협력사, 블록체인, AWS QLDB 이런 거 보다가 2시에 잠..
AWS 자격증 공부할 때 QLDB는 프라이빗한 블록체인이라고 생각했는데 블록체인은 아니었음.
그냥 블록체인 같은 DB였다.
12시에 자는 게 베스트. 적어도 1시에는 자기.
08:09 입실
학습 키워드 복습
머리 속에 있는 거 빠르게 정리해보기
가상메모리
프로세스에게 마치 전체 물리 메모리는 전부 쓰고 있는 것 같은 착각을 줌.
프로세스가 생성되면 가상 메모리가 배정됨.
가상 메모리는 실제 물리 메모리와 같은 크기로 매핑됨.
가상 메모리는 일부는 진짜 물리 메모리에 매핑되지만,
대부분은 스왑 영역이라고 불리는 디스크 영역에 매핑됨.
프로세스는 이 상황에서 자신의 모든 데이터가 물리 메모리에 올라와 있다고 착각 함.
이때 CPU 메모리에 적재된 데이터를 요청하면 다음과 같은 상황이 발생함.
1. 진짜 해당 데이터가 물리 메모리에 있는 경우: 그냥 가져오면 됨.
2. 해당 데이터가 사실은 디스크에 있는 경우: 디스크에서 물리 메모리로 적재 후(스왑 인) CPU로 보냄.
이때 물리 메모리에 있던 다른 프로세스의 데이터 블록이 스왑 영역으로 이동할 수 있음.(스왑 아웃)
CPU는 가상 메모리 주소를 통해 물리 메모리에 접근할 수 있어야 되는데,
이때 가상 메모리 주소와 물리 메모리 주소를 매핑하는 하드웨어가 MMU임.
메모리 단편화
단편화란 '쪼개지는 현상'을 의미한다.
메모리가 쪼개져서 낭비되는 공간이 생기는 것을 메모리 단편화라고 한다.
단편화는 내부 단편화, 내부 단편화 두 가지 종류가 있다.
메모리에 데이터가 적재될 때 특정 블록 단위로 적재된다.
이때 블록이 실제 필요한 메모리 공간보다 커서 블록 내부에 낭비 공간이 생기는 현상을 내부 단편화라고 한다.
메모리는 수시로 할당과 해제를 반복하는데,
이때 남아 있는 공간을 합하면 프로세스를 충분히 적재할 수 있지만,
이 메모리가 쪼개져서 분산되어 있어서 프로세스를 적재할 수 없는 현상을 외부 단편화라고 한다.
내부와 외부 기준을 블록으로 생각하면 내부, 외부 용어 정리가 쉽다.
블록 단위가 일정하면 페이지, 가변적이면 세그먼트이라고 한다.
페이징
페이징은 가상 메모리에 메모리를 적재하는 방식 중 하나이다.
메모리 외부 단편화 문제를 해결하기 위해 블록 단위를 일정 크기(보통 4KB)로 쪼갠 것.
가상 메모리를 쪼갠 것을 페이지, 물리 메모리를 쪼갠 것은 프레임이라고 한다.
일반적으로 페이지와 프레임은 같은 크기이다.
페이지를 통해 메모리 블록은 연속적으로 할당하지 않고 비어 있는 공간에 통일성 있게 적재할 수 있다.
이 경우 외부 단편화 문제를 해결할 수 있으나, 내부 단편화가 발생할 수 있다.
메모리가 불연속적으로 할당되면 프로세스는 메모리를 순차적으로 읽어올 수 없다.
이 문제를 해결하는 게 페이지 테이블이다.
페이지 테이블은 프로세스 생성 시 1개가 생성되며, 실제 메인 메모리에 적재된다.
페이지 테이블의 각 행을 페이지 엔트리라고 하며,
프레임 번호를 비롯해서 유효 비트, 수정 비트 등 다양한 비트 정보가 있다.
