHosts 옵션을 사용해 순서대로 나열한다.
Connection connection = DriverManager.getConnection(
"jdbc:CUBRID:broker1:33000:testdb:user:password:?charSet=utf-8&altHosts=broker2:33000,brok
er3:33000", "dba", "");- broker1, broker2, broker3 : 각 브로커의 호스트 이름
- 33000 : 브로커에 접속할 포트 번호
- 장비 하나에 브로커 프로세스를 여러개 구동할 때 : 호스트 이름은 같게 하고 포트 번호만 달리해 구분
- failover : 설정한 우선순위가 가장 높은 브로커에 접속하고, 접속한 브로커에 장애가 발생하면 접속 URL에 다음 순위로 설정한 브로커에 접속한다
- failback : 브로커 failover 이후 장애 브로커가 복구되면 기존 브로커와 접속을 끊고 이전에 연결했던 우선순위가 가장 높은 브로커에 다시 접속한다
- 또한 큐브리드에서는 JDBC, CCI와 같은 드라이버 단계에서 로드 밸런스 기능을 제공해 응용프로그램에 서 데이터베이스의 연결 URL에 loadBalance=true 속성을 추가하면 연결할 브로커를 무작위로 선택한다.
브로커 사용 장점
1) 연결을 처리하는 cub_cas를 공유할 수 있다는 점
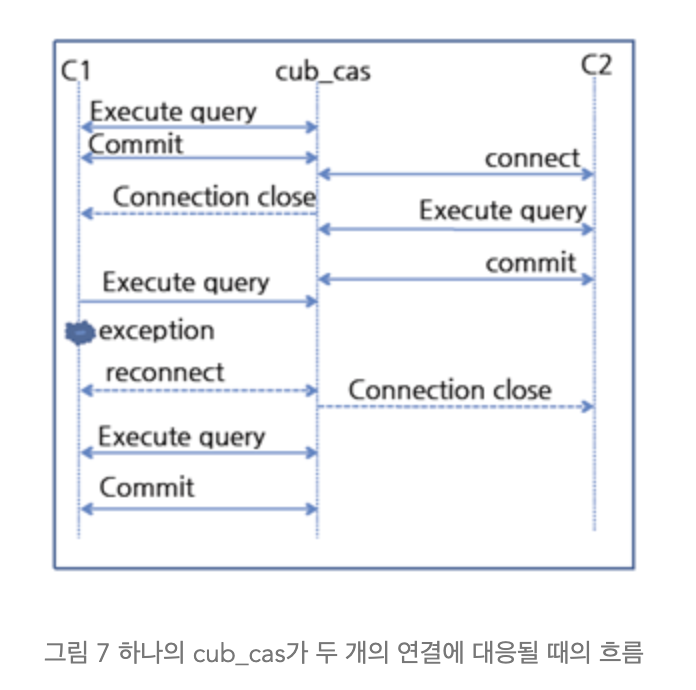
애플리케이션에서 요청한 연결의 개수보다 cub_cas가 적으면 cub_cas를 공유할 수 있다.
2) 모니터링과 로깅
애플리케이션에서 요청한 모든 질의는 브로커를 통하므로 브로커 상태를 통해 처리 과정의 일부를 파악할 수 있다.
3) 다양한 브로커 모드를 활용할 수 있다는 것
3계층 구조는 단점도 있지만, 서버 환경이 복잡해질수록 연결에 대한 유연성을 확보한다는 측면에서는 매우 유용하다.
참고🖇
<브로커 다중화 개념 이해를 위한 좋은 글📝>
CUBRID HA 제약사항
- Linux 계열에서만 사용할 수 있다. CUBRID HA 그룹의 모든 노드들은 반드시 동일한 플랫폼으로 구성해야 한다.
- 테이블은 반드시 기본 키(Primary key)가 포함되어야 한다.
- Java 저장 프로시저 환경 구축은 복제되지 않으므로, Java 저장 프로시저를 사용하려면 모든 노드에 각각 Java 저장 프로시저 환경을 설정해야 한다.