프로세스는 페이지테이블의 시작 주소에 오프셋을 이용해서 페이지 엔트리에 접근해
물리 메모리의 주소를 알아낼 수 있다.
이를 통해 물리 메모리에는 불연속 할당되어 있지만
가상 메모리 상에서는 마치 연속 연속 할당 된 것처럼 메모리에 접근할 수 있다.
페이지 테이블에 매핑된 프레임은 실제 물리 메모리에 적재되어 있을 수도 있고,
디스크의 스왑 영역에 적재되어 있을 수도 있다.
만약 페이지 테이블을 통해 데이터 접근을 시도했는데,
이 데이터가 물리 메모리에 적재되어 있으면 페이지 히트, 없으면 페이지 폴트라고 한다.
페이지 히트면 바로 데이터를 가져오면 되지만, 페이지 폴트면 디스크에서 물리 메모리로 스왑 인 한다.
멀티 프로세스 환경에서는 페이지 스왑 인 아웃이 빈번하게 발생할 수 밖에 없다.
페이지 폴트가 과도하게 발생해서 CPU의 전체 성능을 떨어트리는 구간을 스레싱이라고 한다.
프로세스 크기가 커지면 페이지 크기도 커지는데 이는 메인 메모리 낭비로 이어진다.
그래서 페이지를 계층적으로 구성하기도 한다.
즉, 페이지의 페이지를 스왑 영역에 적재하고, 필요할 때 스왑 인 해서 참조한다.
페이징은 메모리에 최소 두 번 접근해야 한다.
페이지 테이블을 접근할 때 1번, 그 후 원래 목적대로 메모리에 접근하는데 1번.
그래서 TLB(변환 색인 버퍼) 캐시에 페이지 테이블을 캐싱한다.
접근하려는 페이지 테이블 정보가 캐시에 있으면(TLB 히트) 물리 메모리에 1회만 접근하고,
없으면(TLB 미스) 그때 물리 메모리에서 페이지 테이블 정보를 가지고 온다.
가상 메모리 실제 설치된 물리 메모리보다 큰 크기를 가질 수 있으며 크기는 운영체제 수준에서 관리된다.
동적메모리 할당(힙, sbrk, malloc, free)
가상 메모리로 생성되는 메모리는 다음과 같은 영역으로 나뉜다.
커널 영역, 스택 영역, 힙 영역, 데이터 영역(.BSS, .DATA), 코드 영역
힙은 런타임 중에 동적으로 메모리가 할당되는 영역이고,
스택은 함수 호출 시 스택 프레임이 쌓이는 영역이다.
힙은 낮은 주소에서 높은 주소로 할당되며,
스택은 높은 주소에서 낮은 주소로 할당된다.
brk는 메모리 할당의 끝을 결정하는 시스템 콜, sbrk는 그 크기를 증감하는 시스템 콜이다.
malloc, free 는 c언어에서 사용자 수준으로 제공하는 메모리 할당/해제 함수이다.
malloc, free는 내부적으로 brk, sbrk와 같은 시스템 콜을 호출하여 메모리를 제어한다.
메모리 할당 정책
연속 할당 방식에서 메모리 할당하는 방법이다.
-
최초 할당
스캔 시 비어있는 공간에 먼저 할당한다. -
최적 적합
전체 스캔 후 프로세스가 적재될 수 있는 가장 작은 공간에 할당한다. -
최악 적합
전체 스캔 후 프로세스가 적재될 수 있는 가장 큰 공간에 할당한다.
이 중에서 가장 효율이 좋은 것은 일반적으로 최적 적합이다.
암시적 해제 리스트 & 명시적 해제 리스트
현재 사용 가능한 메모리 블록을 추적하는 방법이다.
동적으로 메모리를 할당 받으면 딱 그 공간만 할당되는게 아니라
여러 메타 데이터를 포함한 메모리 블록을 할당 받게 된다.
메모리를 할당하거나 해제하면 해당 메모리 블록에 있는 할당 비트로 할당 여부를 제어할 수 있다.
이때 현재 할당 가능한 메모리 블록을 관리하는 두 가지 방법이 암시적 해제 리스트, 명시적 해제 리스트이다.
암시적 해제 리스트는 별도의 리스트를 관리하지 않는다는 의미로,
메모리 블록을 하나씩 스캔하면서 할당 가능한(프리한 상태의) 메모리 블록을 관리한다.
명시적 해제 리스트는 메타 데이터내에 앞, 뒤 포인터로 이미 해제된 메모리 블록들을 참조하고 있으며,
이를 통해 명시적인 연결 리스트 방식으로 해제 리스트를 관리한다.
명시적 해제 리스트는 별도 자료 구조 관리에 오버헤드가 발생한다.
Demand zero memory
메모리 할당시 lazy한 방식으로 이루어진다.
프로세스가 메모리 할당을 요청하면 운영체제는 즉시 메모리를 할당하지 않고 메모리는 할당하는 척만 한다.
이후 실제 해당 메모리에 접근(읽기/쓰기)가 발생하면 운영체제는 그제서야 해당 메모리 공간을 0으로 초기화하고 할당한다.
이러한 방식은 리소스를 최대한 늦게 지연시키면서 오버헤드를 줄일 수 있다.
실제로 할당 요청 후 메모리를 사용하지 않는 경우가 생긴다면 lazy한 방식을 오버헤드를 줄일 수 있다.
이렇게 지연 초기화 방식으로 메모리를 할당하는 것을 Demand zero memory라고 한다.
시스템 콜
운영체제는 특별한 인스트럭션을 사용자가 직접 호출하지 못하게 하고, 커널 수준에서만 호출할 수 있게 관리한다. 이때 커널에게 이러한 특별한 인스트럭션을 실행해달라고 요청하는 것을 시스템 콜이라고 한다.
즉, 사용자는 하드웨어 수준에 직접 요청을 할 수 없고, 커널을 통해 시스템 콜이라는 요청을 통해 특별한 인스트럭션을 실행할 수 있다.
DMA
CPU 중재 없이 메모리와 디스크 사이의 입출력을 제어하는 물리적 장치이다.
DMA로 인해 CPU는 메모리와 디스크 입출력 대신 다른 프로세스를 처리할 수 있다.
이더넷
현대 컴퓨터 네트워크 프로토콜이다. 인터넷이 어플리케이션 계층의 프로토콜이라면
이더넷은 물리, 데이터 링크 계층의 프로토콜이다.
어떤 케이블을 쓰는지, 어떤 연결 장치를 쓰는지, 실제 케이블 통신이 진행될 때 어떤 방식으로 데이터 송수신을 하는지에 관한 규약이다.
이더넷 물리 장치로는 다음과 같다.
- 이더넷 케이블(UTP, STP, 광섬유)
- 이더넷 스위치, 허브, 라우터
- 이더넷 인터페이스 카드
CSAPP 9장 다시 훑어보기
할당기
명시적 할당기
대표적으로 malloc 패키지
묵시적 할당기
가비지 컬렉터: 자동으로 사용하지 않은 할당된 블록을 반환하는 작업
책이 더 잘 읽힌다!
키워드를 공부하고 CSAPP을 다시 보니 훨씬 잘 읽힌다!
내용이 하나하나 이해가 됨!
가상 메모리는 무한한 공간인가?
아님! CSAPP p.813
"초보 프로그래머들은 종종 가상메모리가 무한 자원이라고 잘못 생각한다. 사실, 한 시스템에서 모든 프로세스에 의해 할당된 가상메모리의 양은 디스크 내의 스왑 공간의 양에 의해 제한된다."
메모리 할당의 진짜 의미



이거 진짠가? GPT 어디까지 믿어야 되는 건지..