- CALL 문으로 호출되는 메서드(예: login(), add_user(), drop_user(), change_owner())는 복제 되지 않으므로 사용하지 않아야 한다.
- 통계 정보를 갱신하는 UPDATE STATISTICS 문은 슬레이브 노드에 복제되지 않는다.
- 시리얼 캐시를 사용하는 경우 CUBRID HA 그룹 내 노드 간 시리얼의 현재 값이 일치하지 않는다.
- 백업 시 -r 옵션을 사용하면 복제에 필요한 보관 로그까지 삭제될 수 있으므로 사용하지 않아야 한다.
- 클릭카운드 함수(INCR/DECR)는 쓰기 작업이므로 슬레이브 노드에서 사용하면 오류를 반환한다.
- LOB(BLOB/CLOB)(구조화되지 않은 용량이 큰 데이터를 저장할 수 있는 데이터 타입) 타입은 데이터베이스 볼륨이 아닌 별도의 파일로 저장되고 메타 데이터만 볼륨에 저장되는 구조이므로 LOB 데이터가 복제되지 않기 때문에 사용하지 않아야 한다.
= CUBRID HA에서 LOB 칼럼 메타 데이터(Locator)는 복제되고, LOB 데이터는 복제되지 않는다. 따라서 LOB 타입 저장소가 로컬에 위치할 경우, 슬레이브 노드 또는 failover 이후 마스터 노드에서 해당 칼럼에 대한 작업을 허용하지 않는다.LOB을 사용하지 못하는 HA 제약사항 극복