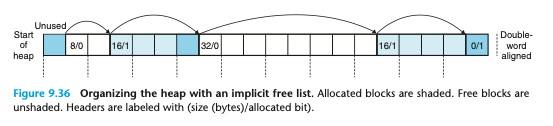
묵시적 가용 리스트 이해하기

(힙의 시작과 끝은 사용되지 않는다. 특별한 용도로 사용: 가드 블록, 힙 메타데이터 저장)
배열 방식으로 모든 블록을 순회하며 가용 블록을 찾는다.
(힙 영역에 블록이 존재함.)
이때 리스트 순회를 종료하기 위한 마지막에 종료 블록이 필요하다.
헤더는 1워드를 갖는다.
나머지 페이로드는 갖는다.
Blocksize에 할당한 블록은 1을 더하면 헤더 값이 나온다.(할당 비트1)
이 그림이 이해되지 않았음
원래 블록은 경계에 맞춰야 되는데 경계 중간부터 시작해서 경계 중간에서 끝나는거지?
아님! malloc이 반환하는 주소는 헤더가 아니라 페이로드 부분임.
페이로드는 기준으로 보면 할당된 블록은 경계에서 시작해서 경계에서 끝나고 있음.
하지만 헤더를 포함한 전체 메모리 블록의 크기는 메모리 경계에 맞춰야 한다.
메모리 할당 계산하기
(1워드 4바이트 기준)
- malloc으로 힙 영역 메모리 할당하면 블록이 생성된다.
- 이 블록은 1워드의 헤더와, 요청한 만큼의 페이로드가 생기고, 나머지는 정렬 제한 조건에 따른 패딩이 생긴다. 이 경우 블록 크기는 항상 8의 배수이다.
- malloc은 헤더 부분이 아니라 페이로드가 시작되는 지점의 주소를 반환한다.
- 탐색 시 현재 주소에서 블록 크기만큼 더하면 다음 블록으로 이동할 수 있다.
메모리 할당기는 복잡한 메모리 관리 작업을 추상화하고,
프로그래머에게는 데이터를 저장할 수 있는 메모리의 "깨끗한 부분", 즉 페이로드를 제공한다.
경계 태그
블록의 푸터(=경계 태그)
푸터는 헤더를 복사한 것이다.
푸터가 있으면 할당기는 시작 위치와 이전 블록의 상태를 푸터를 통해 할 수 있다.
푸터는 항상 현재 블록 시작 부분에서 한 워드 뒤에 있다.
푸터가 없으면 이전 블록에 대한 정보를 알기 위해 이전 블록의 헤더까지 일일이 순차적으로
탐색해야 해서 오버헤드가 발생한다.
헤더만으로는 할당된 블록의 끝부분을 인식하는 건 어렵다. 메모리 누수 등의 오류 감지가 어렵다.
경계 태그의 단점은 아주 작은 블록 조각들이(1워드 크기) 많이 할당될 경우,
헤더와 푸터가 메모리 블록의 절반을 차지하게 된다는 것이다.
연습 문제 9.7 복기
정렬을 바이트와 헷갈렸음.
1워드가 4바이트인 경우 최소 페이로드는 4바이트가 할당되고,
헤더와 푸터도 각각 1워드가 할당된다.
이때 정렬 요건이 워드이면 4의 배수로 올림해야 하고,
더블워드이면 9의 배수로 올림하면 된다.
즉, 전체 블록의 크기가 정렬 조건에 맞아야 한다.
스터디
계층적 페이지 테이블의 메커니즘 추가 학습
페이지 테이블은 생각보다 큼.
모든 페이지 엔트리를 페이지 테이블에 담는 건 메모리 낭비
페이지 테이블 자체를 페이징한다.
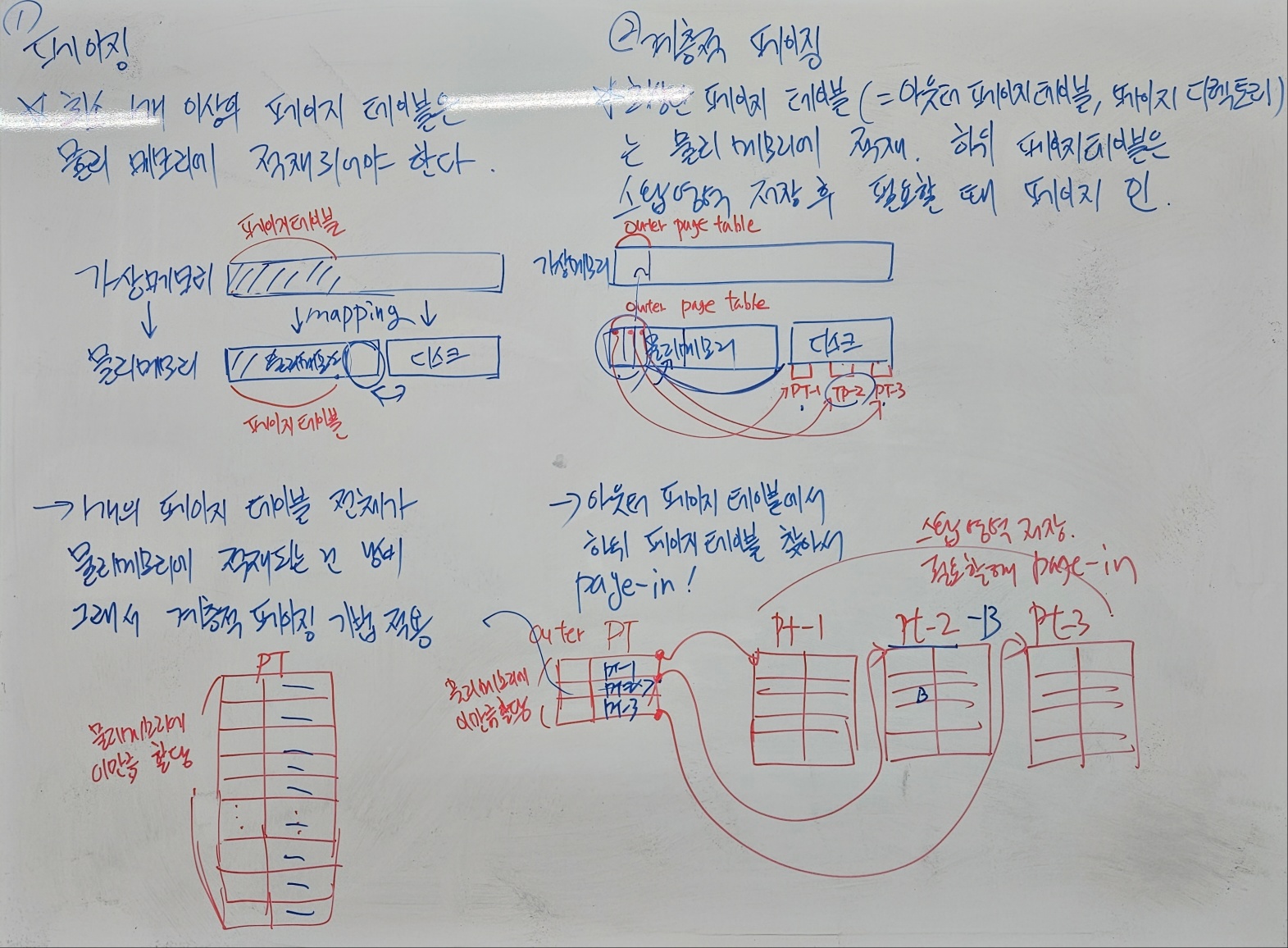
계층을 더 많이 두면 개별 페이지 테이블 크기는 작아지니까, 공간 효율성은 올라가고,
페이지 테이블이 작아질 수록 페이지 인에 따른 오버에드가 줄어든다.
대신 계층이 깊어지면 페이지 폴트가 여러 번 발생한다.
이 문제를 TLB 레지스터에 페이지 테이블 엔트리 캐싱 방식으로 해결한다.