HA 구성형태

PPT : 큐브리드 아키텍처
큐브리드 구조(구성)
큐브리드는 다른 DBMS 와 다르게 '브로커'라는 미들웨어를 가지고 있습니다. App/Broker/DBserver 이렇게 3 tier 구조입니다.
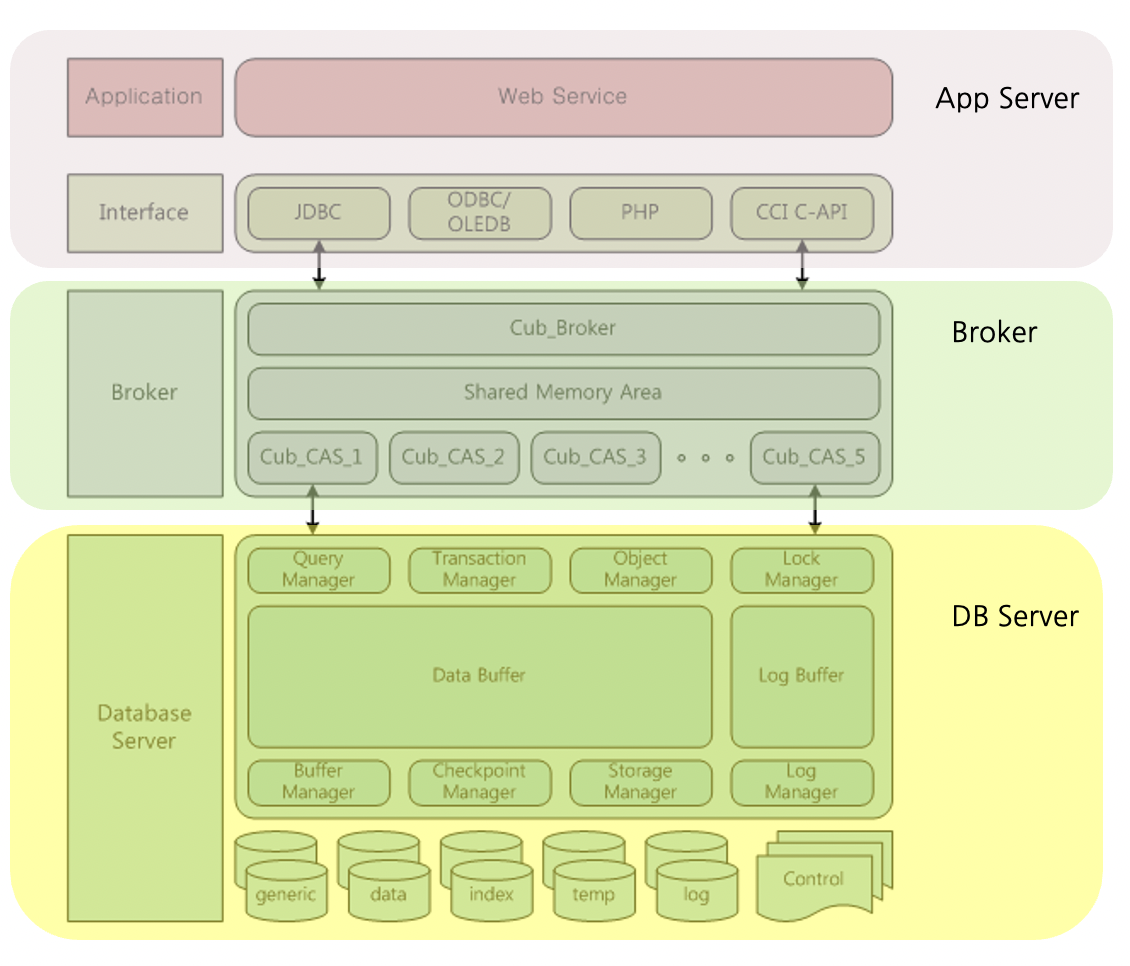
Broker에는 cub_broker,shared memory,cas프로세스 로 나누어집니다. DBserver는 data buffer, query manager, transaction manager 등으로 구성됩니다. Broker와 DBserver는 각각 별도의 서버로 구성될수도, 하나의 서버에 구성될수도 있습니다.
또한 응용에서 transaction이 종료되어도 cas는 db와의 접속을 그대로 유지하고 있다.
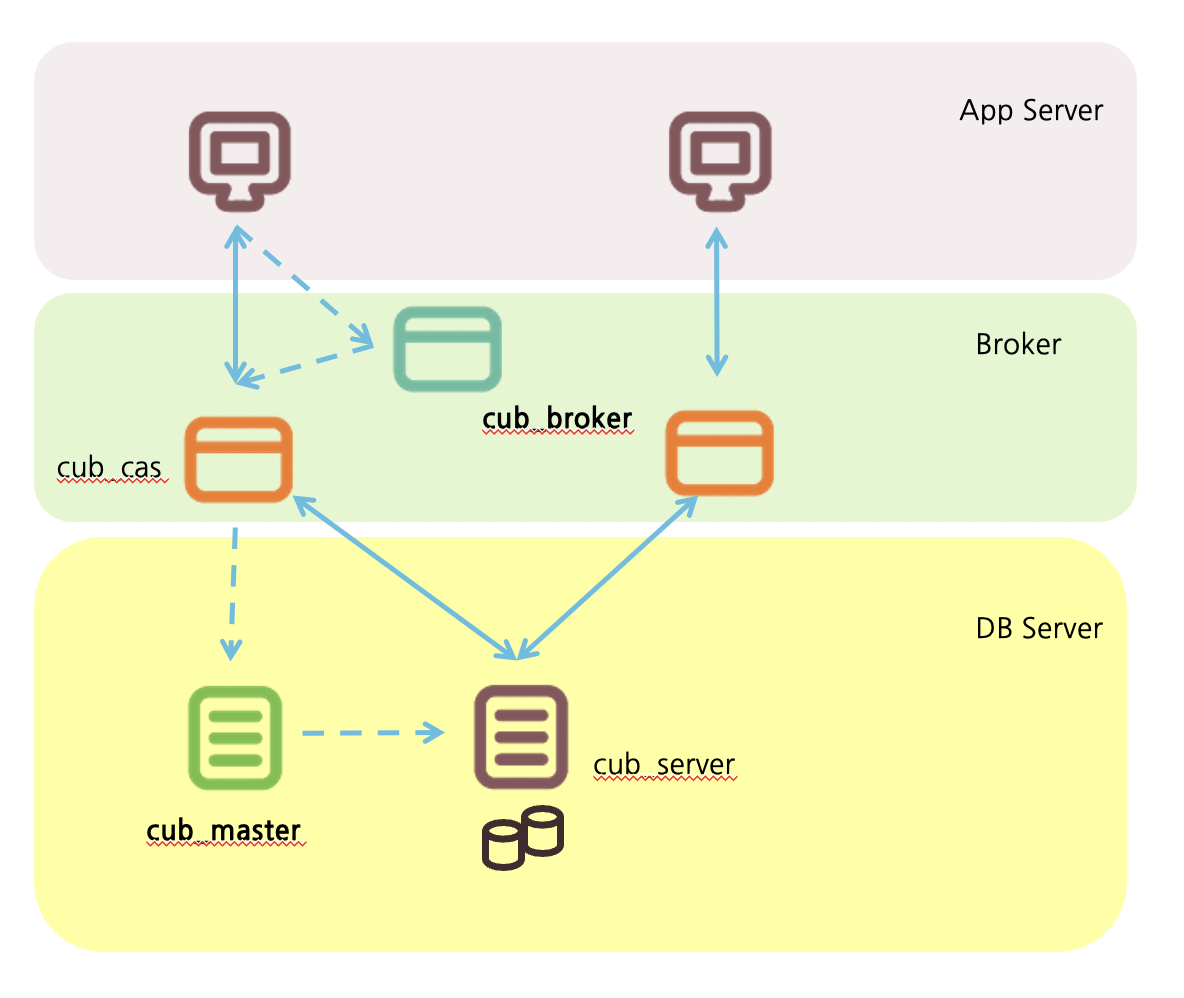
1. cub_master
- 하나의 Engine에서 하나씩 구동된다
- client와 Server프로세스 사이의 연결을 담당하는 프로세스이다.
2. cub_server
- 데이터베이스가 구동되어 있을 때 검색되는 프로세스.
- 구동되는 데이터베이스의 수 만큼 확인된다. (한 개의 Engine에서 여러대의 DB가 구동될 수 있다.)
- 데이터베이스 파일 및 로그 파일 등에 직접 접근하여 사용자 요청을 처리하는 프로세스.
3. Broker
3-1) cub_broker
- Broker가 구동되어 있을 때 검색되는 프로세스.
- cubrid_broker.conf에 등록되어 Service 상태가 ON인 Broker의 개수 만큼 확인된다.
- 응용 Client(JDBC, ODBC, PHP 등)와 cub_cas 프로세스 사이의 연결을 중계하는 기능을 수행한다.
- cub_cas 프로세스의 상태를 모니터링 및 관리한다.
3-2) cub_cas
- DB에 연결하고자 하는 모든 종류의 응용 Client가 사용하는 공용 응용 서버의 역할을 한다.
– 환경 설정에 따라 cub_broker 프로세스에 의해 동적으로 조정된다.
– Query 분석이나 최적화, 실행 계획 생성 등의 작업이 수행된다
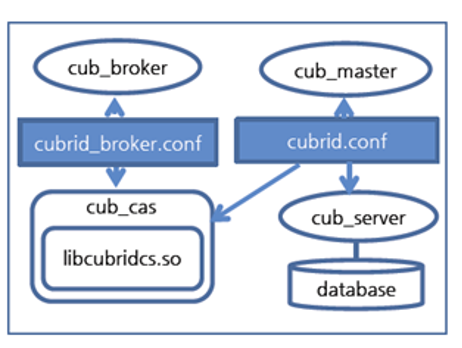

시스템 프로세스 동작 방식
- cub_broker 동작 방식
- cub_broker는 드라이버와 직접적으로 커넥션을 맺은 후 우선 드라이버의 요청을 파악한다.
- cub_broker가 처리할 수 있는 요청은 커넥트, 질의 수행 중단과 핑 세 가지이다.