메모리 할당 기법과 페이징 관계 추가 학습
모든 건 스왑 영역에서 물리 메모리로 올라올 때 발생함.
연속 할당으로 프로세스 전체가 올라올 때 비어있는 블록을 찾으면서
최초 적합, next 적합, 최적 적합, 최악 적합 방식으로 스왑 인 아웃을 통해 메모리 블록에 할당함.
하지만 결국 내부 단편화가 발생함.
그래서 등장한 게 불연속 할당 기법이고 대표적인 게 페이징.
페이지가 스왑 인 아웃 하는 걸 페이지 인 아웃이라고 함.
malloc-lap
https://csapp.cs.cmu.edu/3e/malloclab.pdf
이럴려고 수능 영어 공부하는군..
(대충 18년 전 이야기)
구현 과제 분석
- memlib.c 패키지를 활용
- malloc 패키지와 무관한 할당기를 만드는 것이 목표!
memlib.c 분석
mem_init()
힙에 가용한 가상메모리를 큰 더블 워드로 정렬된 바이트의 배열로 모델
(경계 정렬)
mem_heap
힙 영역 시작 주소
mem_brk
힙 영역의 끝, 힙의 break
mem_brk 다음의 바이트는 미할당 가상 메모리
mem_sbrk()
할당기는 이 함수를 통해서 추가적인 힙 메모리 요청
시스템 콜 sbrk() 함수와 동일하며, 일종의 래핑 함수
(단, 축소 명령어는 거부됨)
mm.c 분석
우선 기본 상수와 매크로를 살펴본다.
WSIZE
워드 사이즈를 지정한다.
DSIZE
더블워드 사이즈를 지정한다.
CHUNKSIZE
초기 가용 블록 및 힙 확장을 위한 기본 크기
PACK
크기와 할당 비트를 통합해서 헤더와 풋터에 저장할 수 있는 값 리턴
GET
인자 p가 참조하는 워드 읽어서 리턴
인자 p는 보통 (void*) 포인터 => 역참조 불가 => 캐스팅 중요
PUT
인자 p가 참조하는 워드에 val을 저장
GET_SIZE
주소 p에 있는 헤더(또는 푸터)의 size를 리턴
GET_ALLOC
주소 p에 있는 할당 비트 리턴
HDRP
블록 포인터 bp의 블록 헤더 포인터 리턴
FTRP
블록 포인터 bp의 푸터 헤더 포인터 리턴
NEXT_BLKP
다음 블록 포인터
PREV_BLKP
이전 블록 포인터
코드 구현
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
0x7은 비트로 000...111이다. ~0x7은 비트 반전이으로 이진수로 111...000이 된다.
이 결과를 비트 AND 연산을 하면 마지막 비트 3자리가 낮은 비트 3자리가 무조건 0이 된다.
이렇게 하면 결과를 가장 가까운 8의 배수로 만들 수 있다.
-1을 하지 않으면 가령 size가 8인 경우는 16바이트를 할당해 버린다.
즉, size에 무관하게 최종 덧셈 결과를 8의 배수로 버림하려면 -1이 필요하다.
코드 구현 전에 관련 키워드와 개념들 공부하고 구현했더니 책에 있는 코드가 잘 읽힌다!
우선 기본적이 기능 구현해보고, 기능 개선 해보기!
오늘 백코치님의 조언
"프로그래머의 본분은 코딩해서 결과물을 만들어내는 것이지 책 읽는 게 아니다."
컴퓨터 과학을 탐구하고 책의 깊은 내용을 탐독하는 건 학문적으로 즐거운 일이지만,
프로그래머는 결국 돌아가는 프로그램을 만들어야 한다.
(김코치님이 자주 강조하시는 것도 '좋은 프로그램은 우선 돌아가는 프로그램이다')
컴퓨터 과학 책을 탐독하는 게 재미있다면 과학자나 학자의 길을 걸어야 하지 않을까?
프로그래머로서의 학습의 방향을 잡아주는 유익한 조언이었음.