•커넥트(connect): 드라이버가 응용 프로그램의 SQL을 처리하기 위해 cub_cas와 연결을 요청
•질의 수행 중단(query cancel): 특정 cub_cas에서 수행 중인 SQL 중단
•핑(ping): 드라이버가 cub_cas와 연결이 정상인지 확인
- cas 동작 방식
- cub_cas는 전달받은 드라이버 커넥션으로부터 SQL 요청을 받아 처리를 시작한다.
- 이때 트랜잭션이 시작되며, 트랜잭션 종료(commit/rollback이 될 때)까지 이 트랜잭션을 유지한다.
- 트랜잭션이 종료되면 cub_cas는 대기 상태로 전환되고, 연결된 드라이버가 새로운 트랜잭션을 시작하거나 브로커로부터 새로운 커넥션을 받을 수 있도록 대기한다.
- cub_broker가 새로운 드라이버 커넥션을 cub_cas에 전달하면, cub_cas는 기존의 드라이버 커넥션을 종료하고 새로운 드라이버 커넥션을 받는다. 비활성 상태로 전환된 드라이버 커넥션이 활성 상태로 전환되려면 브로커를 통해 다시 접속해야 한다.
cub_cas 프로세스 상태

데이터베이스 볼륨구조

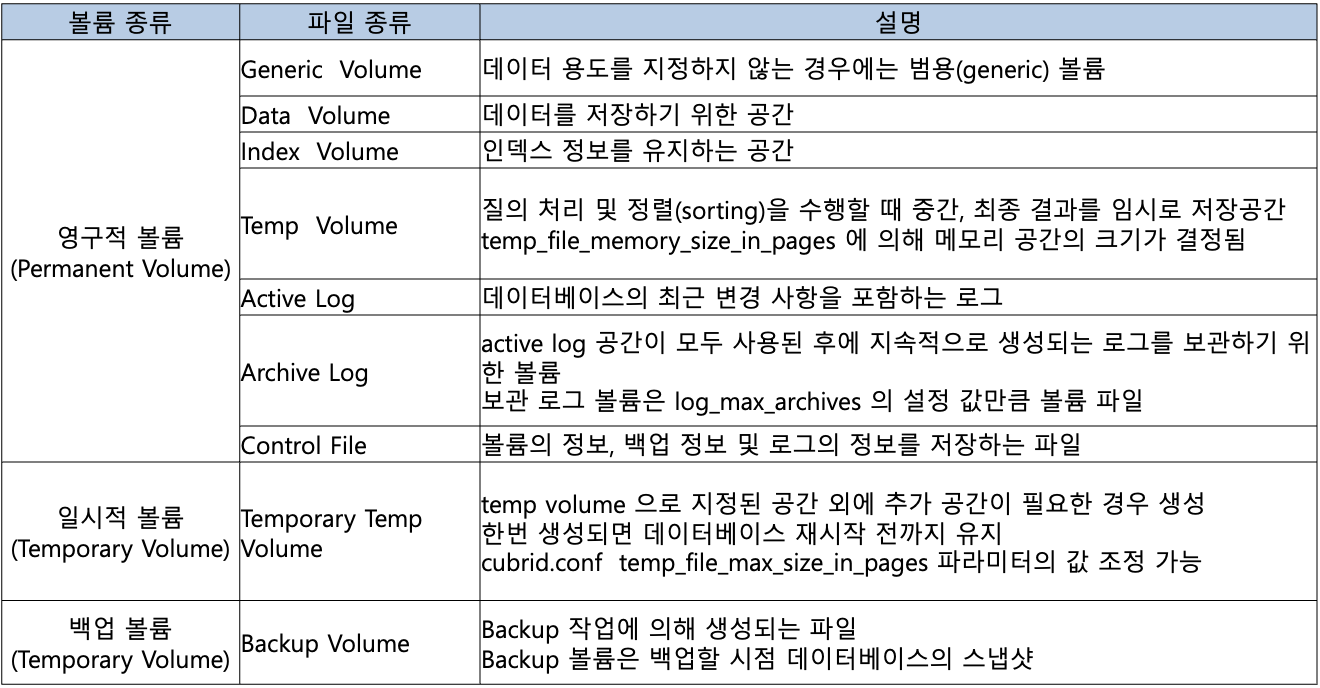
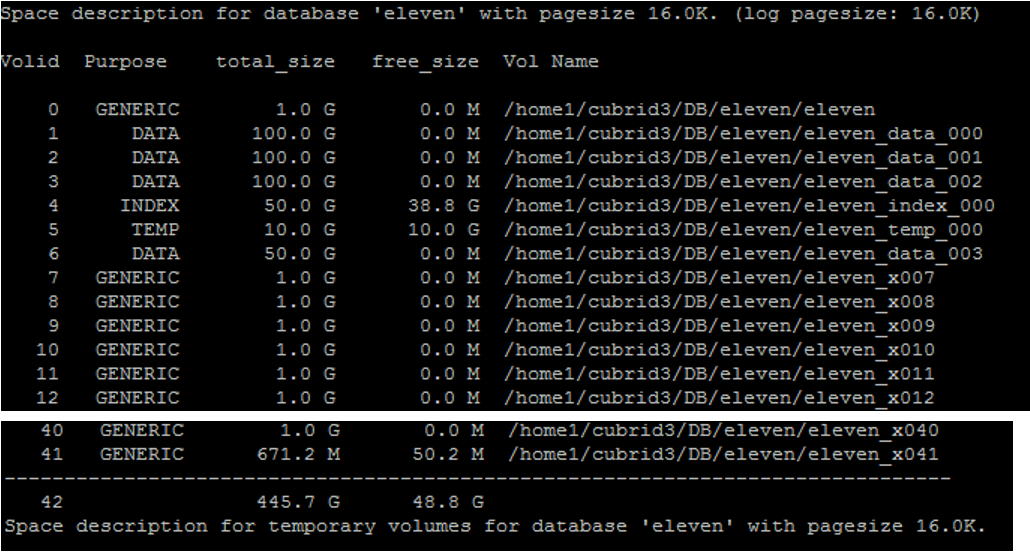
- spacedb : 대상 데이터베이스에 대한 공간을 확인하는 명령으로 데이터베이스 서버가 구동 정지 상태인 경우에만 정상적으로 수행된다.
cubrid spacedb options database_name
cubrid compactdb options database_name- compactdb : 대상 데이터베이스에 대하여 삭제된 데이터에 할당되었던 OID가 재사용될 수 있도록 공간을 정리하는 명령으로서, 데이터베이스가 구동 정지 상태인 경우에만 정상적으로 수행된다.
- compactdb 수행할 때, 꼭, cubrid.conf 에 compactdb_page_reclaim_only=2 로 넣고 SA(서버 프로세스를 구동하지 않고 데이터베이스에 접근하는 독립 모드(standalone)) 모드로 수행
compactdb_page_reclaim_only
- compactdb_page_reclaim_only는 compactdb 유틸리티와 관련된 파라미터로 이미 할당된 저장 영역의 OID를 재사용하기 위하여 이미 삭제된 객체의 저장 영역을 정리하는 유틸리티이다.
- compactdb 유틸리티에 의해 저장 영역이 재정렬되는 작업은 3단계로 구분할 수 있으며, compactdb_page_reclaim_only 파라미터를 통해 재정렬 작업의 단위를 선택할 수 있다.
- 기본값인 0 으로 설정하면 1, 2, 3단계를 모두 수행하므로 데이터 단위, 테이블 단위, 파일 단위로 저장 영역을 재정렬한다.
- 1로 설정하면 1단계를 생략하므로 테이블 및 파일 단위로 저장 영역을 재정렬하고,
- 2로 설정하면 1, 2단계를 생략하므로 파일 단위로만 저장 영역을 재정렬한다.
1단계 : 데이터 단위로 저장 영역을 재정렬한다.
2단계 : 테이블 단위로 저장 영역을 재정렬한다.
3단계 : 파일 단위(heap file)로 저장 영역을 재정렬한다.
참고링크





